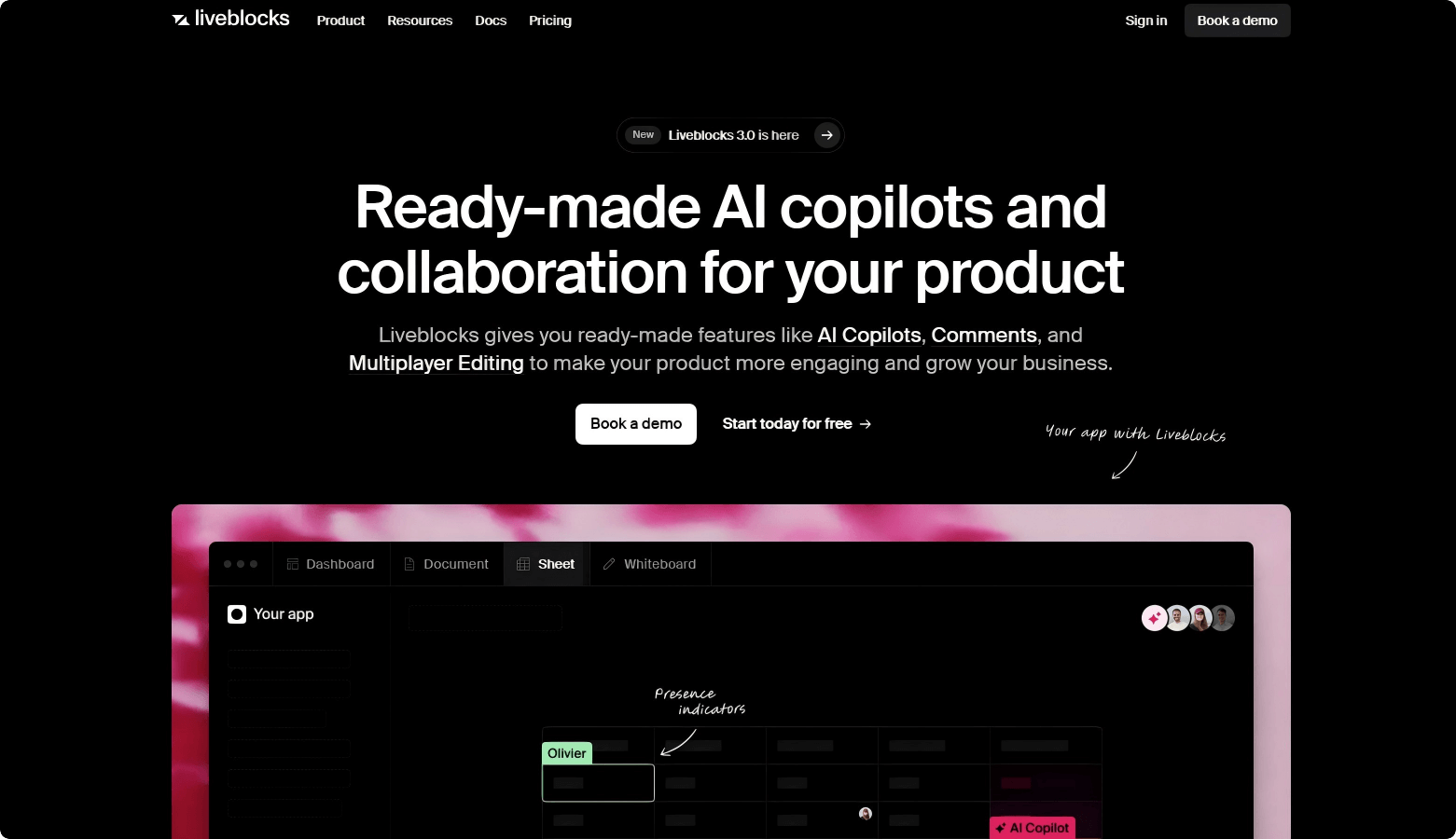
Audio2Face – NVIDIA’s open-source AI facial animation generation model
What is Audio2Face?
Audio2Face is an AI-based facial animation generation model developed by NVIDIA. By taking audio as input, it can generate realistic facial animations. The model analyzes phonemes and intonation in the audio to drive lip movements and facial expressions, enabling precise lip-sync and emotional expression. Now open-sourced, developers can use its SDK and plugins to quickly create high-quality animations in tools such as Maya and Unreal Engine 5, or customize the model through its training framework. Audio2Face is widely applied in areas like gaming and virtual customer service, significantly improving both the efficiency and realism of digital character production.
Key Features of Audio2Face
-
Accurate Lip-Sync: Generates natural and accurate lip movements that match phonemes and intonation in the audio, ensuring the character’s speech looks realistic.
-
Emotional Expression: Produces corresponding facial expressions—such as smiles or frowns—based on emotional cues from the audio (e.g., tone, rhythm), making characters more expressive.
-
Real-Time Animation: Supports real-time rendering, instantly converting audio into animations suitable for interactive scenarios such as virtual customer service or live streaming.
-
Multi-Platform Support: Provides integration plugins for mainstream 3D software like Autodesk Maya and Unreal Engine 5, allowing developers to use it across platforms.
-
Customizability: Developers can fine-tune the model with their own datasets through the training framework, adapting it to specific styles or character needs.
Technical Principles of Audio2Face
-
Audio Feature Extraction: The system extracts key features from input audio, such as phonemes (basic speech units), intonation, and rhythm. These features form the basis of facial animation. For example, different phonemes correspond to different mouth shapes, while intonation and rhythm affect expression changes.
-
Deep Learning Model: Audio2Face uses pretrained deep learning models (such as GANs or Transformers) to map audio features to facial animations. The models are trained on large amounts of paired audio and facial animation data to learn correlations between sounds and facial movements.
-
Generative Adversarial Networks (GANs): The GAN framework includes a generator and a discriminator. The generator creates facial animations from audio features, while the discriminator evaluates how realistic the animations are. Through iterative training, the generator produces increasingly lifelike facial animations.
-
Emotion Analysis: Audio2Face analyzes emotional features in the audio (e.g., pitch, speed, rhythm) and maps them to corresponding facial expressions.
Project Links
-
Official Website: https://developer.nvidia.com/blog/nvidia-open-sources-audio2face-animation-model/
-
GitHub Repository: https://github.com/NVIDIA/Audio2Face-3D
Application Scenarios of Audio2Face
-
Game Development: Quickly generates facial animations for game characters, reducing manual work on lip-syncing and expressions while enhancing realism and interactivity.
-
Virtual Customer Service: Provides natural lip-sync and expressions for virtual agents, making them appear more human-like and improving user communication experience.
-
Animation Production: Drives character facial animations in animated films or shorts using audio, improving production efficiency.
-
Virtual Live Streaming: Helps streamers generate real-time lip movements and expressions that match their speech, adding fun and interactivity to broadcasts.
-
Education and Training: Creates vivid facial expressions and lip-sync for virtual teachers in online classrooms, making lessons more engaging and improving learning outcomes.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...