
FastMTP – Tencent’s Open-Source Large Language Model Inference Acceleration Technology
What is FastMTP?
FastMTP is Tencent’s self-developed large language model (LLM) inference acceleration technology. By optimizing multi-token prediction (MTP), it replaces traditional multiple independent modules with a single shared-weight MTP head. Combined with language-aware vocabulary compression and self-distillation training, it significantly boosts LLM inference speed—achieving an average 2.03× acceleration—without any loss in output quality. FastMTP does not alter the main model architecture, making it easy to integrate into existing frameworks. It is particularly effective for structured tasks such as mathematical reasoning and code generation, providing a practical solution for efficient LLM deployment.
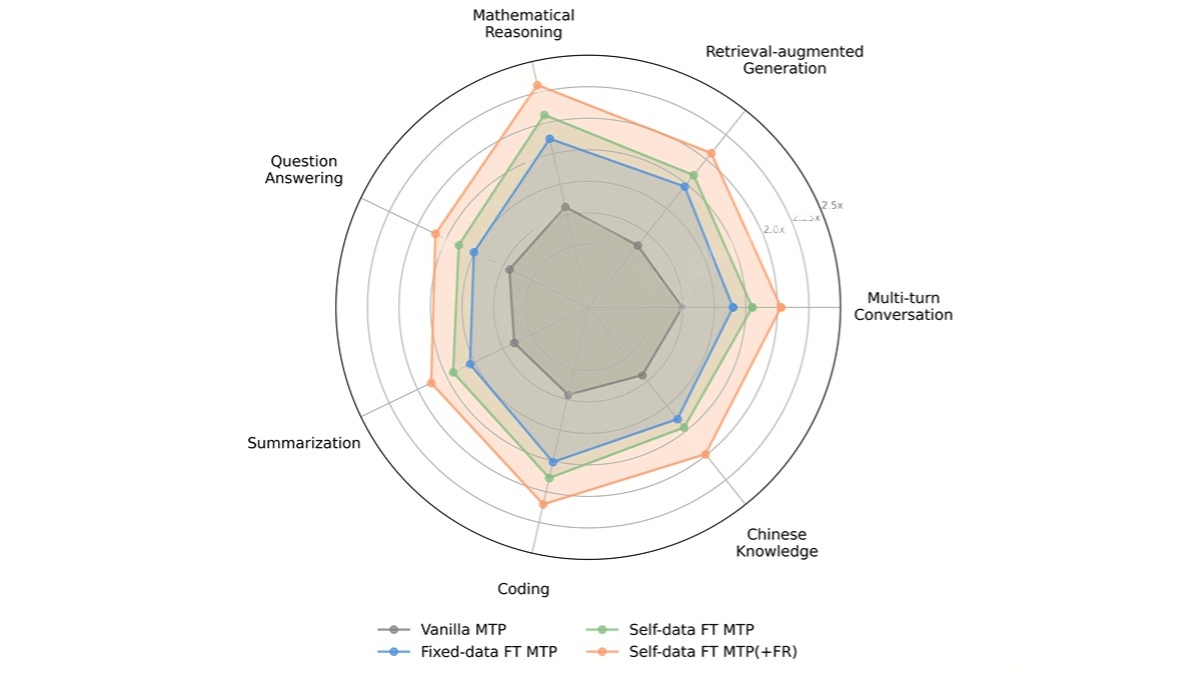
Key Features of FastMTP
-
Significant acceleration of LLM inference:
Through optimized multi-token prediction (MTP), FastMTP can increase LLM inference speed by an average of 2.03× without sacrificing output quality, greatly reducing content generation time and improving application responsiveness. -
Lossless output quality:
While accelerating inference, FastMTP ensures that the generated results remain fully consistent with traditional autoregressive methods, maintaining accuracy and logical coherence. -
Easy integration and deployment:
FastMTP requires no modification to the main model structure—only a small module needs fine-tuning. It can be seamlessly integrated into existing LLM inference frameworks (such as SGLang), lowering deployment costs and complexity for real-world applications. -
Reduced hardware resource consumption:
By replacing multiple independent MTP modules with a shared-weight single MTP head, memory usage is reduced. Additionally, with language-aware vocabulary compression, computation is further minimized, enabling efficient operation even on consumer-grade GPUs and lowering hardware requirements.
Technical Principles of FastMTP
-
Speculative decoding:
Inspired by the “draft + verification” approach, a fast draft model generates multiple candidate tokens, which the main model validates in batches, enabling parallel processing and improved inference efficiency. -
Single shared-weight MTP head:
Instead of multiple independent MTP modules, FastMTP uses a shared-weight MTP head to recursively generate multiple tokens. This reduces memory usage, forces the model to learn longer-range dependencies, and improves draft quality. -
Self-distillation training:
The MTP head is trained on data generated by the main model. Using an exponentially decayed weighted cross-entropy loss function, it prioritizes producing drafts aligned with the main model’s style and logic, improving draft acceptance rates. -
Language-aware vocabulary compression:
During draft generation, only high-frequency vocabulary logits relevant to the input context are computed, reducing computational load. In the verification phase, the full vocabulary is used, ensuring final output quality remains unaffected.
Project Resources
-
GitHub Repository: https://github.com/Tencent-BAC/FastMTP
-
HuggingFace Model Hub: https://huggingface.co/TencentBAC/FastMTP
-
Technical Paper: FastMTP Technical Report
Application Scenarios of FastMTP
-
Mathematical reasoning: Quickly generates problem-solving steps, reducing time from input to answer, and improving the responsiveness of math assistance tools.
-
Code generation: Accelerates code snippet generation, enabling developers to complete tasks more efficiently.
-
Long-text summarization: Extracts key information from lengthy articles or reports, producing high-quality summaries and saving reading time.
-
Multi-turn dialogue: Enhances chatbots and virtual assistants by delivering near-instant responses, improving user experience and conversational flow.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...