How to Do Anything with AI is a cutting-edge course offered by the Massachusetts Institute of Technology (MIT), deeply exploring artificial intelligence technologies and their applications across diverse real-world data modalities. The course focuses on modern deep learning and foundational models, covering multiple modalities such as language, vision, audio, sensor data, and medical data. Through lectures, readings, discussions, and research projects, students develop critical thinking, gain insights into the latest AI technological advancements, and master the principles of multimodal AI. The course emphasizes theoretical understanding while encouraging practical application, fostering innovation and exploration of AI’s limitless possibilities across domains.

Course Overview
The course is taught by Professor Paul Liang at MIT and aims to cultivate students’ research and application skills in multimodal intelligence and AI. The curriculum is divided into four modules: AI Fundamentals, Multimodal AI Basics, Large Models and Modern AI, and Interactive AI. Each module covers multiple topics such as data structures, multimodal fusion, large language models, and human-computer interaction. Students are expected to complete reading assignments, participate in discussions, and undertake a high-quality research project, with learning outcomes assessed through proposals, midterm and final reports, and presentations.
Grading is based on reading assignments (40%) and the research project (60%). Students rotate roles in weekly discussions—such as discussion leaders or summarizers—to enhance critical and creative thinking. The course also incorporates role-playing tasks to help students understand and apply AI technology from different perspectives.
Conducting AI Research
The course guides students on generating research ideas, reading academic papers, executing research plans, and writing research papers. It details each stage of the research process, including bottom-up discovery and top-down design methods, emphasizing the importance of scientific questions and hypotheses. Examples of research directions include multimodal AI, sensor data processing, AI reasoning, interactive agents, embodied AI, social intelligence AI, human-computer interaction, and ethics and safety.
The course introduces methods for literature reviews, steps to test research ideas, and the structure and key points of research papers. Students are provided with extensive resource links and tool recommendations to support their research. Weekly assignments include submission of project preference forms and previews of upcoming course topics, offering a comprehensive guide to AI research from theory to practice.

Data, Structure, and Learning
The course covers characteristics, structures, and common learning objectives for different data modalities, including visual, language, audio, sensor, tabular, graph, and set data. It explores data representations, distributions, granularity, structures, information content, noise, and correlations for each modality. Learning paradigms such as supervised, unsupervised, and reinforcement learning are discussed, along with their application in multimodal and multitask learning.
The course emphasizes the importance of data preprocessing, visualization, and model selection, as well as evaluating model generalization using training, validation, and test data. Weekly assignments include project preference form submission, project proposal preparation, and optional tutorials on machine learning tools for the following week. This equips students with foundational knowledge in data handling and machine learning for effective AI research.

Practical AI Tools
The course focuses on PyTorch and Hugging Face, providing practical guidance for AI development and debugging. It introduces Hugging Face’s key features, including the transformers and datasets libraries, which integrate seamlessly with PyTorch and offer pretrained models and data loading capabilities. Additional libraries such as bitsandbytes and flash-attn are highlighted for optimizing model performance and memory usage.
Debugging techniques are also discussed, including establishing strong connections with data, setting up end-to-end skeleton models, diagnosing errors through overfitting, improving generalization via regularization, tuning hyperparameters, and extracting maximum performance. The course advises designing machine learning models for new data by starting simple and gradually increasing complexity, emphasizing best practices for avoiding common pitfalls and ensuring model reliability.

Model Architectures
The course covers model architecture design principles for different data modalities, including sequential, spatial, set, and graph data. It teaches how to choose appropriate architectures based on data characteristics, such as RNNs for time-series data, CNNs for spatial data, and GNNs for graph data. Discussions include achieving invariance and equivariance through parameter sharing and information aggregation, as well as designing models according to data semantics, granularity, structure, information content, noise, and correlations.
Weekly assignments include submission of project proposals and preparation for reading discussions. The course provides systematic guidance for designing model architectures, helping students understand and apply various model types in AI research.
Multimodal AI and Alignment
The course explores core concepts in multimodal AI, including data heterogeneity, cross-modal connectivity, and interactions. It covers the historical evolution of multimodal research—from the behavioral era to deep learning, and now to the foundational model era. Diverse multimodal tasks are discussed, including language-vision integration, sentiment analysis, and video event recognition, along with challenges in multimodal alignment, including discrete and continuous alignment methods and contrastive learning for cross-modal alignment.
Six core challenges in multimodal AI are highlighted: representation learning, alignment, reasoning, generation, transfer, and quantification. The course emphasizes the CLIP model’s applications in language and vision tasks, demonstrating how contrastive learning can capture shared and unique modal information. Weekly assignments include reading discussions and project progress feedback. This provides students with a comprehensive overview of multimodal AI, enabling them to understand the complexity of multimodal data and how model design and learning strategies can address its challenges.

Multimodal Fusion
The course provides an in-depth exploration of the core concepts and techniques of multimodal fusion, including early, mid, and late fusion, as well as additive, multiplicative, tensor, low-rank, and gated fusion methods. Topics range from simple linear fusion to complex nonlinear fusion techniques, including dynamic fusion strategies to optimize the representation and learning of multimodal data. Challenges in multimodal fusion are discussed, such as balancing overfitting and generalization across modalities, and how contrastive learning and multimodal representation learning can address practical tasks.
The course also covers real-world challenges in multimodal fusion, such as handling heterogeneity between modalities, mitigating the impact of single-modality bias on fusion results, and improving performance through dynamic fusion and architecture search. Weekly assignments include reading discussions and project progress feedback, helping students better understand and apply multimodal fusion techniques.
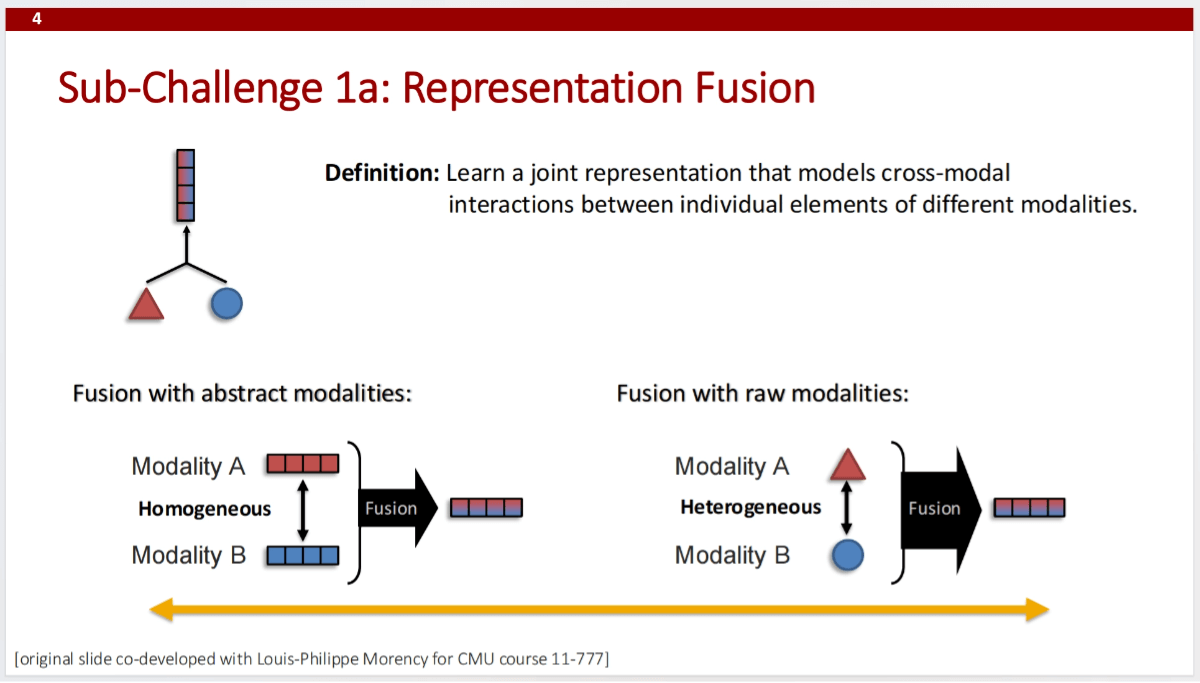
Cross-Modal Learning
The course delves into the fundamental concepts and techniques of cross-modal learning, including knowledge transfer between modalities via fusion, alignment, and translation. It covers multiple transfer strategies in multimodal learning, such as pretrained model transfer, co-learning, and model induction. Special attention is given to the HighMMT model, which enables knowledge transfer between partially observable modalities, supporting multitask and transfer learning across diverse modalities and tasks.
Open challenges in cross-modal learning are discussed, including learning in low-resource modalities, applications beyond language and vision, challenges in training with complex data and models, and model interpretability. Weekly assignments include reading discussions and project progress feedback to help students deepen their understanding and practical application of cross-modal learning techniques.
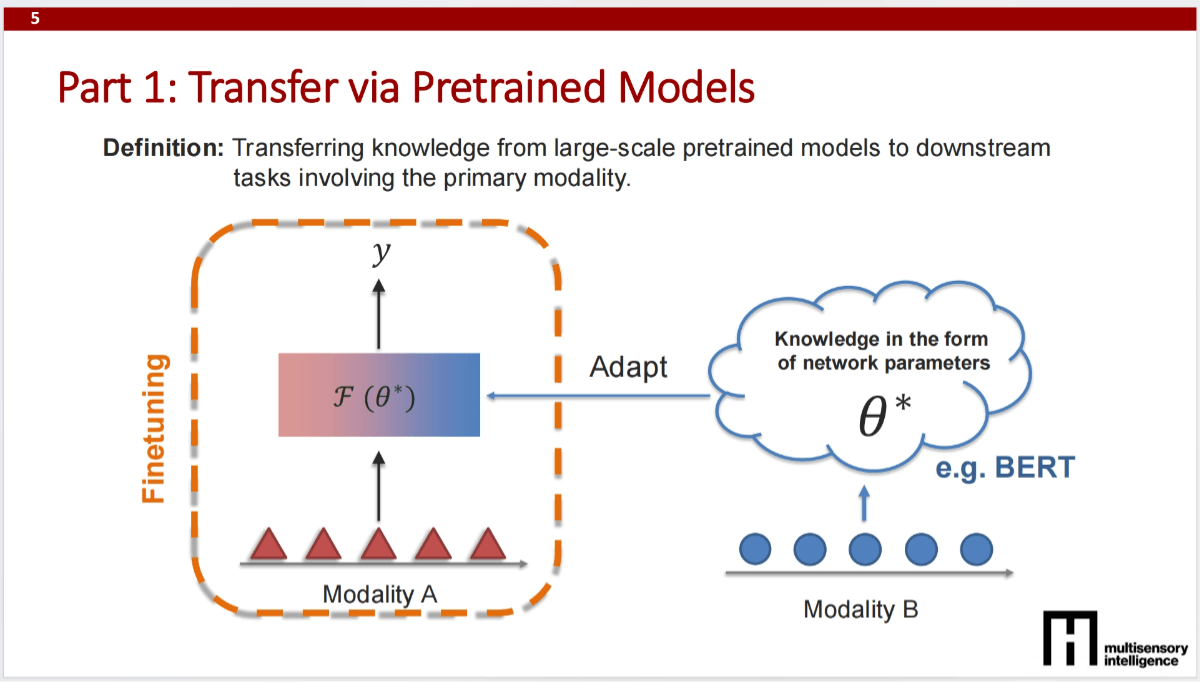
Large Foundation Models
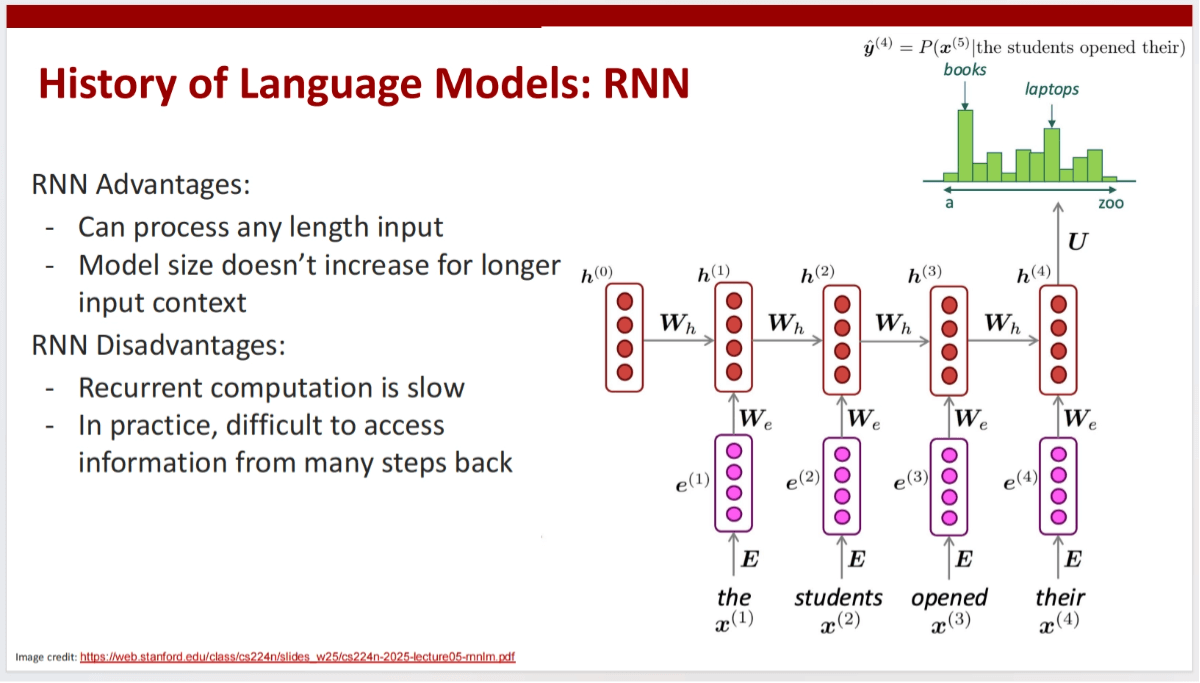
The course provides a detailed overview of large language models (LLMs), including their development, pretraining methods, architectures, instruction fine-tuning, preference optimization, and efficient training and inference techniques. It traces the evolution from RNNs to Transformer architectures and discusses unsupervised pretraining on large-scale text data. Techniques for optimizing model performance through instruction tuning, LoRA (low-rank adaptation), and quantization are also covered to improve training efficiency and inference speed.
Future directions for LLMs are discussed, including teaching models to reason, extending LLMs to multimodal tasks, and evaluating and deploying these models in real-world applications. Weekly assignments include midterm report submission and project resource application forms to help students understand and apply large foundation model technologies.
Large Multimodal Models
The course introduces foundational knowledge of large multimodal models, pretraining methods, adapting LLMs to multimodal LLMs, and the latest advances from text to multimodal generation. Topics include multimodal representation learning, multimodal Transformer architectures, cross-modal attention mechanisms, and performance optimization via instruction tuning and preference adjustments.
Students learn how to implement conditional multimodal generation using prefix tuning and adapter layers, and how large-scale pretraining datasets and multimodal instruction tuning datasets enhance model generalization. Future directions include designing native multimodal models, applying multimodal mixture-of-experts (MoE) models, and using multimodal models for practical scenarios such as time-series data. Weekly assignments include reading discussions and project progress feedback.

Modern Generative AI
The course covers core concepts, current techniques, conditional generation methods, model architectures, and training techniques for generative AI. It explores various generative models, including VAEs, diffusion models, and flow-matching models, discussing training objectives, noise handling, sampling speed, and pros and cons.
Methods for optimizing generation with conditional vector fields and loss functions, as well as architectural strategies to enhance model performance, are presented. Evaluation metrics, such as Fréchet Inception Distance (FID), CLIP Score, precision/recall, and aesthetic scores, are also introduced to assess the quality and diversity of generated content. Weekly assignments include readings and project progress feedback.
Reinforcement Learning and Interaction
The course introduces the fundamentals of reinforcement learning (RL), its applications in LLM alignment and reasoning, and the design and implementation of interactive LLM agents. Topics include Markov Decision Processes (MDPs), policy learning, model-based vs. model-free methods, and optimization via policy gradient methods like REINFORCE and PPO.
Human feedback in RL, reward model training, and preference optimization techniques are also covered. Practical challenges are discussed, including reward function design, exploration-exploitation trade-offs, and methods like Direct Preference Optimization (DPO) and Group Policy Optimization (GRPO) to improve model efficiency and performance. Weekly assignments include final project reports and presentation preparation.

Latest Developments
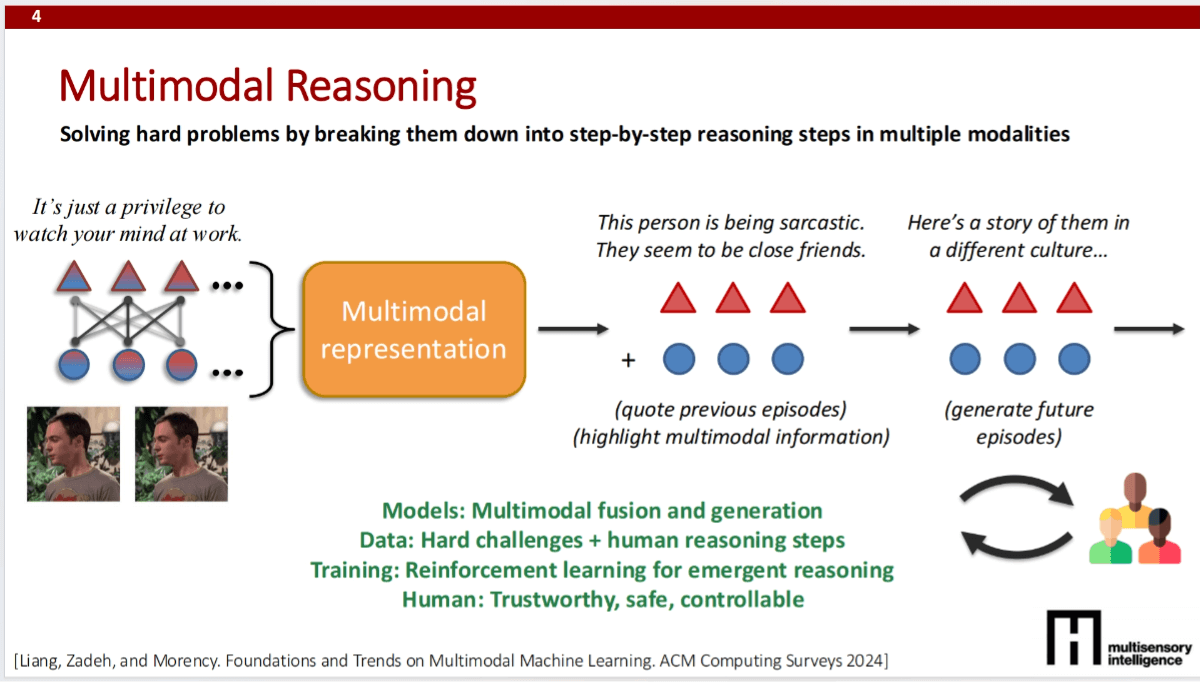
The course explores cutting-edge topics such as multimodal reasoning, AI agents, human-computer interaction, and ethics and safety. Topics include multimodal representation methods, adapting LLMs for multimodal text generation, text and image generation, and improving model reliability and safety through interaction.
Special attention is given to the Interactive Sketchpad system, a multimodal tutoring tool for collaborative and visual problem-solving that enhances reasoning and code execution capabilities. Applications in education, such as using visual reasoning to teach abstract geometry concepts, are discussed. The course also addresses ethical and safety challenges, including quantifying model limitations, predicting and controlling behavior, and mitigating bias and unfairness. Weekly assignments include final project submission and course feedback collection.
Project Links
-
Official Website: https://mit-mi.github.io/how2ai-course/spring2025/
-
GitHub Repository: https://github.com/MIT-MI/how2ai-course
Application Scenarios
-
Healthcare: Using AI to process medical images and clinical records, developing assistive diagnostic systems to improve the accuracy and efficiency of disease detection and treatment.
-
Intelligent Transportation: Leveraging AI to analyze traffic camera videos and sensor data, enabling autonomous driving assistance systems and optimizing traffic flow.
-
Art and Creative Design: Utilizing AI to generate music, paintings, and other creative content, converting textual descriptions into visual or audio works, providing new tools for artists and designers.
-
Intelligent Education: Developing AI-driven personalized learning systems that analyze student behavior and feedback to deliver customized learning paths and instructional content.
-
Environmental Protection: Applying AI to satellite imagery and environmental sensor data to monitor environmental changes, predict natural disasters, and support ecological conservation and sustainable development.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...