What is Ming-UniAudio?
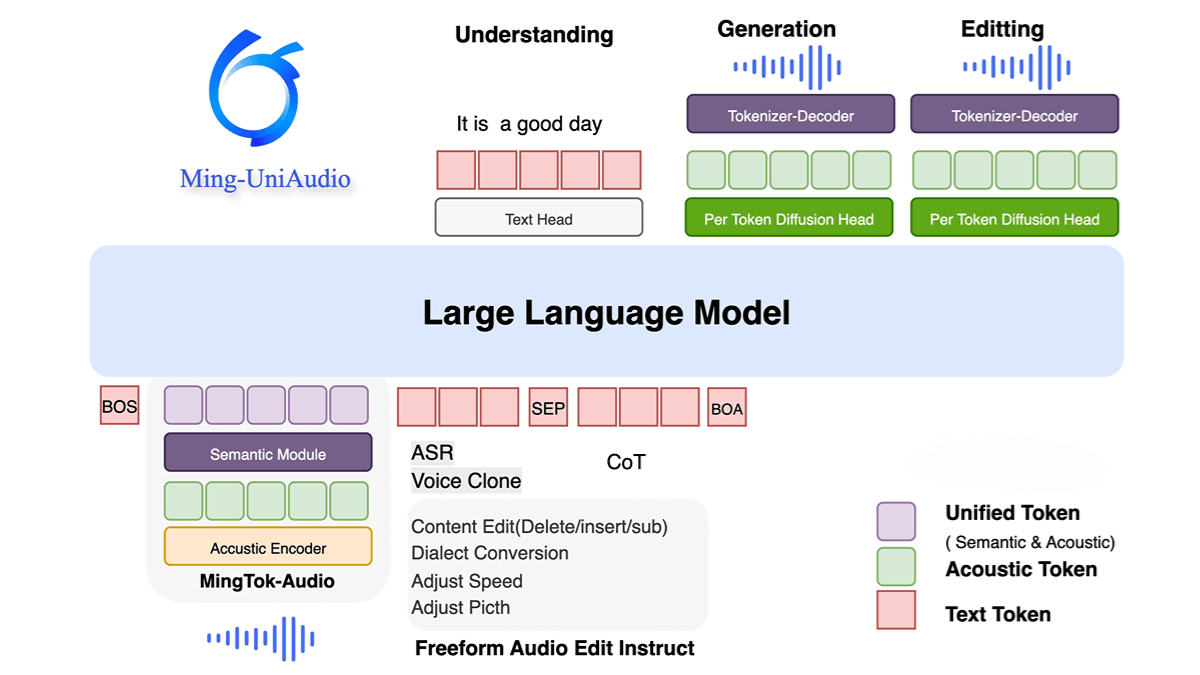
Ming-UniAudio is an open-source multimodal audio model developed by Ant Group, designed to unify speech understanding, generation, and editing tasks. At its core is MingTok-Audio, a continuous speech tokenizer built on a Variational Autoencoder (VAE) framework and causal Transformer architecture, which effectively integrates semantic and acoustic features. Based on this foundation, Ming-UniAudio introduces an end-to-end speech language model that balances generation and comprehension capabilities. With a diffusion head, it ensures high-quality, natural-sounding audio synthesis.
Notably, Ming-UniAudio provides the first instruction-driven free-form speech editing framework, allowing complex semantic and acoustic modifications without manually specifying edit regions. Across multiple benchmarks, it demonstrates strong performance in speech tokenization, understanding, generation, and editing. The model supports multiple languages and dialects and is suitable for use cases such as voice assistants, audiobooks, and audio post-production.
Key Features of Ming-UniAudio
-
Speech Understanding:
Accurately recognizes and transcribes spoken content in multiple languages and dialects, ideal for applications like voice assistants and meeting transcription. -
Speech Generation:
Converts text into natural, fluent speech suitable for audiobooks, voice broadcasts, and content narration. -
Speech Editing:
Enables free-form speech editing — including insertion, deletion, and replacement — without manual region selection, perfect for audio post-production and creative workflows. -
Multimodal Integration:
Supports multimodal inputs such as text and audio, enabling complex multimodal interaction tasks. -
Efficient Tokenization:
Uses the unified continuous speech tokenizer MingTok-Audio, integrating semantic and acoustic features to enhance performance. -
High-Quality Synthesis:
Employs a diffusion head to ensure natural and high-fidelity speech generation. -
Instruction-Driven Editing:
Supports natural language instruction for speech editing, simplifying workflows and improving usability. -
Open Source and Developer-Friendly:
Offers open-source code and pre-trained models, making it easy for developers to deploy and customize.
Technical Principles of Ming-UniAudio
-
Unified Continuous Speech Tokenizer:
Introduces MingTok-Audio, the first continuous speech tokenizer based on a VAE framework and causal Transformer, effectively integrating semantic and acoustic features for both understanding and generation tasks. -
End-to-End Speech Language Model:
Pre-trained on large-scale datasets to support both speech understanding and generation, with a diffusion head to guarantee high-quality audio output. -
Instruction-Guided Free-Form Speech Editing:
Features the first framework that allows flexible, instruction-driven speech editing, supporting comprehensive semantic and acoustic modifications without specifying edit areas manually. -
Multimodal Fusion:
Handles multiple input types such as text and audio, enabling complex cross-modal tasks and enhancing the model’s flexibility and universality. -
High-Quality Speech Synthesis:
Utilizes diffusion modeling techniques to generate natural and high-fidelity speech for a variety of generation scenarios. -
Multi-Task Learning:
Achieves balanced performance in speech understanding and generation through joint multi-task training. -
Large-Scale Pretraining:
Trained on extensive audio and text data to improve both language comprehension and generation abilities, enabling the model to handle complex speech tasks.
Project Links
-
Official Website: https://xqacmer.github.io/Ming-Unitok-Audio.github.io/
-
GitHub Repository: https://github.com/inclusionAI/Ming-UniAudio
-
HuggingFace Model Hub: https://huggingface.co/inclusionAI/Ming-UniAudio-16B-A3B
Use Cases of Ming-UniAudio
-
Multimodal Interaction and Dialogue:
Supports mixed inputs of audio, text, images, and video for real-time cross-modal interaction — ideal for intelligent assistants and immersive communication. -
Speech Synthesis and Cloning:
Generates natural-sounding voices and supports multi-dialect cloning and personalized voiceprint customization, useful for content creation and interactive voice applications. -
Audio Understanding and Q&A:
Provides end-to-end speech understanding for open-domain question answering, command execution, and multimodal reasoning — applicable in education, customer service, and audio content analysis. -
Multimodal Generation and Editing:
Supports text-to-speech, image generation and editing, and video dubbing, enabling media creation and cross-modal content production.