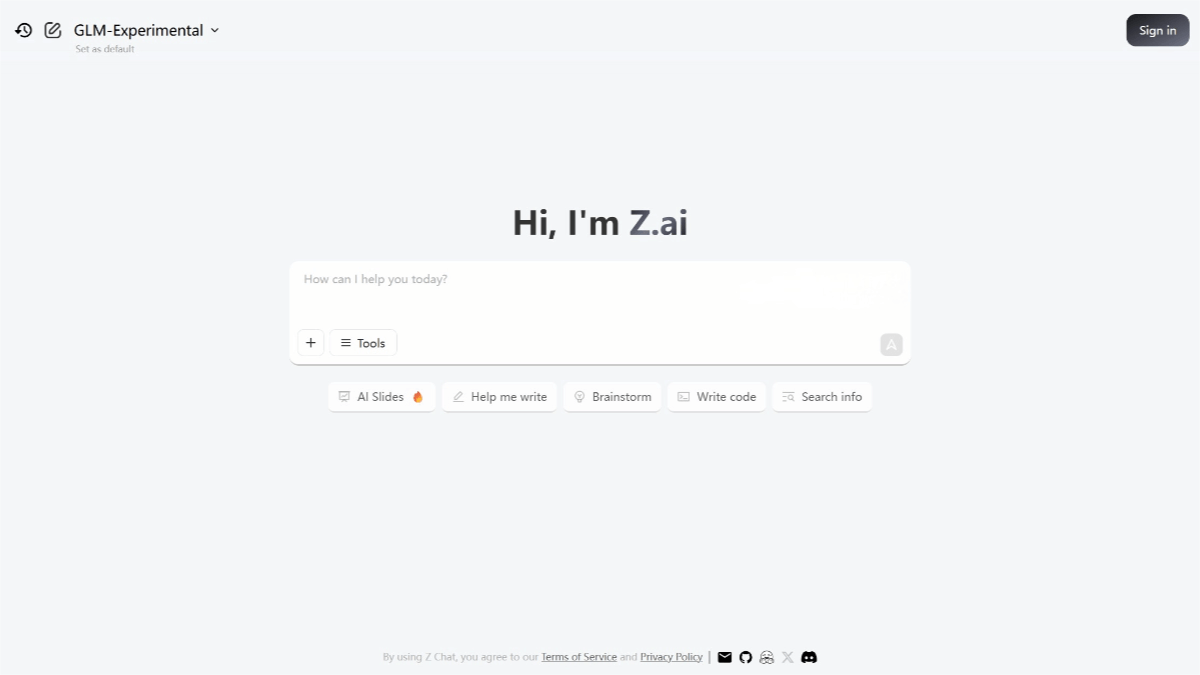
Mini-o3 – a visual reasoning model launched jointly by ByteDance and the University of Hong Kong
What is Mini-o3?
Mini-o3 is an open-source model jointly developed by ByteDance and the University of Hong Kong, designed specifically to tackle complex visual search problems. The model uses reinforcement learning and image-based tools to perform deep, multi-round reasoning, with reasoning steps scalable to dozens of iterations. Mini-o3 enhances reasoning ability and interaction depth through the creation of challenging datasets, iterative data collection processes, and an over-turn masking strategy. It achieves state-of-the-art performance on multiple visual search benchmarks. All code, models, and datasets are open-source, enabling reproducibility and further research.
Key Features
-
Multi-round interactive reasoning: Performs deep, multi-round reasoning, scalable to dozens of iterations, solving complex visual search problems through step-by-step exploration and trial-and-error.
-
Diverse reasoning modes: Supports various reasoning strategies, including depth-first search, trial-and-error, and target maintenance.
-
Challenging visual search: Accurately locates and identifies targets in high-resolution images even when the targets are small and surrounded by numerous distractors.
-
Excellent performance: Achieves state-of-the-art results on multiple visual search benchmarks (e.g., VisualProbe, V* Bench, HR-Bench, MME-Realworld), demonstrating strong visual reasoning capability.
-
Open-source: All code, models, and datasets are open-source, allowing researchers to reproduce results and advance related research.
Technical Principles of Mini-o3
-
Cold-start Supervised Fine-tuning (SFT): Uses a small number of hand-crafted examples to generate high-quality, diverse multi-round interaction trajectories with a visual-language model (VLM) possessing strong contextual learning ability.
-
Reinforcement Learning (RL): Uses an over-turn masking strategy to avoid penalties when interaction rounds exceed limits, allowing natural extension to dozens of rounds during testing.
-
Lower Down Max Pixels: Reduces the maximum pixel count per image, increasing the number of rounds allowed per interaction and improving the model’s ability to solve long-horizon problems.
-
Challenging dataset (Visual Probe Dataset): Constructs a dataset of thousands of visual search problems designed to encourage exploratory reasoning, helping the model learn complex reasoning patterns during training.
Project Links
-
Official site: https://mini-o3.github.io/
-
GitHub repository: https://github.com/Mini-o3/Mini-o3
-
HuggingFace model hub: https://huggingface.co/Mini-o3/models
-
arXiv paper: https://arxiv.org/pdf/2509.07969
Application Scenarios for Mini-o3
-
E-commerce: Helps users quickly locate target products among massive image collections. For example, on a fashion e-commerce platform, users can upload an image to find similar clothing items.
-
Smart home: In smart home environments, captures images via cameras to help users quickly find lost items such as keys or remote controls.
-
Surveillance video analysis: Rapidly locates and identifies specific targets in surveillance footage, such as finding a person or object in crowded areas.
-
Anomaly detection: Uses multi-round reasoning to detect abnormal behavior in surveillance videos, such as intrusions or unusual activities.
-
Complex scene navigation: Assists autonomous driving systems with multi-round visual reasoning to better understand and plan routes in complex road conditions, such as scenes with occlusions or complicated traffic signs.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts



No comments yet...