Omnilingual ASR — the automatic speech recognition system launched by Meta AI
What is Omnilingual ASR?
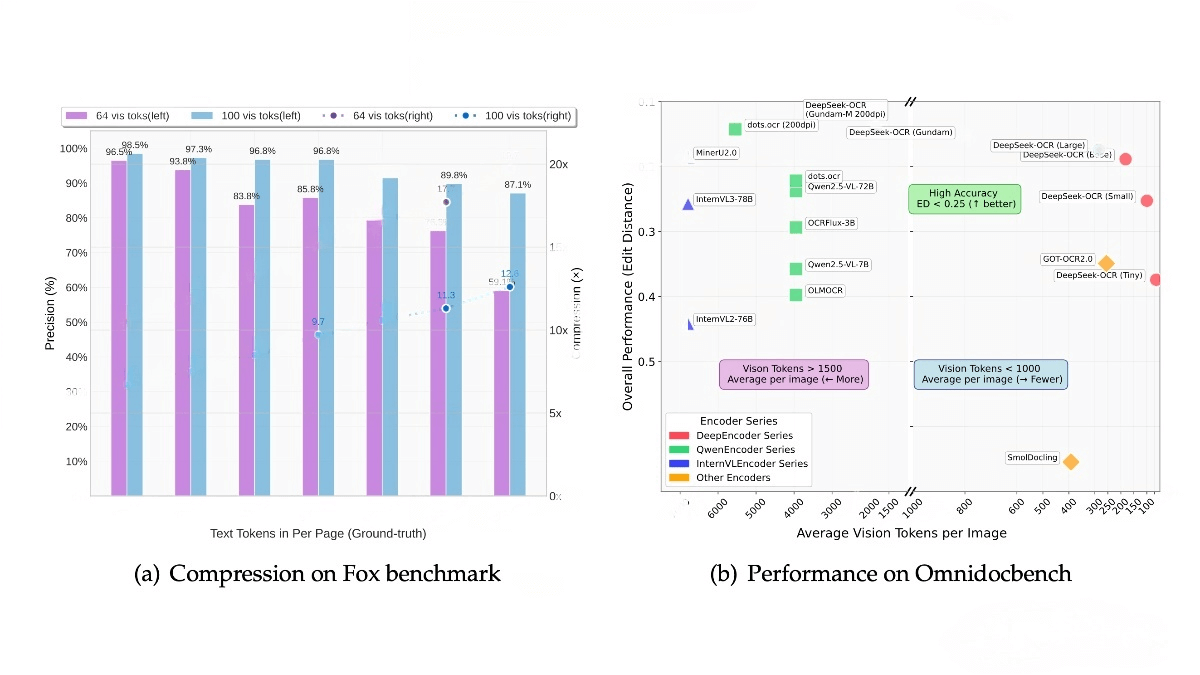
Omnilingual ASR is an automatic speech recognition system launched by Meta AI, supporting more than 1,600 languages, including 500 low-resource languages. By scaling the wav2vec 2.0 encoder to 7 billion parameters and introducing two types of decoders, the system achieves outstanding performance, with 78% of languages reaching a character error rate (CER) below 10%.
The Omnilingual ASR framework is community-driven—users can extend the system to new languages by providing only a small number of audio–text samples. Meta has also open-sourced the Omnilingual ASR Corpus and the new Omnilingual wav2vec 2.0 self-supervised multilingual speech representation model, accelerating global speech technology and promoting linguistic equality and cultural exchange.
Key Features of Omnilingual ASR
-
Multilingual speech transcription:
Converts speech to text in more than 1,600 languages, including many low-resource and previously unsupported languages. -
Community extensibility:
Users can add new languages by supplying a small amount of audio and text samples—no large datasets or specialized expertise required. -
High performance and low error rate:
Achieves CER below 10% for 78% of supported languages, reaching industry-leading accuracy. -
Multiple model options:
Offers models from lightweight 300M versions to powerful 7B versions, suitable for different devices and use cases. -
Open source and data sharing:
Provides open access to the Omnilingual wav2vec 2.0 model and the Omnilingual ASR Corpus to support developers and researchers worldwide.
Technical Principles Behind Omnilingual ASR
-
wav2vec 2.0 scaling:
Expands the wav2vec 2.0 encoder to 7 billion parameters, enabling extraction of rich multilingual semantic representations directly from raw audio. -
Dual-decoder architecture:
Uses two decoders—CTC (Connectionist Temporal Classification) and a Transformer-based decoder inspired by LLMs—to significantly improve performance on long-tail languages. -
In-context learning capability:
Inspired by large language models, the system can quickly adapt to new languages using only a few in-context samples, without large-scale retraining. -
Large-scale multilingual dataset:
The training corpus integrates public datasets and community-contributed audio, covering many low-resource languages to give the model broad linguistic grounding.
Project Links
-
Official website: https://ai.meta.com/blog/omnilingual-asr-advancing-automatic-speech-recognition/
-
GitHub repository: https://github.com/facebookresearch/omnilingual-asr
-
HuggingFace dataset: https://huggingface.co/datasets/facebook/omnilingual-asr-corpus
-
Technical paper: https://ai.meta.com/research/publications/omnilingual-asr-open-source-multilingual-speech-recognition-for-1600-languages/
Application Scenarios of Omnilingual ASR
-
Cross-lingual communication:
Enables real-time voice communication across different languages, removing language barriers and fostering global collaboration and cultural exchange. -
Low-resource language preservation:
Provides high-quality transcription tools for endangered or low-resource languages, supporting preservation and revitalization efforts. -
Education and learning:
Assists multilingual teaching, pronunciation practice, and real-time translation for language learners. -
Voice assistant expansion:
Extends language support for intelligent voice assistants, enabling them to serve a broader global user base. -
Content creation and media:
Automatically transcribes multilingual audio and video content, improving productivity and supporting multilingual subtitle generation.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...