
NodeRAG: Pioneering Retrieval-Augmented Generation through Graph Structure Innovation
Among numerous Retrieval-Augmented Generation (RAG) methods, NodeRAG stands out with its unique graph structure framework. Leveraging a heterogeneous graph structure and an advanced retrieval mechanism, NodeRAG provides Large Language Models (LLMs) with more accurate and efficient external knowledge support. This article will delve into the core features, advantages of NodeRAG, and its outstanding performance in multiple fields.
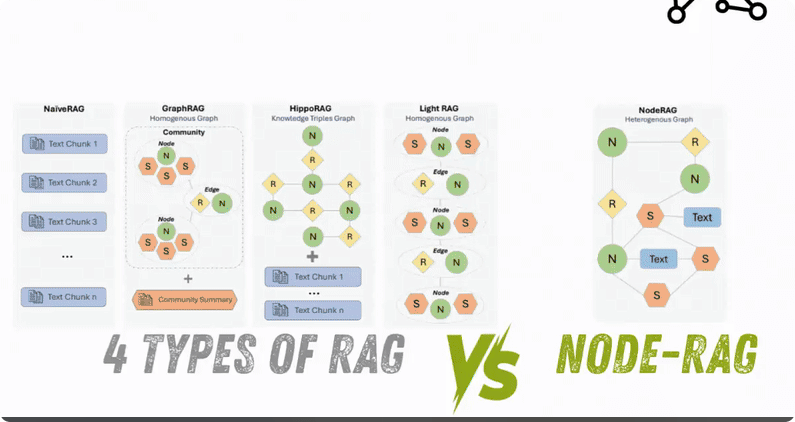
What is NodeRAG?
NodeRAG is a graph-centric Retrieval-Augmented Generation (RAG) framework designed to structure graph-based retrieval through heterogeneous node representations. It decomposes documents and information extracted by LLMs into diverse node types, including entities, relationships, semantic units, attributes, high-level elements, overviews, and text. By leveraging graph algorithms to optimize the information retrieval process, this approach not only enhances retrieval precision but also improves response interpretability. NodeRAG is particularly well-suited for tasks requiring multi-hop reasoning and complex contextual understanding.
Unlike traditional RAG methods (such as NaiveRAG), which only retrieve text fragments, NodeRAG organizes information in a graphical way, addressing the issues of precision and reasoning in complex queries. Studies have shown that NodeRAG outperforms methods such as GraphRAG, LightRAG, NaiveRAG, and HyDE across multiple benchmark tests and domains, becoming the new benchmark for RAG technology.
The core features of NodeRAG
The success of NodeRAG can be attributed to its innovative graph structure design and retrieval mechanism. The following are its four key steps and their functions:
1. Graph Decomposition
NodeRAG first decomposes the original text into intelligently constructed modules:
• Semantic Units (S): Small event fragments, such as “Hinton won the Nobel Prize”.
• Entities (N): Key names or concepts, like “Hinton” or “the Nobel Prize”.
• Relations (R): Connections between entities, such as “awarded”.
This decomposition is similar to teaching AI to identify the “characters, actions, and scenes” in a document, laying a structured foundation for subsequent processing.
2. Graph Augmentation
The decomposed graph needs further optimization. NodeRAG enhances the graph structure in the following ways:
• Node Importance Assessment: Use the K-Core and Betweenness Centrality algorithms to identify key nodes. The attributes of important entities are summarized as new nodes (A).
• Community Detection: Group related nodes into communities and generate high-level insight nodes (H).
• Overview Nodes (O): Generate “headline”-style overview nodes for each community to facilitate quick retrieval.
This process is similar to adding context and intuition to the original facts, making the graph structure more insightful.
3. Graph Enrichment
Knowledge appears fragile when it lacks details. NodeRAG enriches the graph structure in the following ways:
• Original Text Linking: Link complete text fragments back to the graph (text nodes, T).
• Semantic Edges: Use the Hierarchical Navigable Small World (HNSW) algorithm to establish fast and semantically relevant connections.
• Efficient Storage: Embed only important nodes, significantly saving storage space.
• Dual Search: Combine exact matching and vector search to ensure precise retrieval.
This is like upgrading a two – dimensional map to a three – dimensional living world, making the information richer and more accessible.
4. Graph Searching
The retrieval process of NodeRAG can be regarded as its “magic”:
• Dual Search: First, find strong entry points through names or semantics.
• Shallow Personalized PageRank (PPR): Carefully expand from the entry points to nearby relevant nodes with limited iterations (by default, α = 0.5 and t = 2) to avoid interference from irrelevant information.
• Precise Retrieval: The retrieval results include fine-grained semantic units, attributes, and high-level elements, ensuring that the required information is provided without any redundant content.
This is like dispatching intelligent agents into a city. They only bring back the information you need, with a clear structure and comprehensive summary.
The performance advantages of NodeRAG
NodeRAG demonstrates exceptional performance across multiple benchmark tests and domains. Below is a comparison of its performance with GraphRAG, LightRAG, NaiveRAG, and HyDE:
| Metric | HotpotQA | MuSiQue | MultiHop-RAG | RAG-QA Arena (Domain) |
|---|---|---|---|---|
| Accuracy (%) | 89.50 (GraphRAG 89.00) | 46.29 (GraphRAG 41.71, LightRAG 36.00) | 0.57 (GraphRAG 0.53, LightRAG 0.50) | 0.794-0.977 (Lifestyle 0.949 vs. GraphRAG 0.863) |
| Retrieval Tokens | 5.0k (GraphRAG 6.6k, LightRAG 7.1k) | 5.9k (GraphRAG 6.6k, LightRAG 7.4k) | 6.1k (GraphRAG 7.4k, LightRAG 7.9k) | 3.3k-4.2k (Lifestyle 3.3k vs. GraphRAG 6.8k) |
| Indexing Time (min) | 21 (GraphRAG 66, LightRAG 39) | 25 (GraphRAG 76, LightRAG 90) | 24 (GraphRAG 50, LightRAG 58) | 13-19 (Writing 13 vs. GraphRAG 50) |
| Storage Usage (MB) | 214 (GraphRAG 227/461, LightRAG 461) | 250 (GraphRAG 255/492, LightRAG 492) | 137 (GraphRAG 141/276, LightRAG 276) | 117-157 (FiQA 117 vs. GraphRAG 240) |
| Query Time (sec) | 3.98 (GraphRAG 2.66/26.69, LightRAG 5.58) | 4.05 (GraphRAG 2.94/22.65, LightRAG 6.53) | 4.89 (GraphRAG 4.15/34, LightRAG 7.10) | 5.40-8.86 (Writing 5.40 vs. GraphRAG 40.11) |
paired comparison
In the pairwise comparisons across six domains (FiQA, leisure, writing, lifestyle, science, and technology), NodeRAG demonstrates a significantly higher win rate compared to other methods:
• Against GraphRAG: 0.640 in lifestyle, 0.520 in FiQA.
• Against LightRAG: 0.623 in lifestyle, 0.486 in FiQA.
• Against NaiveRAG: 0.800 in lifestyle, 0.749 in FiQA.
• Against HyDE: 0.526 in lifestyle, 0.531 in FiQA.
ablation study
The ablation study further verifies the importance of the key components of NodeRAG:
• After removing the HNSW semantic edges, the accuracy of MuSiQue dropped to 41.71% (from 46.29%), and the number of tokens increased to 6.78k (from 5.96k).
• After removing dual search, the accuracy dropped to 44.57%, and the number of tokens increased to 9.7k.
Applicable fields
NodeRAG demonstrates outstanding performance in the following fields:
• Technology: Handling technical documents and complex queries.
• Science: Supporting academic research and multi-hop reasoning.
• Writing: Generating structured and context-rich texts.
• Leisure: Optimizing entertainment content recommendation and analysis.
• Finance: Providing precise financial data insights.
The success in these fields indicates that NodeRAG can adapt to a wide variety of knowledge-intensive tasks, offering strong support for enterprises and researchers.
Why Choose NodeRAG?
Traditional RAG methods often fall short when it comes to handling complex reasoning and multi – hop understanding. However, NodeRAG addresses these issues with its graph – based approach:
• Higher accuracy: By leveraging fine – grained retrieval and multi – hop reasoning, NodeRAG delivers more precise responses.
• Lower resource consumption: Its optimized storage and indexing mechanisms make it more suitable for large – scale applications.
• Better interpretability: The structured graph retrieval process makes the results easier to understand and verify.
NodeRAG is not just a superior graph structure; it’s more like a new “operating system” for memory, offering a brand – new paradigm for AI’s knowledge processing.
Conclusion
NodeRAG has set a new benchmark in the field of retrieval – augmented generation with its innovative heterogeneous graph structure and advanced retrieval mechanism. Whether in academic research, content creation, or financial analysis, NodeRAG can provide accurate, context – aware responses, facilitating the in – depth application of AI in various fields.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...