
Qwen Releases New Model ParScale – 1.8B – P1
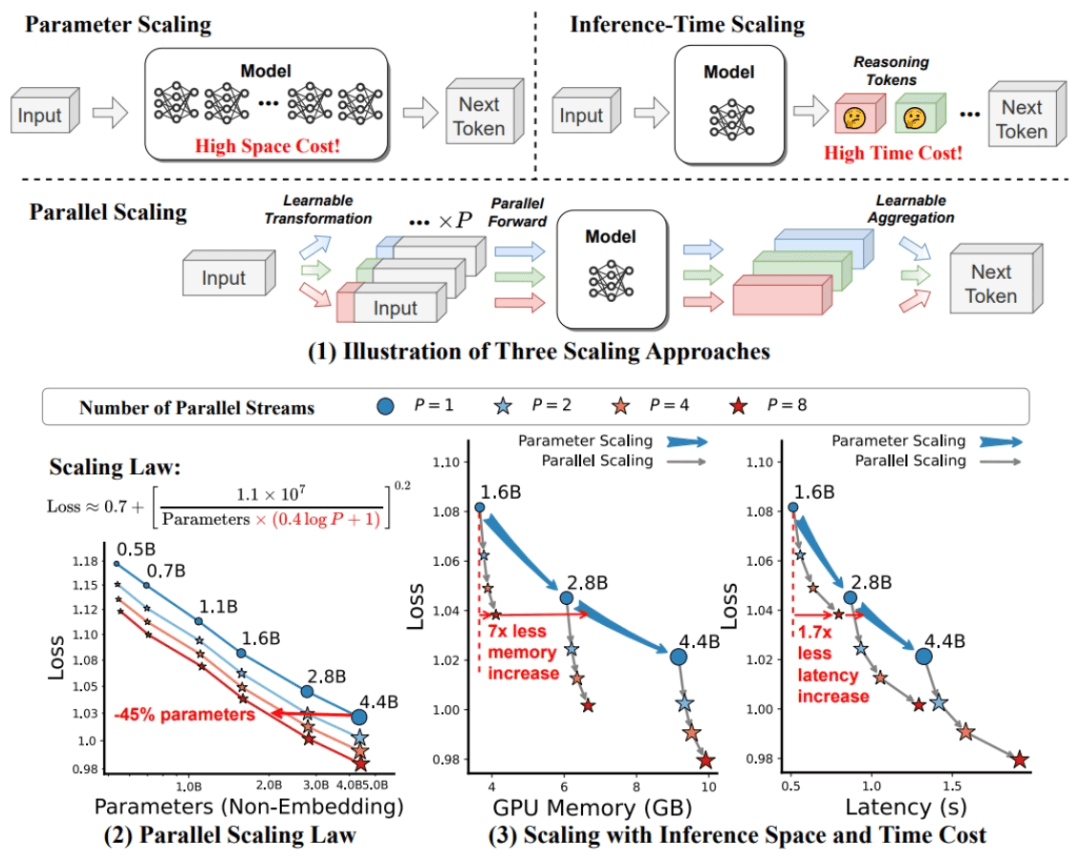
The Qwen team has released a new model, ParScale – 1.8B – P1. The uniqueness of this model lies in its ParScale method, which enhances model performance through parallel inference. Specifically, instead of simply launching multiple identical inferences, ParScale utilizes n parallel streams with learnable and differentiated transformations for inference. This approach can dynamically aggregate multiple output results without increasing the number of model parameters, approximately achieving the effect of parameter expansion. Studies have shown that the expansion using P parallel streams is equivalent to increasing the number of parameters by O(log P) times. Therefore, by increasing the degree of parallelism, the model size can be effectively reduced. Although this method is beneficial for GPU memory overhead, it may also lead to an increase in GPU computing power requirements, and the inference speed may not necessarily be accelerated.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts




No comments yet...