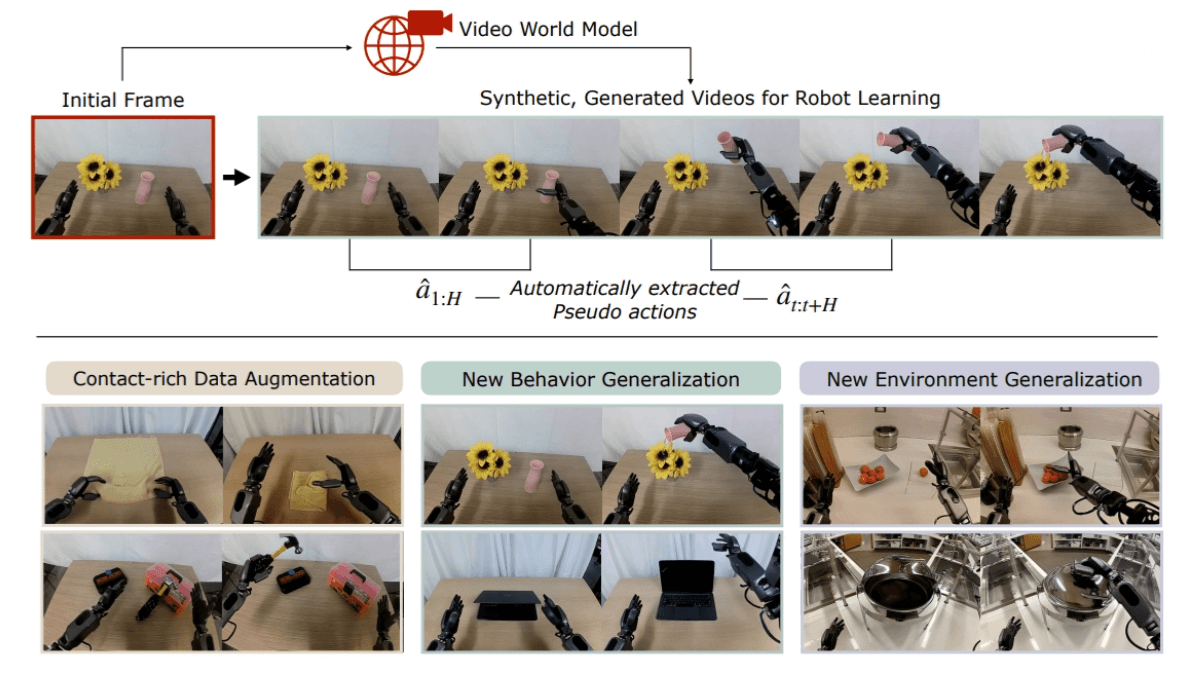
DreamGen is an innovative robotic learning technology introduced by NVIDIA. It leverages AI video world models to generate synthetic data, enabling robots to learn new skills “in a dream.” With only a small amount of real-world video data, DreamGen can produce large-scale, realistic training data, allowing robots to generalize behaviors and adapt to new environments. The four-step DreamGen pipeline includes fine-tuning the video world model, generating virtual data, extracting virtual actions, and training downstream policies. This approach enables robots to perform complex tasks from text instructions without relying on real-world data, significantly enhancing learning efficiency and generalization capability.
Key Features of DreamGen
Behavior Generalization: Robots can learn and execute new behaviors without collecting large amounts of real-world data for each new skill.
Environment Generalization: Robots can successfully operate in unseen environments using data collected in a single setting.
Data Augmentation: Generates large volumes of synthetic training data to boost success rates in complex robotic tasks.
Multi-Robot System Support: Compatible with various robotic systems (e.g., Franka, SO-100) and diverse policy architectures (e.g., Diffusion Policy, GR00T N1), offering broad applicability.
Technical Overview of DreamGen
Fine-Tuning the Video World Model: The video world model (e.g., Sora, Veo) is fine-tuned using teleoperation trajectory data from the target robot. Leveraging Low-Rank Adaptation (LoRA), the model preserves prior knowledge while adapting to new robotic characteristics, capturing essential kinematics and dynamics.
Virtual Data Generation: Given an initial frame and a language instruction, the video world model generates a sequence of robot videos illustrating the intended behavior—including novel behaviors in unseen environments. “Nightmare” videos that fail to meet the instruction are filtered out to ensure data quality.
Virtual Action Extraction: Latent Action Prior (LAPA) models or Inverse Dynamics Models (IDM) interpret the generated videos to extract pseudo-action sequences, forming neural trajectories used for training downstream visuomotor policies.
Policy Training: These neural trajectories are used to train visuomotor policies, enabling robots to learn new tasks and achieve zero-shot generalization without real-world data.