
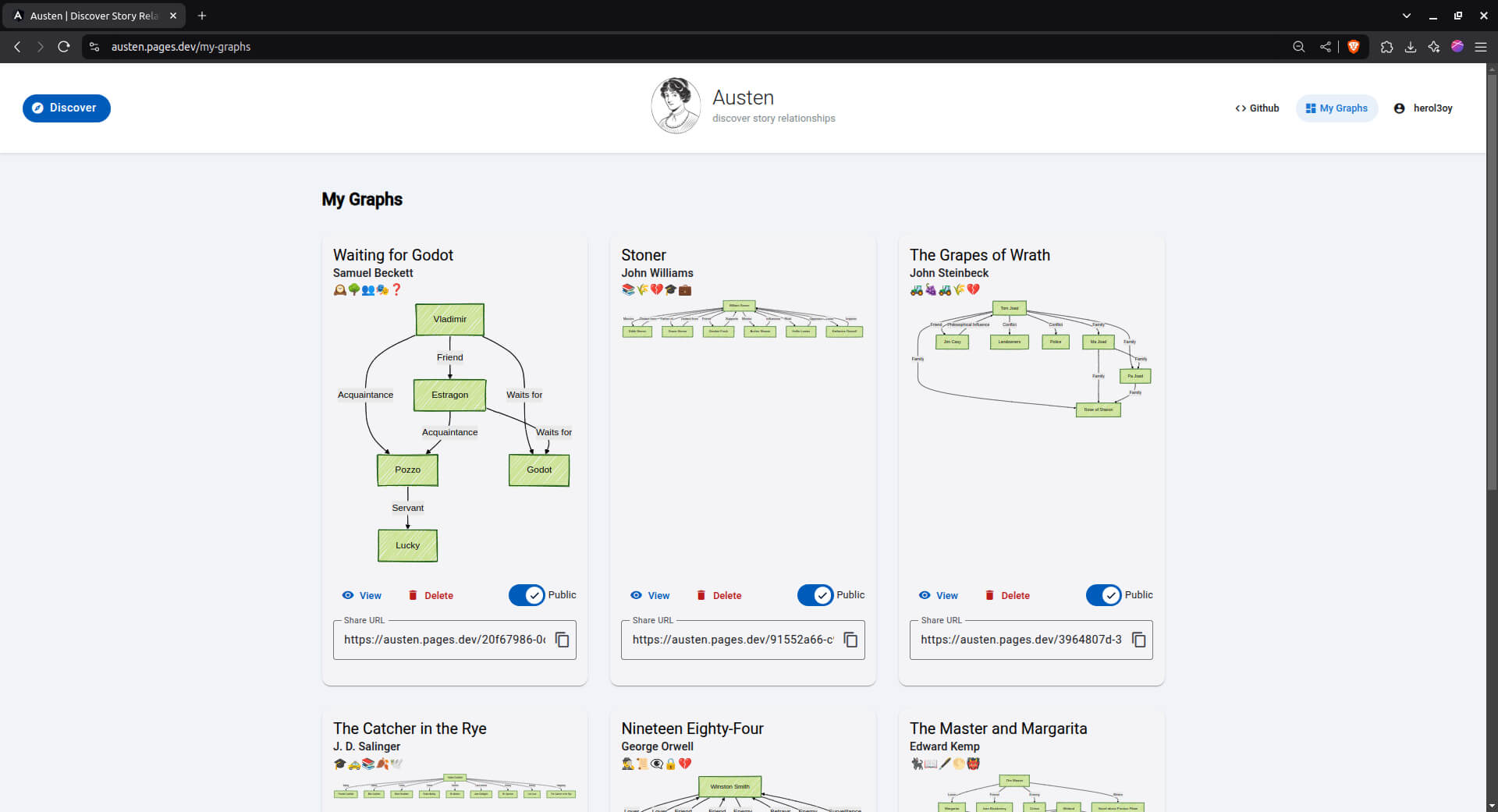
AI-Powered Austen: Instantly Decode Character Relationships, Unlock Immersive Reading Experience
What is Austen?
Austen is an open-source text processing and analysis project hosted on GitHub, named after the renowned author Jane Austen, symbolizing its focus on literary text processing with elegance. The project aims to provide developers and researchers with a powerful toolkit for handling, analyzing, and understanding various types of textual data.
As a practical tool in the field of modern Natural Language Processing (NLP), Austen combines advanced algorithms with user-friendly interfaces, making text analysis more accessible. Whether for academic research or commercial applications, Austen offers reliable support.
Key Features
The Austen project includes a range of practical text processing and analysis functions:
-
Text Cleaning & Preprocessing: Automatically removes irrelevant characters, standardizes text formats, and handles special symbols to provide clean data for further analysis.
-
Word Frequency Analysis: Calculates word occurrence rates, identifying keywords and core concepts in texts.
-
Sentiment Analysis: Evaluates the emotional tone of text, determining whether content is positive, negative, or neutral.
-
Topic Modeling: Uses advanced algorithms (e.g., LDA) to automatically identify latent topics in texts.
-
Text Similarity Calculation: Compares the similarity between different texts, useful for plagiarism detection or content recommendations.
-
Named Entity Recognition (NER): Automatically identifies entities such as names, locations, and organizations in texts.
-
Text Summarization: Extracts key information from long texts to generate concise summaries.
-
Multilingual Support: Although named after English literature, the project supports text processing in multiple languages.
Technical Principles
The Austen project integrates various modern NLP technologies:
-
Python Foundation: Primarily developed in Python, leveraging its rich ecosystem of text-processing libraries.
-
NLTK & spaCy: These powerful NLP libraries form Austen’s core processing capabilities, providing tokenization, part-of-speech tagging, and syntactic analysis.
-
Machine Learning Algorithms: Incorporates various ML models for advanced functions like sentiment analysis and topic classification.
-
Deep Learning Frameworks: Some advanced features may use deep learning models built with TensorFlow or PyTorch.
-
Distributed Computing: For large-scale text processing, the project may employ distributed computing to enhance efficiency.
-
RESTful API Design: Likely provides API interfaces for easy integration with other systems.
Project Repository
- GitHub Repository: https://github.com/herol3oy/austen
Application Scenarios
Austen’s versatility makes it suitable for various use cases:
-
Academic Research: Text data processing in literary analysis, linguistics, and social science studies.
-
Content Marketing: Analyzing user reviews, social media feedback, and assessing brand reputation.
-
Education: Automated grading systems, plagiarism detection, and student assignment analysis.
-
News Media: Categorizing news articles, generating summaries, and tracking trending topics.
-
Customer Service: Analyzing customer inquiries and complaints, automating classification and prioritization.
-
Legal Industry: Processing large volumes of legal documents and extracting key case precedents.
-
Human Resources: Analyzing resumes and cover letters to match job requirements.
-
Healthcare: Processing medical records and clinical notes to extract critical health information.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...