FineVision – A Hugging Face open-source vision-language dataset
What is FineVision?
FineVision is an open-source vision-language dataset released by Hugging Face to train advanced vision-language models. It contains 17.3 million images, 24.3 million samples, 88.9 million conversation turns, and 9.5 billion answer tokens. The dataset aggregates data from over 200 sources, featuring multimodal and multi-turn dialogues that integrate both vision and language. Each image is paired with a text caption, helping models better understand and generate natural language. FineVision improves model performance by more than 20% on average across 10 benchmarks.
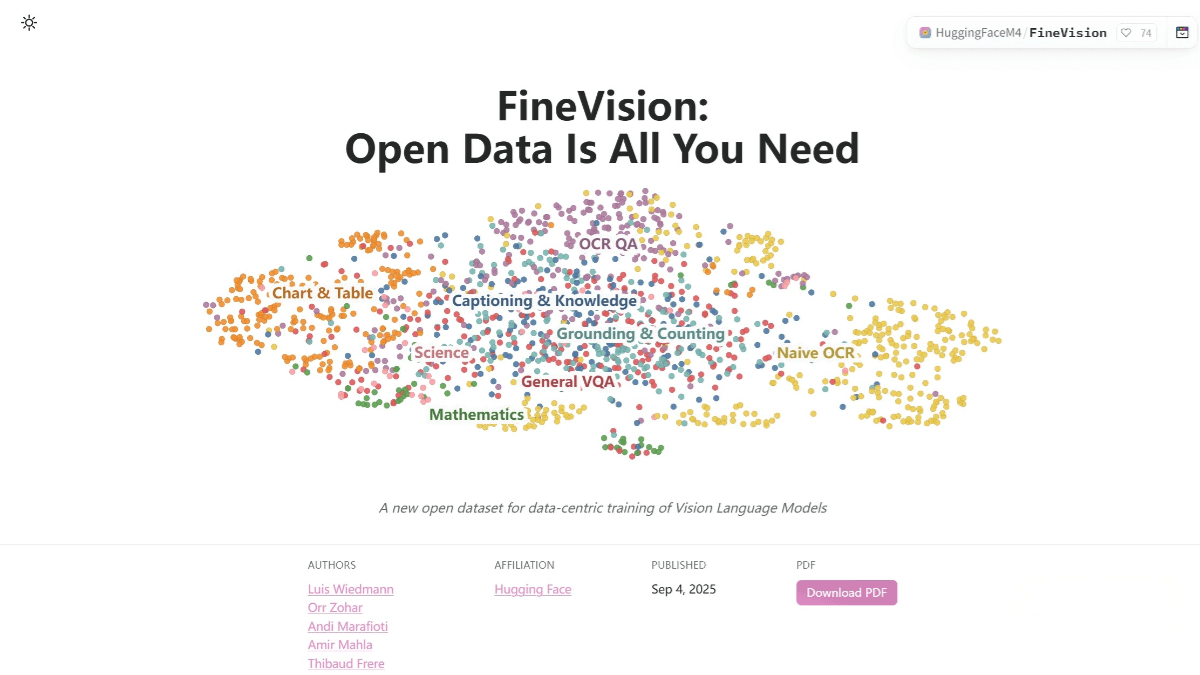
Key Features of FineVision
-
Multimodal data integration: Combines images and text, enabling models to process both visual and language information for improved understanding of complex scenarios.
-
Multi-turn dialogue support: Provides abundant multi-turn dialogue data, allowing models to learn natural conversational patterns and enhance interaction capabilities.
-
Large-scale data resources: Offers massive volumes of images and text samples, ensuring sufficient training data to boost model generalization.
-
Performance improvement: Significantly enhances the performance of vision-language models on multiple benchmarks, advancing the development of related technologies.
Dataset Scale of FineVision
-
Images: 17.3 million
-
Samples: 24.3 million
-
Conversation turns: 88.9 million
-
Answer tokens: 9.5 billion
-
Data sources: Aggregated from more than 200 different sources
Project Links
-
Official project page: https://huggingface.co/spaces/HuggingFaceM4/FineVision
-
Hugging Face dataset: https://huggingface.co/datasets/HuggingFaceM4/FineVision
Application Scenarios of FineVision
-
Visual Question Answering (VQA): Helps models understand and generate natural language answers about image content, improving accuracy and fluency.
-
Image captioning: Automatically generates detailed descriptions of images, useful for annotation tasks and assisting visually impaired individuals.
-
Multi-turn dialogue systems: Strengthens dialogue systems with visual context, enabling more natural and coherent conversations.
-
Visual navigation: Supports tasks like robot navigation and autonomous driving by interpreting images to make decisions.
-
Education and training: Enables the development of educational tools that help students interpret and describe image content, enhancing visual cognition.
-
Content creation: Assists creators in generating text content related to images, improving both efficiency and quality.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...