
Qwen2.5-Omni-3B – A lightweight multimodal AI model launched by Alibaba’s Qwen team.
What is Qwen2.5-Omni-3B
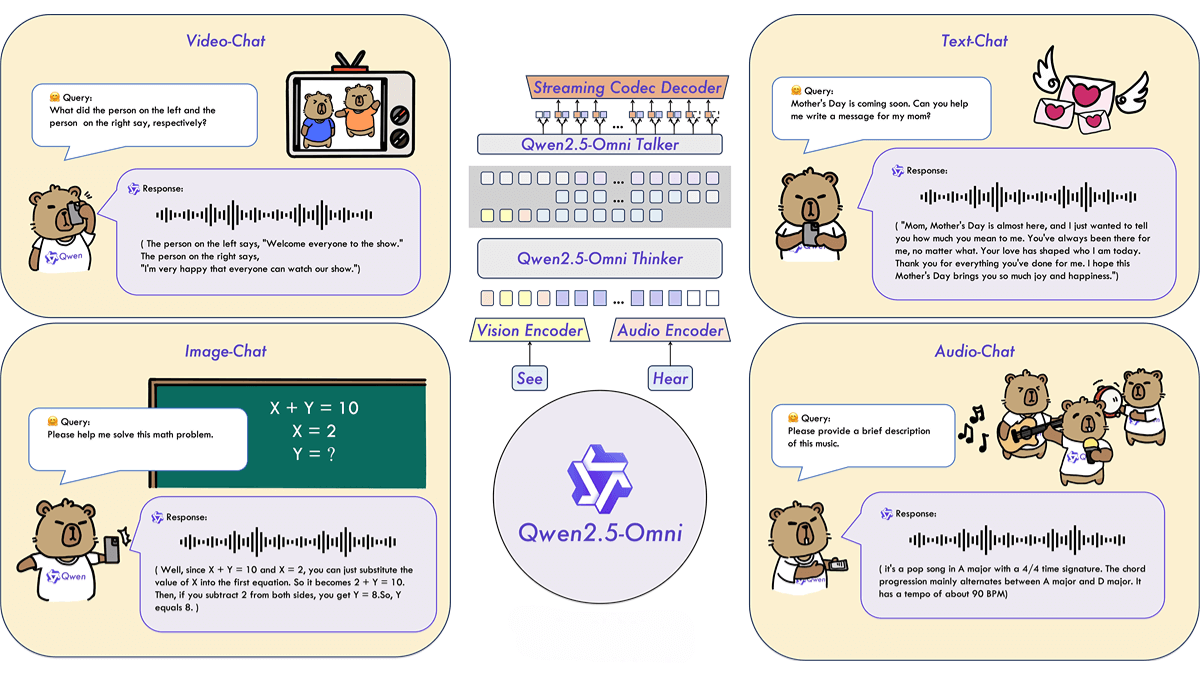
Qwen2.5-Omni-3B is a lightweight multimodal AI model developed by Alibaba’s Qwen team. It is a streamlined version of the Qwen2.5-Omni-7B model, designed specifically for consumer-grade hardware. It supports various input types including text, audio, image, and video. Despite reducing the parameter count from 7B to 3B, it retains over 90% of the multimodal performance of the 7B model. It excels in real-time text generation and natural speech output. When processing long-context inputs of up to 25,000 tokens, its memory usage is reduced by 53%, from 60.2GB to 28.2GB, enabling it to run on devices with 24GB GPUs.
Key Features of Qwen2.5-Omni-3B
• Multimodal Input & Real-Time Response: Supports text, audio, image, and video inputs with real-time text generation and natural speech responses.
• Custom Voice Output: Offers two built-in voices — Chelsie (female) and Ethan (male), for different applications or audience preferences.
• Memory Optimization: Reduces memory usage from 60.2GB (in 7B) to 28.2GB for long-context input (25,000 tokens), enabling deployment on 24GB GPU hardware.
• Architectural Innovations: Implements the Thinker-Talker design and a customized positional embedding technique, TMRoPE, to synchronize understanding of video and audio inputs.
• Optimization Support: Compatible with FlashAttention 2 and BF16 precision, improving performance and reducing memory usage.
• Performance: Achieves near 7B-level performance on multimodal benchmarks — scoring 68.8 on VideoBench (video understanding) and 92.1 on Seed-tts-eval (speech generation).
Technical Principles of Qwen2.5-Omni-3B
• Thinker-Talker Architecture: This design separates the model into two components — Thinker for processing and understanding multimodal inputs (text, audio, video) and generating semantic representations, and Talker for producing natural speech based on Thinker’s outputs, enabling synchronized text and speech generation.
• TMRoPE (Time-aligned Multimodal RoPE): A custom positional embedding approach that aligns the timestamp of video frames with audio data. By interleaving time IDs of audio and video frames, the model encodes 3D positional info (time, height, width), enhancing multimodal synchronization.
• Streaming & Real-Time Processing: Implements chunk-based processing to handle long sequences of multimodal data, reducing latency. A sliding window mechanism limits the context range, further optimizing real-time generation.
• Precision Optimization: Supports FlashAttention 2 and BF16 precision to improve computational speed and memory efficiency.
Project Repository
• HuggingFace Model Hub: https://huggingface.co/Qwen/Qwen2.5-Omni-3B
Use Cases for Qwen2.5-Omni-3B
• Video Understanding & Analysis: Capable of real-time video content processing and analysis. Useful in video summarization, surveillance interpretation, and smart video editing by extracting key information from video content.
• Speech Generation & Interaction: With customizable voice options, it can be used in voice assistants, broadcast systems, audiobook creation, etc., providing natural and fluent speech interactions.
• Smart Customer Service & Automated Reporting: Processes text input and generates responses in real time, making it suitable for intelligent customer service and automated solution delivery.
• Education & Learning Tools: Assists with teaching by providing voice and text-based help, ideal for use in subjects like math where step-by-step reasoning is needed.
• Creative Content Generation: Can analyze images and produce creative multimodal outputs combining text and visuals.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...