InfinityHuman – an AI digital human video generation model jointly launched by ByteDance and Zhejiang University
What is InfinityHuman?
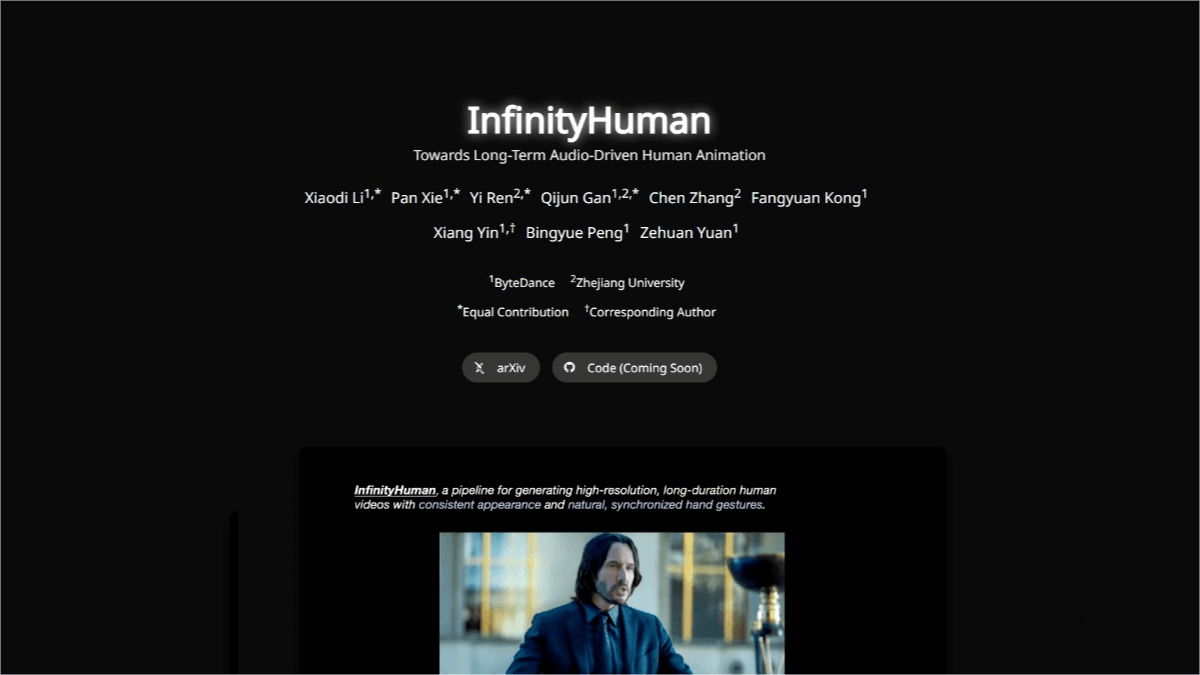
InfinityHuman is a commercial-grade long-sequence, audio-driven human video generation model jointly developed by ByteDance and Zhejiang University, marking a new chapter in the practical application of AI digital humans. The model adopts a coarse-to-fine framework: it first generates low-resolution motion representations and then progressively refines them into high-resolution, long-duration videos through a pose-guided refiner. InfinityHuman introduces a hand-specific reward mechanism to optimize the naturalness and synchronization of hand gestures, effectively addressing common issues in existing methods such as identity drift, video instability, and unnatural hand movements. Evaluated on EMTD and HDTF datasets, InfinityHuman demonstrates outstanding performance, unlocking new possibilities for applications in virtual broadcasting, education, customer service, and beyond.
Key Features of InfinityHuman
-
Long-duration video generation: Produces high-resolution, long-duration human animation videos while maintaining visual consistency and stability.
-
Natural hand gestures: Employs a hand-specific reward mechanism to generate natural, accurate, and speech-synchronized hand movements.
-
Identity consistency: Uses a pose-guided refiner and the first frame as a visual anchor to reduce cumulative errors and preserve character identity over long sequences.
-
Lip-sync accuracy: Ensures that lip movements in generated videos are tightly synchronized with audio, enhancing realism.
-
Diverse character styles: Supports the generation of characters in various styles, adaptable to different application scenarios.
Technical Principles of InfinityHuman
-
Low-resolution motion representation generation: The model generates audio-synchronized low-resolution motion representations (poses), serving as a “draft” to align rhythm, gestures, and lip movements globally.
-
Pose-Guided Refiner: Builds upon low-resolution motion representations to progressively generate high-resolution videos.
-
Pose sequence: Acts as a stable intermediate representation that resists temporal degradation and preserves visual consistency.
-
Visual anchor: The first frame serves as a visual anchor, continuously guiding identity correction and reducing cumulative errors.
-
Hand-specific reward mechanism: Trained with high-quality hand motion data, this mechanism optimizes naturalness and synchrony of hand gestures with speech.
-
Multimodal conditioning: Integrates multiple modalities—including reference images, text prompts, and audio—to ensure both visual and auditory coherence and naturalness.
Project Links
-
Official Website: https://infinityhuman.github.io/
-
arXiv Paper: https://arxiv.org/pdf/2508.20210
Application Scenarios of InfinityHuman
-
Virtual broadcasting: Enables virtual hosts to naturally deliver news, shows, and live programs, enhancing viewer engagement while reducing manpower costs.
-
Online education: AI teachers can explain knowledge while making appropriate gestures, making the teaching process more vivid and engaging, thereby boosting student interest and focus.
-
Customer service: Digital agents can respond with natural gestures during voice interactions, overcoming the mechanical impression of traditional customer service and improving user satisfaction.
-
Film & TV production: Generates high-quality, long-duration character animations for movies and dramas, significantly reducing manual drawing and post-production workload.
-
Virtual social interaction: Equips virtual characters in VR and AR with natural gestures and expressions, making social interactions more realistic, immersive, and interactive.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...