
Seed-Thinking-v1.5 – The Latest Thinking Model Launched by ByteDance
What is Seed-Thinking-v1.5?
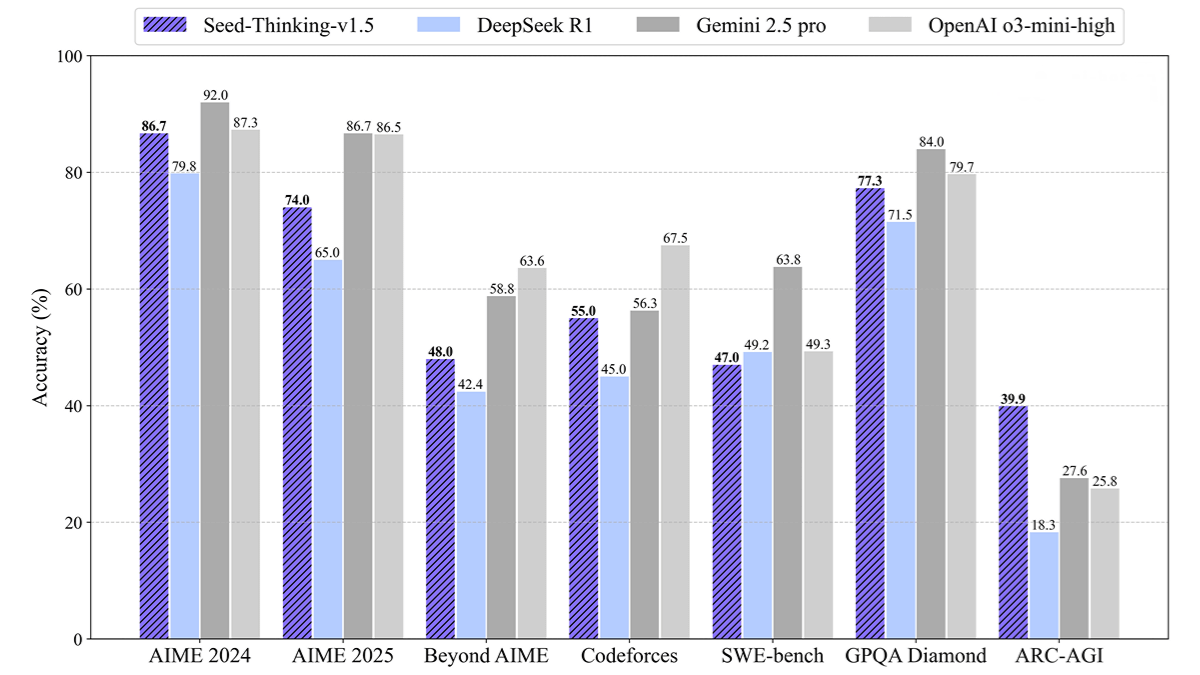
Seed-Thinking-v1.5 is an inference intelligent model launched by ByteDance. It adopts a Mixture of Experts (MoE) architecture, with a total of 200B parameters and 20B parameters activated each time. The model performs excellently in multiple benchmark tests. For example, it achieved a score of 86.7 on the AIME 2024 test, a pass@8 metric of 55.0 on the Codeforces evaluation, and a score of 77.3 on the GPQA test. It also shows a higher win rate than DeepSeek R1 by 8% in non-inference tasks, demonstrating its wide applicability. The development of Seed-Thinking-v1.5 involved carefully curated training data, an advanced reinforcement learning framework, a two-layer reward system, and efficient infrastructure. The model will open its API for users to experience through Volcano Engine on April 17.
The main functions of Seed-Thinking-v1.5
- Outstanding Reasoning Ability: Seed-Thinking-v1.5 demonstrates excellent performance in multiple authoritative benchmark tests. For instance, it achieved a score of 86.7 on the AIME 2024 test, a pass@8 metric of 55.0% on Codeforces evaluations, and a score of 77.3 on the GPQA test. These results indicate its strong reasoning capabilities in STEM (Science, Technology, Engineering, and Mathematics) fields as well as in programming.
- Broad Generalization Ability: The model also excels in non-reasoning tasks, achieving an 8% higher win rate compared to DeepSeek R1, showcasing its advantage in handling complex user scenarios.
- Efficient Infrastructure: To support large-scale training, Seed-Thinking-v1.5 employs the HybridFlow programming model and a Streaming Reasoning System (SRS). Its three-layer parallel architecture (tensor/expert/sequence parallelism) optimizes training efficiency.
The Technical Principles of Seed-Thinking-v1.5
- Hybrid Expert Model (MoE) Architecture: Seed-Thinking-v1.5 adopts the Mixture-of-Experts (MoE) architecture, with a total of 200B parameters and 20B parameters activated each time. While maintaining high performance, it significantly reduces the consumption of computational resources and improves the efficiency of the model.
- Reinforcement Learning Algorithms
◦ VAPO and DAPO Frameworks: To address the instability issues in reinforcement learning training, the research team proposed two frameworks, VAPO (for Actor-Critic) and DAPO (for Policy Gradient). These methods provide robust training trajectories and effectively optimize the inference model.
◦ Reward Modeling: The team designed two reward modeling schemes, Seed-Verifier and Seed-Thinking-Verifier. Seed-Thinking-Verifier addresses issues such as reward deception, prediction uncertainty, and failure in handling edge cases through a detailed reasoning process. - Data Processing and Enhancement
◦ Verifiable Questions: These include math, programming, and logic puzzles. Through strict screening and enhancement (e.g., converting multiple-choice questions into fill-in-the-blank questions), we ensure that the model learns genuine reasoning abilities.
◦ Non-verifiable Questions: These include creative writing and dialogue. By dynamically filtering out low-variance samples, we prevent the model from getting stuck in local optimization.
◦ Data Augmentation Strategies: For example, using the model to generate candidate answers and combining them with human verification to correct incorrect reference answers, thereby improving data reliability. - Distributed Training Infrastructure
◦ Hybrid Parallel Architecture: Combines Tensor Parallelism (TP), Expert Parallelism (EP), and Pipeline Parallelism (CP) to support efficient large-scale training.
◦ Streaming Generation System (SRS): Enhances the efficiency of long-text generation by 3x through asynchronous processing and dynamic resource scheduling, addressing the “tail latency problem” of traditional synchronous frameworks.
◦ Automatic Tuning System: Dynamically selects the optimal computation configuration based on real-time workload to balance memory and compute resources.
Project address of Seed-Thinking-v1.5
- Github Repository: https://github.com/ByteDance-Seed/Seed-Thinking-v1.5
Performance of Seed-Thinking-v1.5
- Mathematical Reasoning: Achieved a score of 86.7 in the AIME 2024 test, on par with OpenAI’s o3-mini-high.
- Programming Tasks: Achieved a pass@8 rate of 55.0% in Codeforces evaluations, outperforming DeepSeek-R1.
- Science QA: Attained an accuracy rate of 77.3% in the GPQA test, approaching the level of top-tier models.
- Non-reasoning Tasks: Demonstrated stronger generalization ability, with a win rate 8% higher than DeepSeek-R1 in non-reasoning tasks.
Application Scenarios of Seed-Thinking-v1.5
- Scientific Q&A: Seed-Thinking-v1.5 also demonstrates remarkable performance in scientific question answering. The model can understand and answer complex questions involving scientific concepts and principles, making it suitable for education and research fields.
- Creative Writing: The model is capable of generating cross-temporal dialogues, such as simulating the inner monologues of historical figures or crafting narratives that integrate terminology from different domains. It has potential applications in content creation, advertising, scriptwriting, and other fields.
- Logical Reasoning: Seed-Thinking-v1.5 has significant advantages in handling questions that require logical analysis and reasoning. It is applicable to scenarios that demand logical judgment and analysis, such as legal analysis and market strategy planning.
- Educational Assistance: Seed-Thinking-v1.5’s reasoning abilities can help students solve math and science problems, provide feedback on programming exercises, and assist with language learning.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts



No comments yet...