Hugging Face has released a detailed “Small Model Training Guide.”
The “Small Model Training Guide: Core Principles for Building Top-Tier Language Models,” released by the HuggingFace team, is a 200+ page mega-technical blog that systematically shares end-to-end experience in training advanced LLMs.
The guide is built on the team’s complete real-world experience training SmolLM3, a 3B-parameter model, using 384 H100 GPUs, offering developers a precious “panoramic map” for large-scale model training.
What makes the guide truly valuable is its extreme honesty and practicality. Unlike academic papers that only show polished results, the guide thoroughly documents the “messy realities” of training—late-night debugging of dataloaders, panic from sudden unexplained loss spikes, tiny tensor parallelism bugs breaking training, and the troubleshooting methods behind them. It is essentially a “pitfall-avoidance bible” for LLM training.

Training Compass – Deep Thinking Before Any Decision
Before spending millions of compute resources, the guide mandates strict self-examination. The quality of decisions made at this stage directly determines the project’s outcome.
A deep analysis of bad reasons to train
The guide uses a detailed cost modeling framework to show that actual costs—data collection + cleaning, model architecture design, infrastructure setup, and production deployment—far exceed the “unused compute” value people often imagine.
For a typical 3B-model project:
-
Data preparation alone requires 10 person-months
-
Infrastructure needs a dedicated ops team
-
Model optimization and deployment are bottomless pits
The trap of “training because others are doing it” is validated through 10 real failure cases.
One example: A company attempted to train its own model after seeing ChatGPT’s success, but without a clear application scenario. Although the final model looked good on benchmarks, it generated zero business value.
The guide provides a risk assessment checklist with 37 items across technical, market, and talent risks.
Strict standards for deciding when training is justified
For research needs, the guide distinguishes:
-
Exploratory research (e.g., new attention mechanisms) → requires large trial-and-error
-
Confirmatory research (e.g., optimizer improvements) → requires rigorous controlled experiments
For production needs, domain specialization is quantified.
Example: In the legal field, only when performance gaps exceed 20% on tasks like statute understanding or case reasoning should custom training be considered.
Experimental Validation – Scientific Methods Driving Decisions
The guide builds a full experimental methodology, ensuring every decision is grounded in data. The core is systematic ablation studies that turn subjective intuition into objective evidence.
Real-world engineering of ablations
Baseline selection is a complex multi-dimensional decision.
The team compared Llama, Qwen, and Gemma under identical settings, assessing not just final metrics but:
-
Training stability
-
Scalability
-
Inference efficiency
For example, some architectures show significantly reduced stability when scaling from 1B to 3B—knowledge essential in early planning.
The guide provides resource configuration templates:
-
For architecture experiments → Full-size model trained on 100B tokens
-
For data recipe experiments → Target-size model + parallel testing across data mixtures
Each experiment includes key KPIs such as MMLU, GSM8K accuracy, throughput, and memory efficiency.
Innovations in evaluation methodology
Traditional evaluation is useless early in training.
The guide introduces an early-training probe evaluation, which predicts final performance when only 10% of data is trained.
Probes include:
-
Vocabulary mastery
-
Grammar understanding
-
Basic reasoning ability
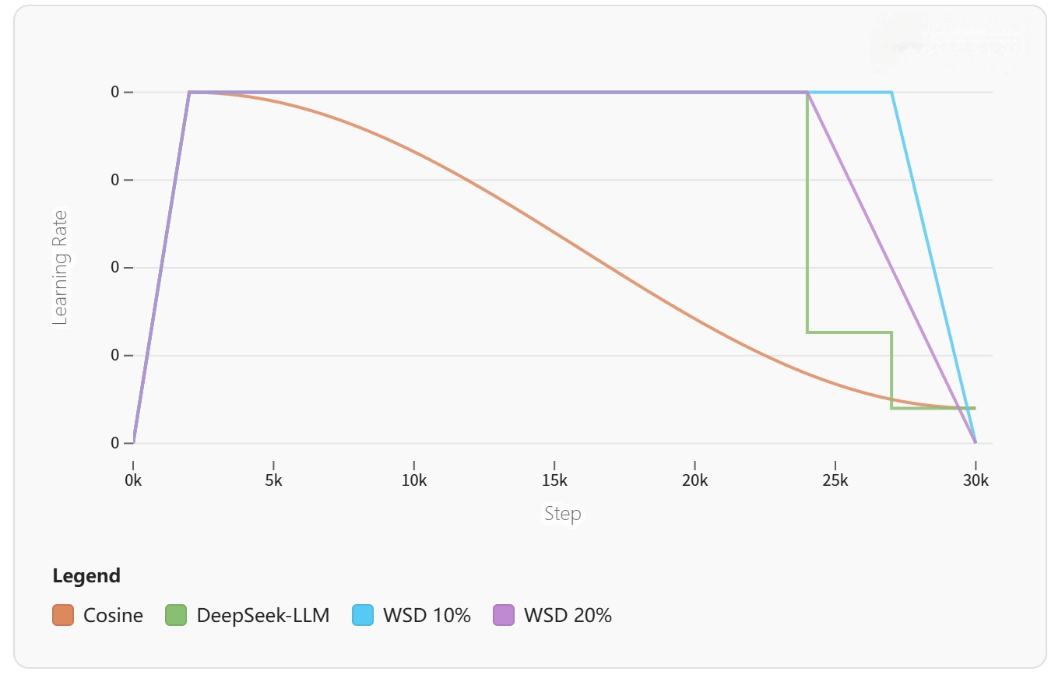
Architecture Design – Evidence-Based Component Selection
Deep engineering analysis of attention mechanisms
During SmolLM3 development, three attention types were rigorously compared.
MHA has high expressivity but becomes a memory bottleneck.
For sequence length 8192:
-
MHA KV-cache: 4.2 GB
-
GQA KV-cache: 1.1 GB
GQA experiments show that 8 groups offer the best balance of quality and inference speed, while preserving head diversity (local vs global patterns).
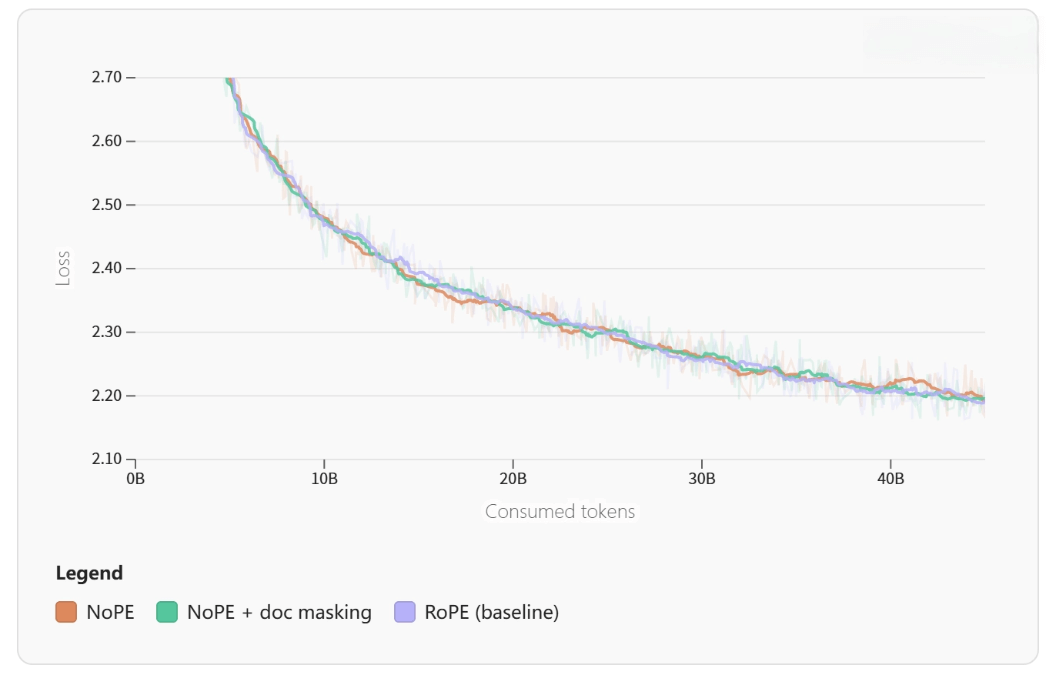
Long-context reasoning as a system problem
Document-level masking is not just a trick—without it, models learn false cross-document associations, hurting long-context performance.
With document-level masking, long-document QA accuracy improved by 15.3%.
Position encoding is a story of evolution:
-
RoPE → strong at short range, collapses at long range
-
Linear RoPE, YaRN, NoPE were tested
-
Final solution: hybrid strategy
-
RoPE in lower layers
-
NoPE in higher layers
-
This preserved short-range strength and improved extrapolation.
Data Management – The Decisive Factor of Model Quality
The science and practice of data recipes
Multi-stage training is grounded in learning dynamics:
-
Early stage → diverse data to build broad capabilities
-
Late stage → high-quality domain data to break capability plateaus
Quality control uses a full pipeline:
-
Dedup: exact match + semantic similarity via MinHash/SimHash
-
Filtering: from character-level checks to semantic quality evaluation
Novel data experimentation methodology
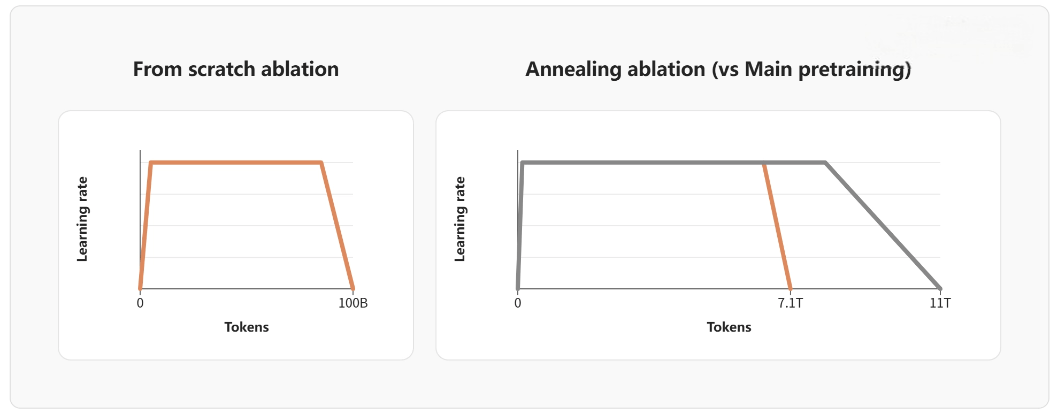
Zero-from-scratch ablations reflect engineering wisdom:
Using target-size models is essential.
Small-model-valid recipes often fail on larger models due to different sensitivity to data distributions.
Annealing (curriculum change) depends on monitoring validation trends:
When math ability plateaus, for example, that signals it’s time to inject high-quality math data.
Training Marathon – Long-Cycle Execution as a System Project
Military-grade pre-training preparation
Infrastructure validation includes:
-
72-hour stress testing of every GPU
-
Multi-pattern network performance tests (not just bandwidth)
-
Layered monitoring system:
-
Hardware (temperature, power, memory)
-
System (throughput, dataloader speed)
-
Algorithm (loss curves, eval metrics)
-
Training issue response framework
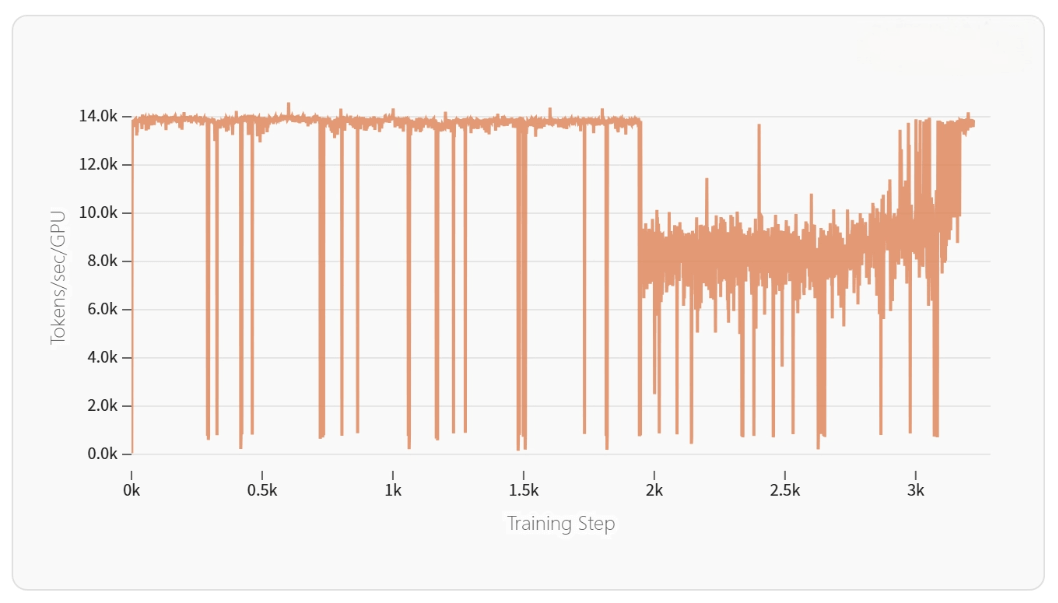
Throughput drop diagnostics follow a structured process:
-
Dataloader speed
-
Network communication
-
Kernel performance
The team built a knowledge base of historical anomaly patterns.
Loss anomalies require deep expertise:
-
Sudden spikes → data issues
-
Slow rise → LR too high
-
Long plateaus → strategy adjustment needed
Each pattern includes actionable remedies.
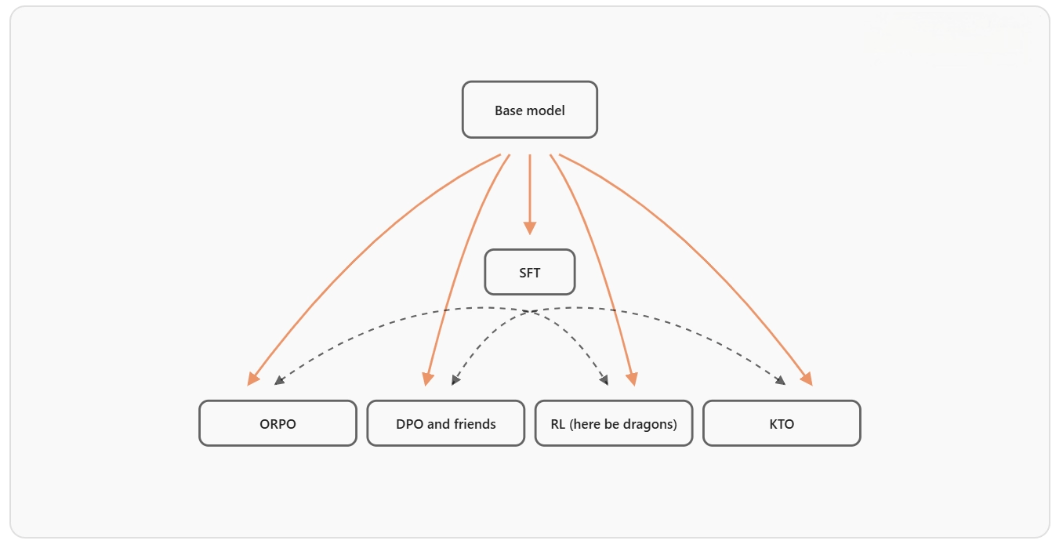
Post-Training – Refining the Base Model Into a Product
Quantitative framework for post-training decisions
Need assessment becomes fully quantified:
-
Measure base model performance across tasks
-
Calculate gaps
-
Prioritize SFT / DPO resources based on ROI
Cost–benefit modeling includes:
-
Compute cost
-
Time cost
-
Opportunity cost
-
Expected performance improvement + business value
Engineering best practices
SFT data recipe design requires balance:
Diverse tasks but no overrepresented categories.
Team uses task-layered sampling.
For preference learning, extensive comparisons show:
-
DPO → stable for simple tasks
-
Complex reasoning → requires finer reward design
A reward-model evaluation framework predicts RM performance before large-scale training.
Infrastructure – The Engineering Backbone of Scale Training
Deep optimization in hardware architecture
GPU cluster design includes:
-
Compute nodes (H100)
-
Preprocessing + checkpoint nodes
-
Hybrid network topology: InfiniBand + Ethernet
Storage architecture:
-
Distributed FS for training data
-
High-performance object storage for checkpoints
-
Time-series DBs for logs
Intelligent monitoring
Machine-learning-based failure prediction:
-
GPU temperature trends → fan failure
-
Packet loss patterns → NIC degradation
Resource estimation includes real-world overhead:
Actual training time is 20–30% longer than theoretical FLOPs.
SmolLM3 full case study
Cluster prep started 2 weeks early:
72-hour stress tests, 1-week network tuning, storage optimizations.
During training:
-
187 anomalies detected
-
12 auto-recovered
-
5 required manual intervention
-
Worst case: intermittent NVLink failure → task auto-migration
Conclusion
The guide concludes that building high-performance LLMs relies on systematic methodology, not technology stacking.
From the SmolLM3 experience, the team extracted core principles:
-
Use the Training Compass for scientific decision-making
-
Validate every change with controlled experiments
-
Change only one variable at a time
-
Stay use-case driven and pragmatic
-
Establish robust ablation workflows during pre-training
-
Prioritize data balance and fine-grained tuning for post-training
The authors encourage developers to deepen understanding through hands-on experimentation, code reading, and staying current with frontier research.
Every great model is forged through countless nights of debugging—this is the true spirit of open scientific exploration.
Original link:
https://huggingface.co/spaces/HuggingFaceTB/smol-training-playbook
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...