What is DeepSeek-OCR?
DeepSeek-OCR is a vision-language model developed by the DeepSeek team, designed to efficiently process long-text content through optical compression technology. The model consists of the DeepEncoder encoder and the DeepSeek-3B-MoE decoder, achieving high-resolution input processing while significantly reducing activation memory and the number of visual tokens. DeepSeek-OCR achieves 97% OCR accuracy at a 10× compression ratio and maintains 60% accuracy at 20× compression. It supports multiple resolution modes, multilingual document processing, and complex content parsing (e.g., charts and chemical formulas), providing a highly efficient solution for large-scale document processing.
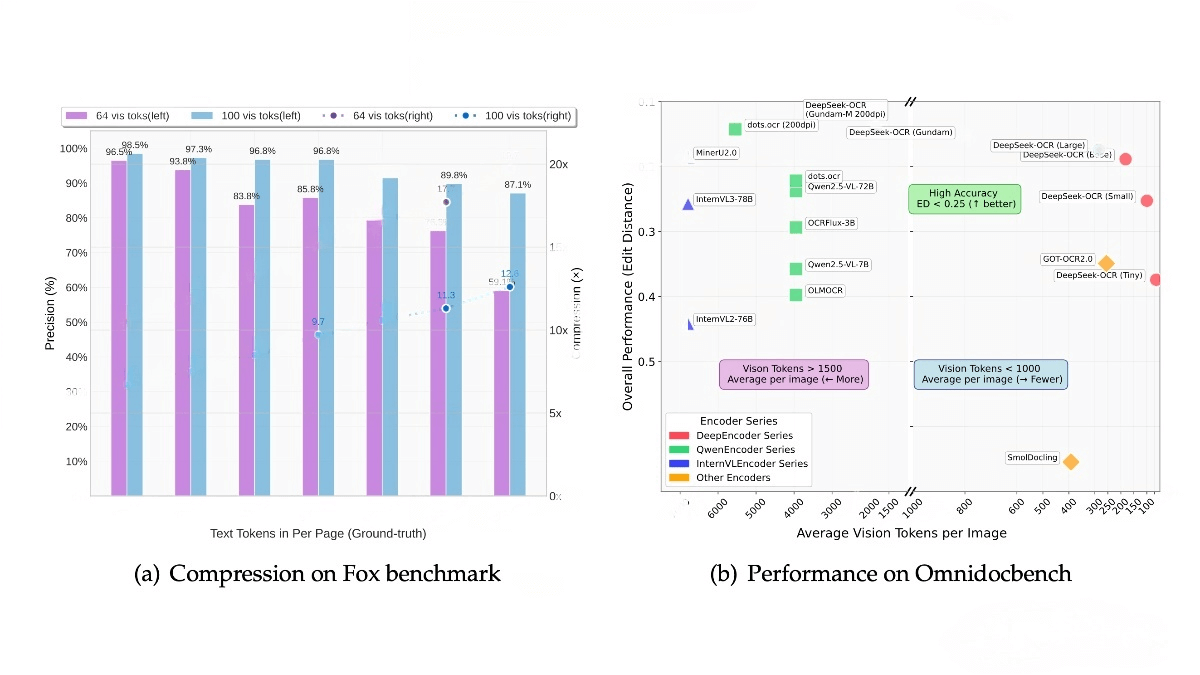
Key Features of DeepSeek-OCR
-
Visual Text Compression: Compresses long-text content efficiently through visual modalities, achieving a 7–20× compression ratio.
-
Multilingual OCR: Supports document recognition in nearly 100 languages, including Chinese, English, Arabic, and Sinhala.
-
Deep Parsing: Accurately interprets charts, chemical formulas, and geometric figures.
-
Multi-Format Output: Supports both layout-preserving Markdown and plain OCR output formats.
Technical Architecture of DeepSeek-OCR
Core Structure
DeepSeek-OCR is composed of two main components:
-
DeepEncoder – Encodes input images (documents) into visual tokens.
-
DeepSeek-3B-MoE-A570M – Serves as the decoder, converting visual tokens into text.
DeepEncoder
The DeepEncoder is the core component of DeepSeek-OCR, designed to maintain low activation memory under high-resolution input while achieving high compression. It includes the following components:
-
Dual-Tower Structure:
-
SAM-base (80M): Utilizes window attention to capture local features with low memory usage for high-resolution input.
-
CLIP-large (300M): Uses global attention to extract semantic information. Since the input is compressed, memory usage remains efficiently controlled.
-
-
16× Convolutional Compression Layer:
Between SAM and CLIP, a 16× convolutional compression module reduces the number of visual tokens from 4096 to 256 through two convolutional layers (stride=2). This design minimizes memory usage while preserving key information. -
Multi-Resolution Support:
DeepEncoder supports multiple resolution modes — Tiny, Small, Base, Large, and Gundam — each corresponding to different input resolutions and token counts:-
Tiny: 512×512 resolution → 64 visual tokens
-
Small: 640×640 resolution → 100 visual tokens
-
Base: 1024×1024 resolution → 256 visual tokens
-
Large: 1280×1280 resolution → 400 visual tokens
-
Gundam: Dynamic resolution mode for even higher input resolutions, with block-based processing to further reduce activation memory.
-
Decoder: DeepSeek-3B-MoE-A570M
The decoder is based on the DeepSeek-3B-MoE architecture with 570M active parameters. It decodes compressed visual tokens into text via nonlinear mapping:
fdec:Rn×dlatent→RN×dtextfdec:Rn×dlatent→RN×dtext
where n is the number of visual tokens, N is the number of text tokens, and dₗₐₜₑₙₜ and dₜₑₓₜ represent the dimensions of the visual and text tokens respectively.
Project Links
-
GitHub Repository: https://github.com/deepseek-ai/DeepSeek-OCR
-
Hugging Face Model Hub: https://huggingface.co/deepseek-ai/DeepSeek-OCR
-
Technical Paper: DeepSeek_OCR_paper.pdf
Application Scenarios
-
Large-Scale Training Data Generation: Automatically processes hundreds of thousands of document pages daily, generating high-quality datasets for large language and vision-language models.
-
Enterprise Document Digitization: Rapidly converts paper-based contracts, reports, and other corporate documents into searchable, editable digital formats.
-
Academic Research and Literature Processing: Accurately parses complex academic content such as mathematical equations, chemical formulas, and figures into structured, machine-readable data.
-
Multilingual Global Document Handling: Efficiently manages multilingual document workflows for multinational enterprises and global organizations.
-
Financial and Business Intelligence Analysis: Deeply analyzes research report charts and converts them into structured data to support automated financial analysis and investment decision-making.