What is Qwen3-Omni?
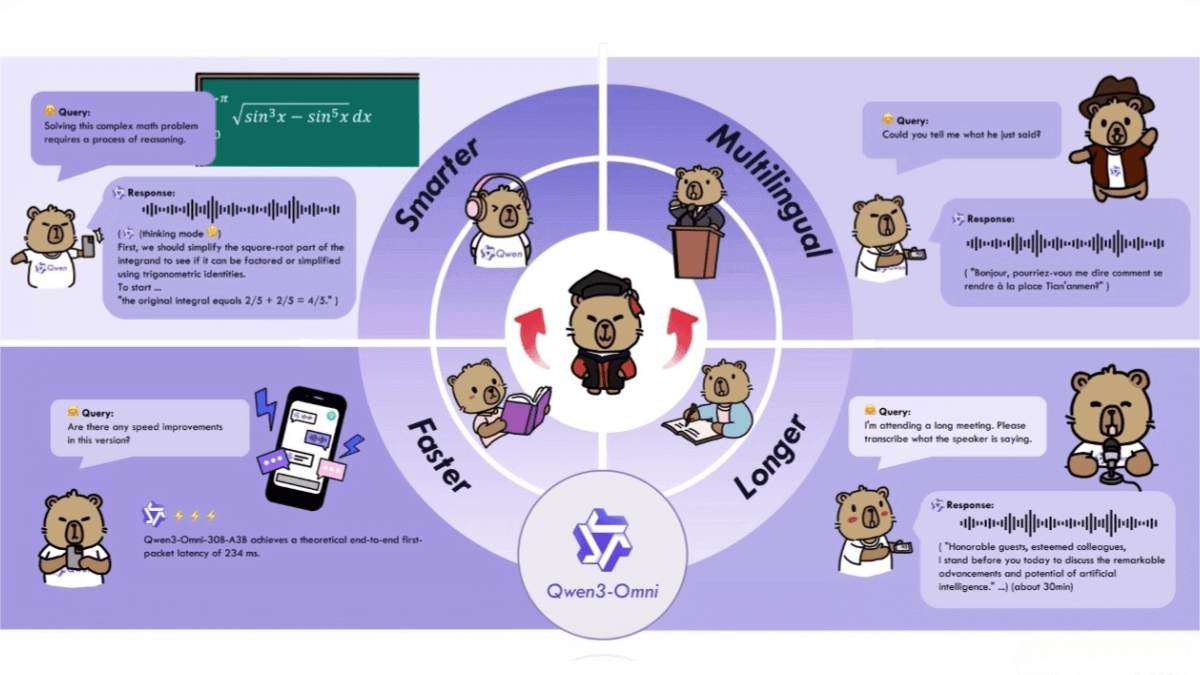
Qwen3-Omni is the industry’s first native end-to-end multimodal AI model launched by Alibaba’s Tongyi team. It can seamlessly handle multiple modalities such as text, images, audio, and video. The model achieves state-of-the-art (SOTA) performance in 22 out of 36 audio and audiovisual benchmark tests and supports text processing in 119 languages, demonstrating global language capabilities. With latency as low as 211 milliseconds, high controllability, customizable system prompts, and powerful built-in tool-calling functions, Qwen3-Omni offers high efficiency and flexibility. The Qwen team has open-sourced several versions, including Qwen3-Omni-30B-A3B-Instruct, Qwen3-Omni-30B-A3B-Thinking, and Qwen3-Omni-30B-A3B-Captioner, promoting technological development and application innovation. The model is now available on the Qwen Chat model experience platform.

Key Features of Qwen3-Omni
Native Multimodal: Qwen3-Omni is a native multimodal large model, pretrained across modalities without intelligence degradation.
Powerful Performance: Achieves 32 open-source SOTA results and 22 overall SOTA results across 36 audio and audiovisual benchmarks, surpassing closed-source models like Gemini-2.5-Pro, Seed-ASR, and GPT-4o-Transcribe. Image and text performance also reach SOTA levels among models of similar size.
Multilingual Support: Handles 119 text languages, 19 spoken language understanding languages, and 10 spoken language generation languages.
Faster Response: End-to-end audio conversation latency as low as 211ms, and video conversation latency as low as 507ms.
Long Audio Understanding: Supports understanding of audio up to 30 minutes in length.
Personalization: Fully customizable system prompts allow modification of response style, persona, and more.
Tool Calling: Supports function calls for efficient integration with external tools and services.
Open-Source General Audio Captioner: Qwen3-Omni-30B-A3B-Captioner provides a detailed, low-hallucination general audio captioning model, filling a gap in the open-source community.
Technical Principles of Qwen3-Omni
Thinker-Talker Architecture
-
Thinker: Handles text generation, processes text input, outputs high-level semantic representations, and provides foundational information for subsequent speech generation.
-
Talker: Focuses on streaming speech token generation. Using semantic representations from Thinker, it predicts multi-codebook sequences autoregressively for low-latency, frame-by-frame streaming speech generation.
-
MTP Module: During decoding, the MTP module outputs residual codebooks for the current frame, which are synthesized into audio waveforms by the Code2Wav module, enabling efficient streaming audio generation.
Innovative Architecture Design
-
AuT Audio Encoder: Trained on 20 million hours of audio data, providing strong general audio representation capability for audio tasks.
-
MoE Architecture: Both Thinker and Talker use Mixture-of-Experts (MoE) architecture, supporting high-concurrency processing and fast inference, significantly improving multi-task efficiency.
-
Multi-Codebook Technology: Talker’s multi-codebook autoregressive approach generates one codec frame per step, while the MTP module outputs remaining residual codebooks, optimizing efficiency and quality in speech generation.
-
No Intelligence Degradation Across Modalities: During text pretraining, the model mixes single-modality and cross-modality data. This ensures each modality’s performance is comparable to single-modality models while enhancing cross-modal capability. Qwen3-Omni performs exceptionally in speech recognition and instruction-following tasks, rivaling top models like Gemini-2.5-Pro for accurate voice command understanding and smooth voice interaction.
Real-Time Audio and Audio-Video Interaction: The entire pipeline—including AuT audio encoding, Thinker text processing, Talker speech generation, and Code2Wav audio synthesis—is fully streaming, allowing the first token to be directly decoded into audio for efficient real-time interaction.
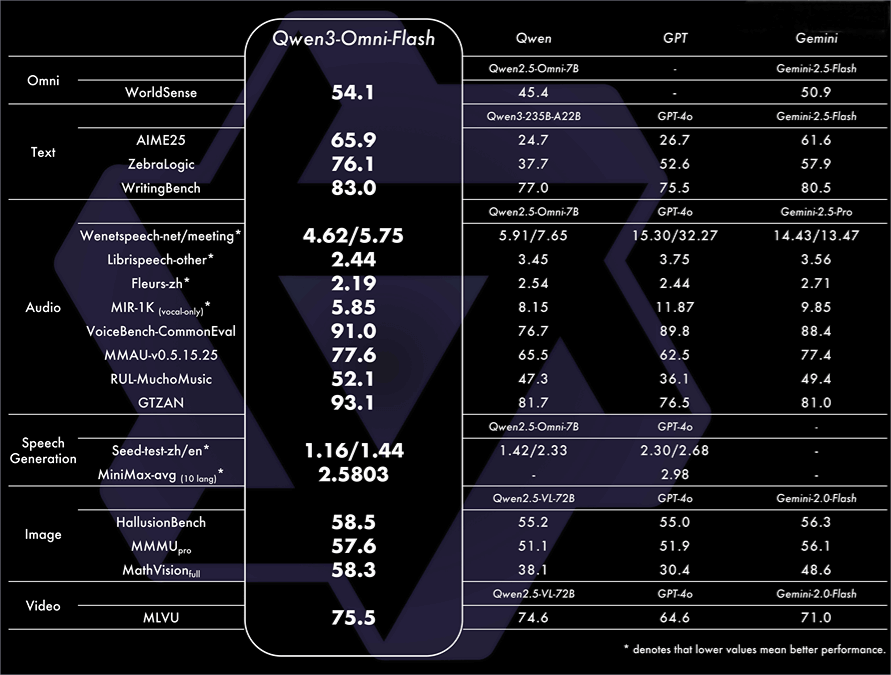
Performance
-
On single-modality tasks, Qwen3-Omni performs on par with Qwen’s single-modality models of similar size, with outstanding results in audio tasks.
-
In 36 audio-video benchmark tests, it achieves the best open-source performance in 32 tasks and SOTA in 22 tasks, surpassing powerful closed-source models like Gemini-2.5-Pro, Seed-ASR, and GPT-4o-Transcribe.
Project Links
Application Scenarios
-
Content Creation: Generates high-quality text, images, audio, and video content, providing rich creative material and boosting productivity.
-
Intelligent Customer Service: Supports multilingual text and voice interaction for fast, accurate understanding of user queries and solutions.
-
Education: Generates personalized learning materials and interactive content such as audio explanations and image examples to meet diverse student needs.
-
Medical Assistance: Processes multimodal medical data such as medical imaging and voice records to assist diagnosis and treatment planning.
-
Multimedia Entertainment: Creates music, videos, and other multimedia content for personalized entertainment experiences.