What is MiMo-VL?
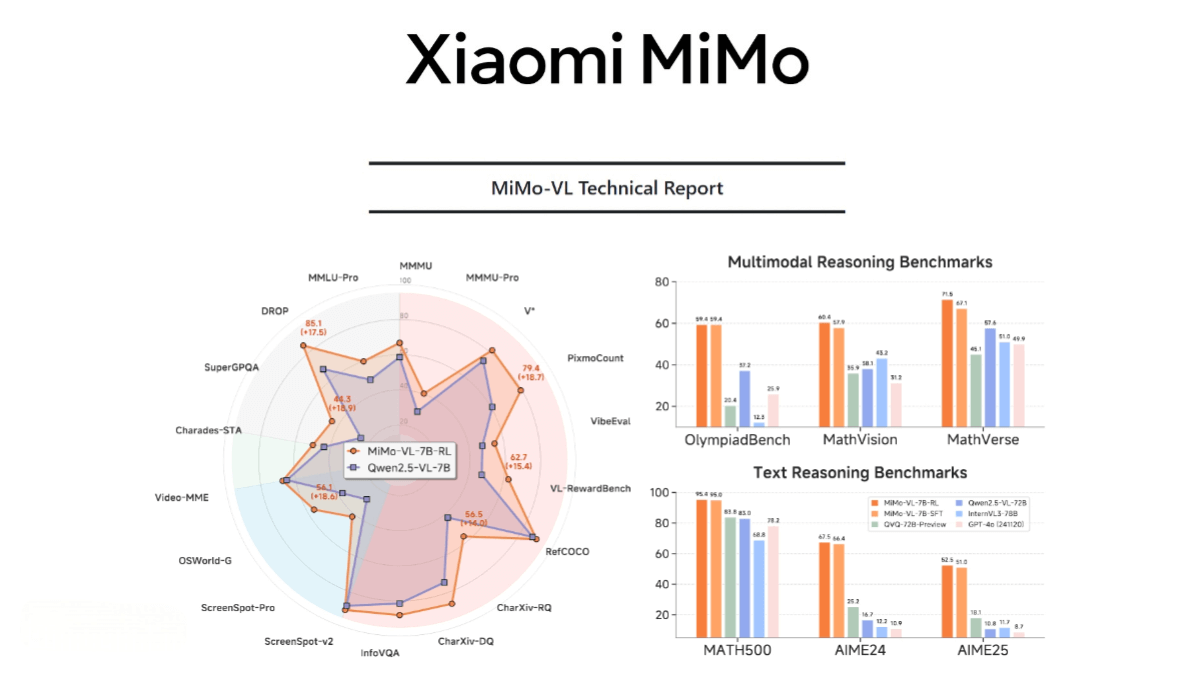
MiMo-VL is an open-source multimodal large model developed by Xiaomi. It consists of a vision encoder, a cross-modal projection layer, and a language model. The vision encoder is based on Qwen2.5-ViT, and the language model is Xiaomi’s proprietary MiMo-7B. It adopts a multi-stage pretraining strategy and utilizes 2.4 trillion tokens of multimodal data. Performance is enhanced through hybrid online reinforcement learning. MiMo-VL achieves strong results in fundamental visual understanding, complex reasoning, and GUI interaction tasks—for instance, it achieves 66.7% on MMMU-val, surpassing Gemma 3 27B, and 59.4% on OlympiadBench, outperforming some 72B models.
Key Features of MiMo-VL
-
Complex Image Reasoning and Q&A: Capable of performing reasoning and answering questions based on complex images, accurately interpreting visual content with coherent explanations and answers.
-
GUI Operation and Interaction: Supports GUI operations involving over 10 steps, understanding and executing complex graphical user interface instructions.
-
Video and Language Understanding: Understands video content and performs reasoning and Q&A in conjunction with language.
-
Long Document Parsing and Reasoning: Can handle long documents for in-depth reasoning and analysis.
-
User Experience Optimization: Uses a hybrid online reinforcement learning algorithm (MORL) to comprehensively improve model reasoning, perception, and user experience.
Technical Architecture of MiMo-VL
-
Vision Encoder: Based on Qwen2.5-ViT, supports native resolution input to preserve more visual detail.
-
Cross-modal Projection Layer: Aligns vision and language features using an MLP structure.
-
Language Model: Utilizes Xiaomi’s proprietary MiMo-7B model, specifically optimized for complex reasoning.
-
Multi-Stage Pretraining: Involves collecting, cleaning, and synthesizing high-quality multimodal pretraining data, including image-text pairs, video-text pairs, and GUI operation sequences—totaling 2.4 trillion tokens. The data proportions are adjusted across stages to strengthen long-range multimodal reasoning.
Four-Stage Pretraining Strategy
-
Projection Layer Warm-up: Uses image-text pair data, sequence length up to 8K.
-
Vision-Language Alignment: Uses interleaved image-text data, sequence length 8K.
-
Multimodal Pretraining: Incorporates OCR, video, GUI, and reasoning data, sequence length 8K.
-
Long-context SFT: Uses high-resolution images, long documents, and extended reasoning chains with sequence length up to 32K.
Project Repositories
-
Hugging Face Model Hub: https://huggingface.co/collections/XiaomiMiMo/mimo-vl
Application Scenarios of MiMo-VL
-
Smart Customer Service: Performs complex image reasoning and Q&A tasks, offering users more intelligent and convenient support.
-
Smart Home: Understands household photos and videos to execute GUI Grounding tasks, improving efficiency and experience in human-computer interaction.
-
Smart Healthcare: Understands medical images and texts to assist doctors in diagnosis and treatment.
-
Education: Aids in solving math problems and learning programming by providing step-by-step solutions and code examples.
-
Research and Academia: Supports logical reasoning and algorithm development, helping researchers verify hypotheses and design experiments.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts



No comments yet...