
LLaVA-OneVision-1.5 – A multimodal model open-sourced by the EvolvingLMMS Lab
What is LLaVA-OneVision-1.5?
LLaVA-OneVision-1.5 is an open-source multimodal model developed by the EvolvingLMMs-Lab, designed to achieve high performance, low cost, and strong reproducibility through efficient training and high-quality data. It adopts a self-developed RICE-ViT as its vision encoder, integrating 2D rotary positional embeddings and a region-aware attention mechanism to support variable input resolutions and enhance object recognition and OCR capabilities.
The language model backbone is Qwen3, optimized through a three-stage training process—language-image alignment, high-quality knowledge mid-stage pretraining, and visual instruction alignment. During training, offline parallel data packing and hybrid parallelism strategies are employed to improve computational and memory efficiency.
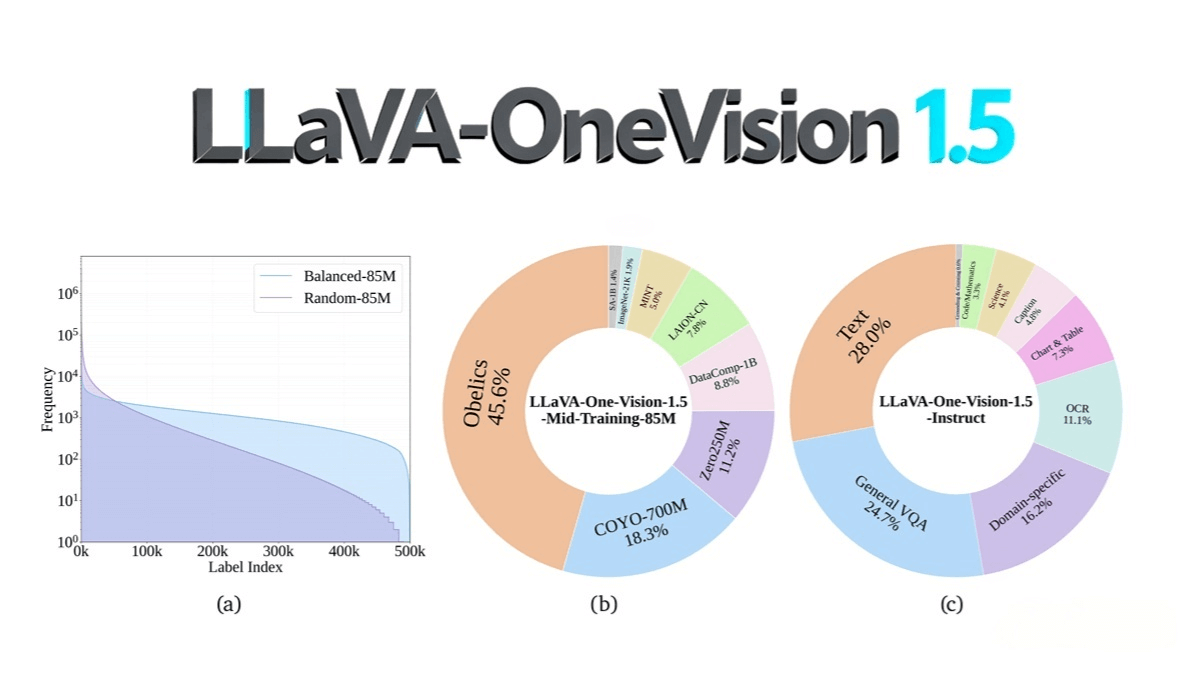
The dataset includes 85 million pretraining samples built using a “concept-balanced” strategy across diverse sources, and 22 million instruction data samples covering eight major categories with unified formatting and multi-source aggregation. LLaVA-OneVision-1.5 demonstrates excellent performance on multimodal benchmarks, maintains cost-effectiveness, and offers full transparency and openness across its code, data, and model resources—empowering the community to reproduce and extend it at low cost.
Main Features of LLaVA-OneVision-1.5
1. Multimodal Understanding and Generation
Processes and comprehends multiple modalities such as images and text to generate high-quality descriptions, answer questions, and perform reasoning.
2. Visual Question Answering (VQA)
Answers questions about visual content, supporting a wide range of vision tasks like object recognition and scene understanding.
3. Image Captioning
Generates detailed and accurate textual descriptions for input images, helping users interpret visual content more effectively.
4. Instruction Following and Execution
Executes user-provided instructions—such as image editing or information extraction—with strong generalization across instruction types.
5. Cross-Modal Retrieval
Supports text-to-image and image-to-text retrieval for cross-modal information search and understanding.
6. Long-Tail Recognition
Effectively identifies and understands rare categories or concepts, improving the model’s generalization ability.
7. Multilingual Support
Handles inputs and outputs in multiple languages, with cross-lingual understanding and generation capabilities.
8. Knowledge Enhancement
Pretrained with high-quality knowledge datasets to equip the model with richer world knowledge for complex multimodal reasoning.
9. Efficient Training and Reproducibility
Utilizes optimized training strategies and data-packing techniques for efficient model training; provides complete code and datasets for transparent community replication and expansion.
Technical Principles of LLaVA-OneVision-1.5
1. Vision Encoder
Employs the self-developed RICE-ViT (Region-aware Cluster Discrimination Vision Transformer) as the visual backbone. It enhances semantic understanding of local image regions through region-aware attention and a unified cluster discrimination loss, while supporting variable input resolutions.
2. Projector Design
Maps visual features into the language model’s embedding space via a multilayer perceptron (MLP), enabling effective alignment between visual and textual features.
3. Language Model
Built on Qwen3, providing strong language comprehension and generation capabilities for multimodal tasks.
4. Three-Stage Training Pipeline
Includes (1) language–image alignment, (2) high-quality knowledge mid-stage pretraining, and (3) visual instruction alignment—progressively enhancing multimodal alignment and task generalization.
5. Offline Parallel Data Packing
Constructs pretraining datasets with a concept-balanced strategy and employs offline parallel packing to minimize padding waste and improve efficiency.
6. Hybrid Parallelism and Long-Context Optimization
Combines tensor, pipeline, and sequence parallelism with long-context optimization to maximize compute utilization and memory efficiency.
7. Data Construction and Optimization
Builds large-scale pretraining and instruction-tuning datasets through multi-source aggregation, unified formatting, and rigorous quality filtering to ensure high diversity and reliability.
Project Resources
-
GitHub Repository: https://github.com/EvolvingLMMs-Lab/LLaVA-OneVision-1.5
-
Hugging Face Model Collection: https://huggingface.co/collections/lmms-lab/llava-onevision-15-68d385fe73b50bd22de23713
-
arXiv Paper: https://arxiv.org/pdf/2509.23661
-
Online Demo: https://huggingface.co/spaces/lmms-lab/LLaVA-OneVision-1.5
Application Scenarios
Intelligent Customer Service:
Understands uploaded images or text to provide automated support, answer user inquiries, and offer solutions.
Content Creation:
Assists creators in generating image captions, creative copy, or storytelling ideas to improve productivity and creativity.
Educational Assistance:
Used in education to interpret visual materials, assist teaching, and help students better understand complex visual information.
Medical Image Analysis:
Helps doctors interpret medical images, providing preliminary diagnostic suggestions or generating structured reports.
Autonomous Driving:
Analyzes road scenes in autonomous driving systems to support decision-making and enhance driving safety.
Image Editing and Design:
Performs user-directed image operations—such as editing, cropping, or applying effects—improving convenience and efficiency in image processing.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts



No comments yet...