Amodal3R – A Conditional 3D Generation Model Jointly Launched by Nanyang Technological University, Oxford, and Others
What is Amodal3R?
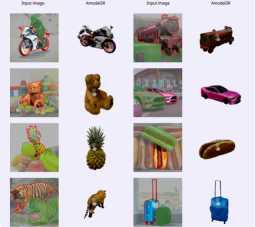
Amodal3R is a conditional 3D generative model capable of inferring and reconstructing the complete 3D shape and appearance from partially visible 2D object images. The model is built upon the “foundation” 3D generative model TRELLIS and incorporates a mask-weighted multi-head cross-attention mechanism and an occlusion-aware attention layer, leveraging occlusion prior knowledge to guide the reconstruction process. Trained solely on synthetic data, Amodal3R demonstrates exceptional performance in real-world scenarios, significantly outperforming the existing “2D prediction completion + 3D reconstruction” two-step approach and setting a new benchmark for 3D reconstruction in occluded scenes.
The main functions of Amodal3R
- Occlusion-aware 3D Reconstruction: For 2D images with severe occlusion, Amodal3R can generate complete 3D models by combining 2D fragment information with semantic inference.
- Surpassing Existing Methods: Compared to the “2D prediction completion + 3D reconstruction” two-step approach, Amodal3R performs better in occluded scenarios and establishes a new benchmark for 3D reconstruction.
The technical principles of Amodal3R
- Basic 3D Generative Model Extension: Amodal3R starts from a “basic” 3D generative model and, through expansion, can handle occluded 2D images to recover reasonable 3D geometric shapes and appearances.
- Masked Weighted Multi-Head Cross-Attention Mechanism: The model incorporates a masked weighted multi-head cross-attention mechanism, which better addresses the occlusion problem. Specifically, the attention mechanism is guided by masks, enabling the model to focus more on visible parts during generation and utilize occlusion priors to infer the shape and texture of occluded regions.
- Occlusion-Aware Attention Layer: Following the masked weighted multi-head cross-attention mechanism, Amodal3R introduces an occlusion-aware attention layer.
- Feature Extraction Based on DINOv2: Amodal3R leverages DINOv2 for high-quality visual feature extraction. The features provided by DINOv2 offer additional contextual information for 3D reconstruction, helping the model perform 3D reconstruction more accurately.
- Synthetic Data Training and Generalization Ability: Amodal3R is trained solely on synthetic data and demonstrates the ability to recover complete 3D objects in real-world scenarios, even in the presence of occlusions. This indicates that the model possesses strong generalization capabilities, enabling it to apply knowledge learned from synthetic data to real-world situations.
The project address of Amodal3R
- Project official website: https://sm0kywu.github.io/Amodal3R/
- Hugging Face model hub: https://huggingface.co/Sm0kyWu/Amodal3R
- arXiv technical paper: https://arxiv.org/pdf/2503.13439
Application scenarios of Amodal3R
- Augmented Reality (AR) and Virtual Reality (VR): In AR and VR applications, Amodal3R can help reconstruct complete 3D models from partially visible 2D images, providing a more immersive experience.
- Robotic Vision: When robots operate in complex environments, they often encounter situations where objects are partially occluded. Amodal3R can help robots more accurately perceive and understand the objects in the environment, enabling better path planning and task execution.
- Autonomous Driving: In the field of autonomous driving, vehicles need to perceive objects in the surrounding environment in real time. Amodal3R can reconstruct complete 3D models from partially occluded images, helping autonomous driving systems more accurately recognize and handle complex traffic scenarios.
- 3D Asset Creation: In industries such as game development and film production that require 3D assets, Amodal3R can generate high-quality 3D models from simple 2D images, simplifying the 3D modeling process.
- Academic Research: Amodal3R provides new tools and methods for research in the fields of computer vision and 3D reconstruction. Researchers can use the model to explore more complex scenes and develop more efficient reconstruction algorithms.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...