
What is PP-OCRv5?
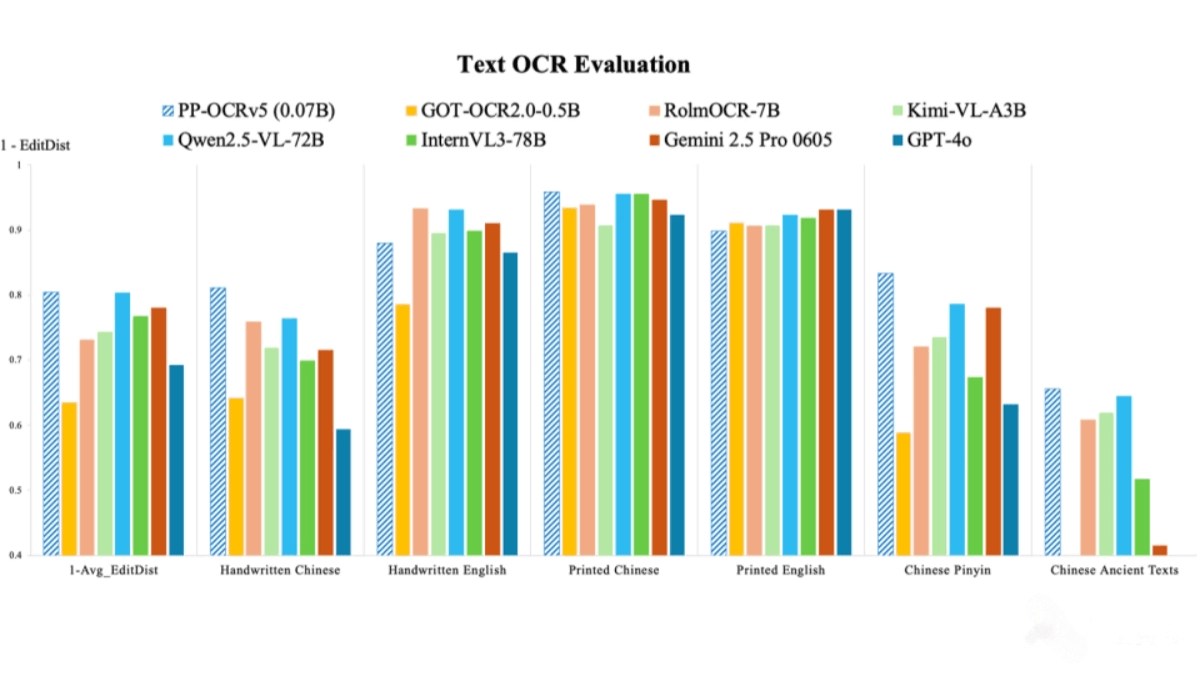
PP-OCRv5 is an efficient and accurate text recognition model released by Baidu. It is based on a two-stage processing pipeline designed to quickly and precisely detect and recognize text in images. With only 7 million parameters, the model is lightweight and highly efficient, achieving excellent performance on CPUs and edge devices, processing over 370 characters per second. PP-OCRv5 supports five text types—Simplified Chinese, Traditional Chinese, English, Japanese, and Pinyin—and can recognize over 40 languages. Across multiple OCR benchmarks, PP-OCRv5 outperforms general vision-language models, especially in handwritten and printed text recognition.
Key Features of PP-OCRv5
-
Efficient Text Detection and Recognition: Rapidly detects text regions in images and accurately recognizes the content, suitable for use cases such as document scanning and text extraction from images.
-
Multilingual Support: Supports Simplified Chinese, Traditional Chinese, English, Japanese, and Pinyin, with recognition capability across 40+ languages, meeting diverse OCR needs.
-
Precise Text Localization: Provides accurate bounding boxes for text lines, crucial for structured data extraction and content analysis.
-
High Efficiency with Low Resource Consumption: With only 7M parameters, the model runs efficiently on CPUs and edge devices, making it ideal for resource-constrained environments like mobile or embedded systems.
-
Adaptability to Different Text Styles: Handles both printed and handwritten text effectively, performing well even on poor-quality scans or low-resolution documents.
Technical Principles of PP-OCRv5
-
Two-Stage Pipeline: First detects text in images, then recognizes the characters in the detected regions, converting them into editable text.
-
Modular Design: Composed of four key components—image preprocessing, text detection, text-line direction classification, and text recognition. This modular design improves both efficiency and accuracy.
-
Deep Learning-Based: Built on deep learning frameworks like PaddlePaddle, trained on large annotated datasets to learn text characteristics and image patterns for robust recognition across complex scenarios.
-
Optimized Network Architecture: Balances high accuracy with reduced parameters and computational cost, ensuring high performance while running efficiently on various hardware platforms.
Project Links
-
Official Page: https://huggingface.co/blog/baidu/ppocrv5
-
HuggingFace Model Hub: https://huggingface.co/collections/PaddlePaddle/pp-ocrv5-684a5356aef5b4b1d7b85e4b
Application Scenarios of PP-OCRv5
-
Document Processing: Converts paper documents into digital text quickly, useful for office automation and archive management.
-
Education: Recognizes handwritten text in students’ assignments and exam papers, assisting teachers with grading.
-
Finance: Efficiently extracts text from invoices, receipts, and contracts, improving data entry and review efficiency.
-
Traffic Management: Accurately recognizes license plates and road sign text, supporting traffic monitoring and autonomous driving.
-
Mobile Office: Enables quick text extraction from documents and images on mobile devices, supporting on-the-go productivity.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts



No comments yet...