SearchAgent-X – An efficient reasoning framework developed jointly by Nankai University and the University of Illinois Urbana-Champaign (UIUC)
What is SearchAgent-X?
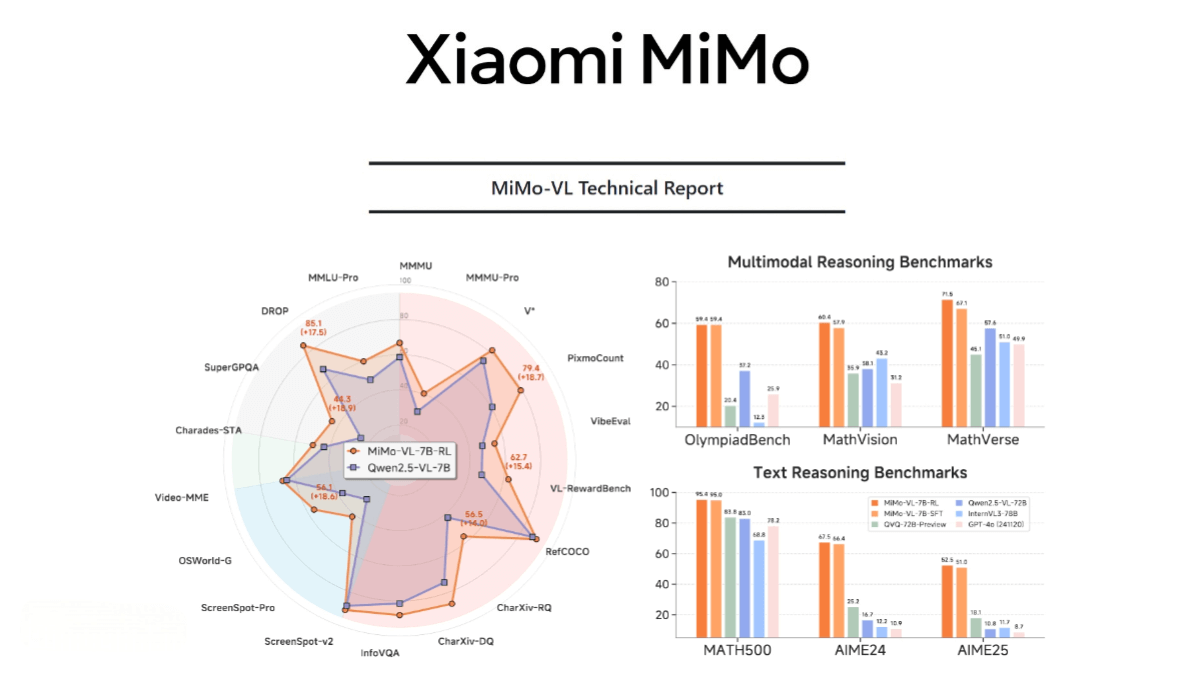
SearchAgent-X is an efficient reasoning framework developed by researchers from Nankai University and the University of Illinois at Urbana-Champaign (UIUC). It enhances the efficiency of search agents based on large language models (LLMs). By leveraging high-recall approximate retrieval and two key innovations—priority-aware scheduling and non-stall retrieval—SearchAgent-X significantly improves system throughput (by 1.3 to 3.4 times) and reduces latency (to 1/1.7 to 1/5 of the original) without compromising generation quality. The framework addresses two major efficiency bottlenecks—retrieval accuracy and latency—optimizing resource usage and offering valuable insights for deploying complex AI agents in real-world scenarios.

Key Features of SearchAgent-X
-
Significant Throughput Improvement: Achieves a 1.3x to 3.4x increase in throughput, greatly enhancing system processing capabilities.
-
Substantial Latency Reduction: Reduces latency to 1/1.7 to 1/5 of the original, ensuring rapid responses.
-
Maintains Generation Quality: Improves efficiency without sacrificing the quality of generated answers, ensuring both usability and reliability.
-
Dynamic Interaction Optimization: Efficiently handles complex multi-step reasoning tasks, supporting flexible interactions between retrieval and generation.
Technical Principles of SearchAgent-X
-
Priority-Aware Scheduling: Dynamically prioritizes concurrent requests based on real-time status (e.g., number of completed retrievals, context length, and waiting time). This enables the system to prioritize high-value computation, reduce unnecessary waiting and redundant computations, and significantly enhance KV-cache utilization.
-
Non-Stall Retrieval: Monitors the maturity of retrieval results and the readiness of the LLM engine to adaptively terminate retrieval tasks early. This avoids unnecessary delays and ensures the generation process proceeds in a timely manner, significantly reducing end-to-end latency.
-
High-Recall Approximate Retrieval: Uses approximate retrieval methods with high recall to avoid the inefficiencies caused by excessively high or low retrieval precision. Properly setting the retrieval scope ensures efficient support for high-quality reasoning.
Project Resources
-
GitHub Repository: https://github.com/tiannuo-yang/SearchAgent-X
-
arXiv Technical Paper: https://arxiv.org/pdf/2505.12065
Application Scenarios of SearchAgent-X
-
Intelligent Customer Service: Quickly and accurately answers customer inquiries, improving response speed and user satisfaction.
-
Search Engines: Provides precise search results and dynamic content generation to enhance user experience.
-
Enterprise Knowledge Management: Efficiently retrieves internal knowledge bases to support complex, multi-step reasoning tasks.
-
Intelligent Question Answering: Handles complex multi-hop questions and enables real-time user interaction.
-
Research and Development Support: Rapidly retrieves literature and optimizes experiment design, accelerating research workflows.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...