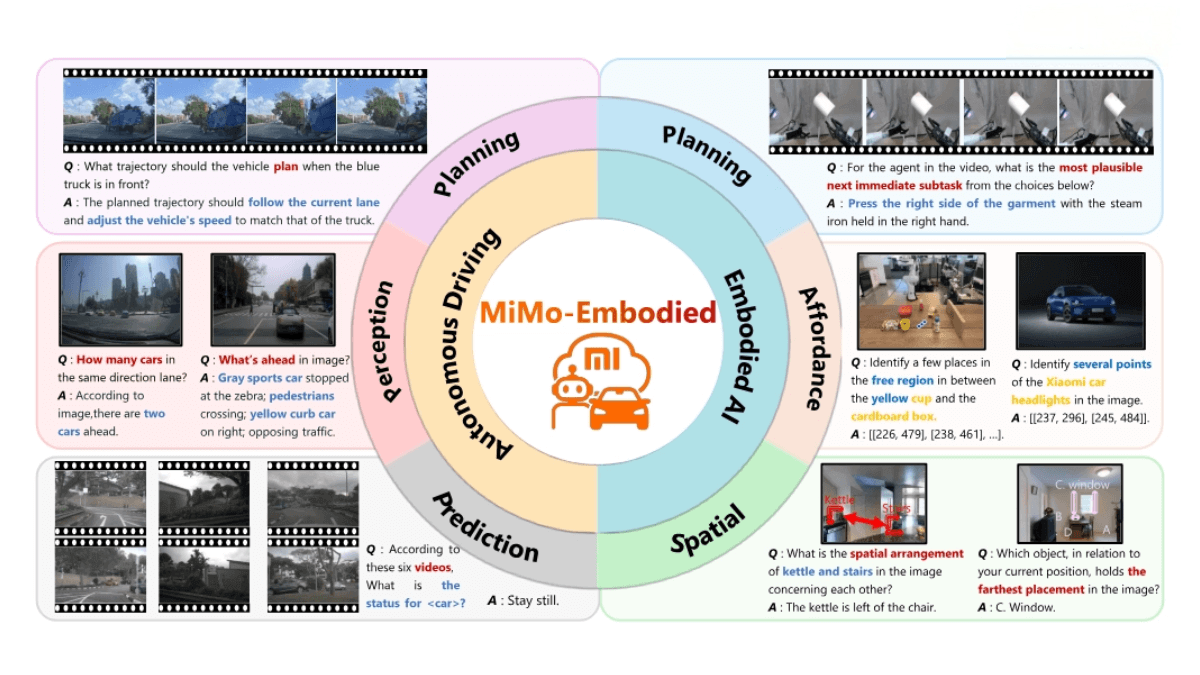
What is MiMo-Embodied?
MiMo-Embodied is the world’s first open-source cross-domain embodied AI model released by Xiaomi, integrating tasks from both autonomous driving and embodied intelligence. It delivers exceptional performance in environment perception, task planning, and spatial understanding.
Built on a Vision-Language Model (VLM) architecture, MiMo-Embodied uses a four-stage training pipeline—embodied intelligence supervised fine-tuning, autonomous driving supervised fine-tuning, chain-of-thought reasoning fine-tuning, and reinforcement learning fine-tuning—to significantly enhance cross-domain generalization.
In autonomous driving scenarios, MiMo-Embodied can accurately perceive road environments, predict behaviors of dynamic agents, and generate safe and efficient driving plans. In embodied intelligence scenarios, it can interpret natural language instructions and perform complex task planning and spatial reasoning.
MiMo-Embodied surpasses existing open-source and commercial specialized models across multiple benchmarks, demonstrating powerful multimodal interaction capabilities.
Key Features of MiMo-Embodied
Cross-Domain Integration
MiMo-Embodied is the first model to successfully unify autonomous driving and embodied intelligence tasks, covering core capabilities such as environment perception, task planning, and spatial understanding—ideal for multimodal interaction in complex, dynamic environments.
Environment Perception
In autonomous driving, the model accurately interprets traffic scenes, including recognizing road signs, vehicles, pedestrians, and predicting their future behavior, enabling safer driving decisions.
Task Planning and Execution
In embodied intelligence, MiMo-Embodied can generate executable action sequences based on natural language instructions, handling complex tasks such as robotic navigation and manipulation.
Spatial Understanding and Reasoning
The model has strong spatial reasoning abilities, understanding spatial relationships between objects—supporting navigation, interaction, scene understanding, and path planning in robotics and autonomous driving.
Multimodal Interaction
By deeply integrating vision and language, MiMo-Embodied can process images, videos, and text, enabling multimodal tasks such as visual question answering (VQA), instruction following, and scene description.
Reinforcement Learning Optimization
Reinforcement learning fine-tuning enhances the model’s decision-making and reliability in complex environments, enabling efficient deployment in real-world scenarios.
Open-Source and General-Purpose
MiMo-Embodied is fully open-source, with code and models available on Hugging Face—providing researchers and developers with a powerful tool to drive innovation in embodied AI and autonomous driving.
Technical Principles of MiMo-Embodied
Cross-Domain Fusion Architecture
The model adopts a unified VLM architecture that integrates autonomous driving and embodied intelligence tasks using a vision encoder, projection module, and large language model (LLM), enabling deep fusion of visual input and textual understanding.
Multi-Stage Training Pipeline
MiMo-Embodied improves performance through four training stages: embodied intelligence supervised fine-tuning, autonomous driving supervised fine-tuning, chain-of-thought reasoning fine-tuning, and reinforcement learning fine-tuning—ensuring robust generalization across tasks and domains.
Visual Input Processing
Visual features from single images, multi-view inputs, or videos are extracted using a Vision Transformer (ViT) and mapped into an LLM-aligned latent space via an MLP projection module, enabling seamless vision-language integration.
Data-Driven Cross-Domain Learning
A diverse dataset—covering general vision-language understanding, embodied intelligence, and autonomous driving—provides rich multimodal supervision, supporting learning from basic perception to advanced reasoning.
Reinforcement Learning Optimization
In the final stage, the model is refined using Group Relative Policy Optimization (GRPO), enhancing decision quality and reliability in complex and edge-case scenarios.
Inference and Output Generation
Leveraging LLM reasoning, MiMo-Embodied combines visual inputs and natural language instructions to generate task-relevant responses and decisions, supporting driving planning and embodied task execution.
Project Links for MiMo-Embodied
-
GitHub Repository: https://github.com/XiaomiMiMo/MiMo-Embodied
-
HuggingFace Model Hub: https://huggingface.co/XiaomiMiMo/MiMo-Embodied-7B
-
arXiv Technical Paper: https://arxiv.org/pdf/2511.16518
Application Scenarios of MiMo-Embodied
Autonomous Driving
Handles complex traffic scenarios, including perception, state prediction, and driving planning—applicable to urban roads, highways, and other autonomous driving environments.
Robot Navigation and Manipulation
In embodied intelligence, MiMo-Embodied performs indoor navigation and object manipulation based on natural language instructions, enabling autonomous operation in home and industrial settings.
Visual Question Answering and Interaction
Capable of visual question answering by understanding image or video content, supporting human-AI interaction, information retrieval, and explanation tasks.
Scene Understanding and Description
Generates semantic understanding and descriptions of complex scenes—useful for surveillance, smart transportation, and scene analysis.
Multimodal Task Execution
Supports cross-modal inputs (image, video, text) for tasks such as instruction following, image annotation, and automated assistant workflows.
Task Planning in Complex Environments
Generates multi-step task plans based on instructions, enabling robots to complete complex tasks such as cleaning or cooking.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts



No comments yet...