Kimi – Audio – An open – source audio foundational model by Moonshot AI
What is Kimi-Audio?
Kimi-Audio is an open-source audio foundation model launched by Moonshot AI, focusing on audio understanding, generation, and conversational tasks. Pretrained on over 13 million hours of diverse audio data, it possesses strong audio reasoning and language comprehension capabilities. The core architecture adopts a hybrid audio input (continuous acoustic + discrete semantic tokens) and combines a large language model (LLM)-based design. It supports parallel generation of text and audio tokens and achieves low-latency audio generation through a chunk-based streaming decoder.
Main Features of Kimi-Audio
-
Speech Recognition (ASR): Converts speech signals into text, supporting multiple languages and dialects.
-
Speech Emotion Recognition (SER): Analyzes emotional information in speech and determines the speaker’s emotional state (e.g., happy, sad, angry), useful in customer service systems and emotional analysis.
-
Sound Event/Scene Classification (SEC/ASC): Recognizes and classifies environmental sounds (e.g., car horn, dog barking, rain) or scenes (e.g., office, street, forest).
-
Audio Captioning (AAC): Automatically generates captions for audio content, helping people with hearing impairments better understand audio information.
-
Audio Question Answering (AQA): Generates corresponding audio answers based on user questions.
-
End-to-End Speech Conversation: Supports generating natural and fluent speech conversation content.
-
Multi-turn Dialogue Management: Handles complex multi-turn dialogue tasks, understanding contextual information and generating coherent speech responses.
-
Text-to-Speech (TTS): Converts text into natural, fluent speech, supporting various voices and tones.
-
Audio Content Analysis: Performs comprehensive analysis of audio for semantics, emotions, events, etc., to extract key information.
-
Audio Quality Assessment: Analyzes the clarity and noise levels of audio, providing references for audio processing.
Technical Principles of Kimi-Audio
-
Hybrid Audio Input: Kimi-Audio adopts a hybrid audio input approach, dividing the input audio into two parts:
-
Discrete Semantic Tokens: Audio is converted into discrete semantic tokens using vector quantization at a frequency of 12.5Hz.
-
Continuous Acoustic Features: Acoustic features are extracted using the Whisper encoder and downsampled to 12.5Hz. This hybrid input method combines both discrete semantic and continuous acoustic information, enabling the model to more comprehensively understand and process audio content.
-
-
LLM-Based Core Architecture: The core of Kimi-Audio is based on a Transformer language model (LLM), initialized from a pre-trained text LLM (e.g., Qwen 2.5 7B).
-
Chunked Streaming Decoder: Kimi-Audio uses a chunk-based streaming decoder based on flow matching, enabling low-latency audio generation. The model processes audio data in chunks, allowing real-time output during generation, significantly reducing latency. A lookahead mechanism further optimizes the smoothness and coherence of audio generation.
-
Large-Scale Pretraining: Kimi-Audio was pre-trained on over 13 million hours of diverse audio data (including speech, music, and various sounds). This gives the model strong audio reasoning and language comprehension abilities, capable of handling various complex audio tasks like speech recognition, audio question answering, and emotion recognition.
-
Flow Matching Model: Used to convert discrete tokens into continuous audio signals.
-
Vocoder (BigVGAN): Used to generate high-quality audio waveforms, ensuring the naturalness and smoothness of generated audio.
Kimi-Audio Project Repository
-
GitHub Repository: https://github.com/MoonshotAI/Kimi-Audio
Performance of Kimi-Audio
-
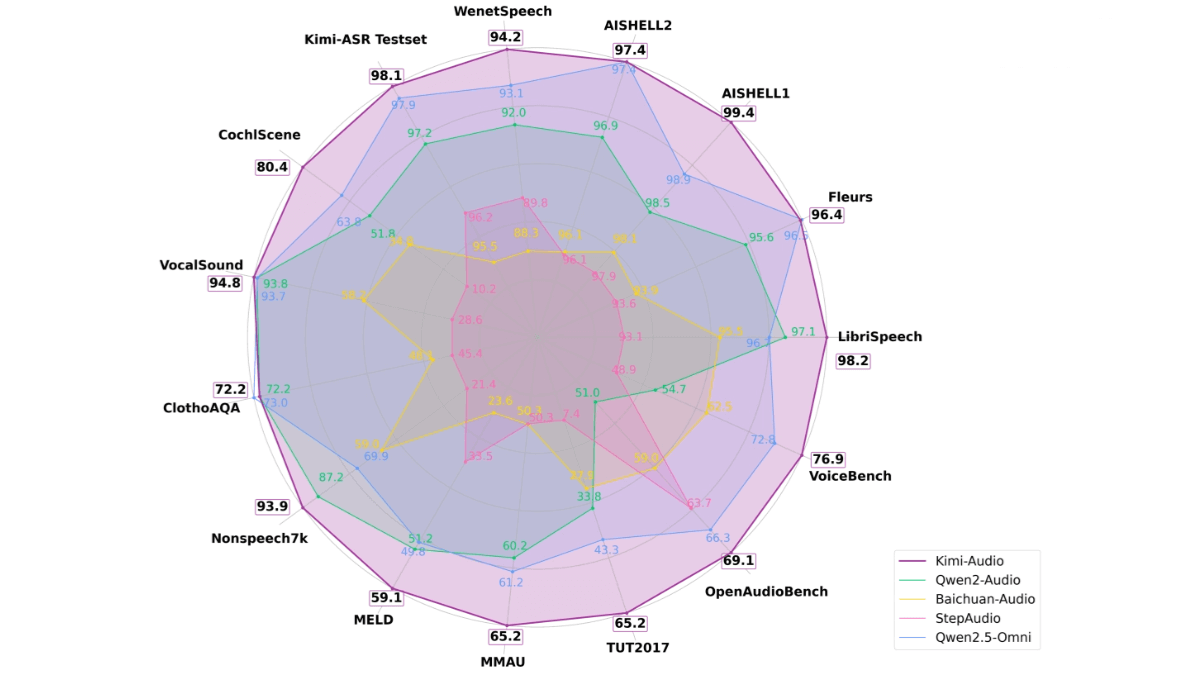
Speech Recognition (ASR): On the LibriSpeech test set, Kimi-Audio achieves a word error rate (WER) of 1.28% (test-clean) and 2.42% (test-other), significantly lower than other models. On the AISHELL-1 dataset, its WER is only 0.60%, showing excellent performance.
-
Audio Understanding: In audio understanding tasks, Kimi-Audio achieves near or state-of-the-art results on multiple datasets. For example, on the ClothoAQA dataset, its performance on the test set reached 73.18%, and on the VocalSound dataset, its accuracy reached 94.85%.
-
Audio Question Answering (AQA): In the audio question answering task, Kimi-Audio achieved an accuracy of 73.18% on the ClothoAQA development set, demonstrating its strong capability in understanding and generating audio question answering content.
-
Audio Dialogue: In speech dialogue tasks, Kimi-Audio performs well in several benchmark tests. For instance, on the VoiceBench AlpacaEval dataset, its performance reached 75.73%, excelling in the fluency and coherence of speech dialogues.
-
Audio Generation: Kimi-Audio also performs excellently in non-speech audio generation. On the Nonspeech7k dataset, its accuracy reached 93.93%, demonstrating its ability to generate high-quality audio content.
Applications of Kimi-Audio
-
Smart Voice Assistants: Kimi-Audio can be used to develop smart voice assistants, supporting speech recognition, speech synthesis, and multi-turn dialogue capabilities. It can understand user voice commands and generate natural, fluent speech responses.
-
Speech Recognition and Transcription: Kimi-Audio can efficiently convert speech signals into text, supporting various languages and dialects, suitable for meeting minutes, voice notes, real-time translation, etc.
-
Audio Content Generation: Kimi-Audio can generate high-quality audio content, including text-to-speech (TTS), audio captioning (AAC), and audio question answering (AQA). It can generate natural, fluent speech from text and audio answers from questions, applicable in areas like audiobooks, video captioning, and intelligent customer service.
-
Emotion Analysis and Speech Emotion Recognition: Kimi-Audio can analyze emotional information in speech, determining the speaker’s emotional state (e.g., happy, sad, angry).
-
Education and Learning: Kimi-Audio has various applications in education, such as English speaking practice, language learning assistance, etc. It can help users practice pronunciation, correct grammar mistakes, and provide real-time feedback through voice interaction.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...