What is DeepEyes?
DeepEyes is a multimodal deep reasoning model jointly developed by the Xiaohongshu team and Xi’an Jiaotong University. It enables “thinking with images” capabilities similar to OpenAI’s o3 model, powered by end-to-end reinforcement learning without the need for supervised fine-tuning (SFT). During inference, DeepEyes dynamically invokes visual tools such as cropping and zooming to enhance detail perception and understanding.
The model achieves an impressive 90.1% accuracy on the visual reasoning benchmark V Bench*, demonstrating strong visual search and multimodal reasoning capabilities. DeepEyes excels in image localization, significantly reduces hallucinations, and enhances the model’s reliability and generalization.
Key Features of DeepEyes
-
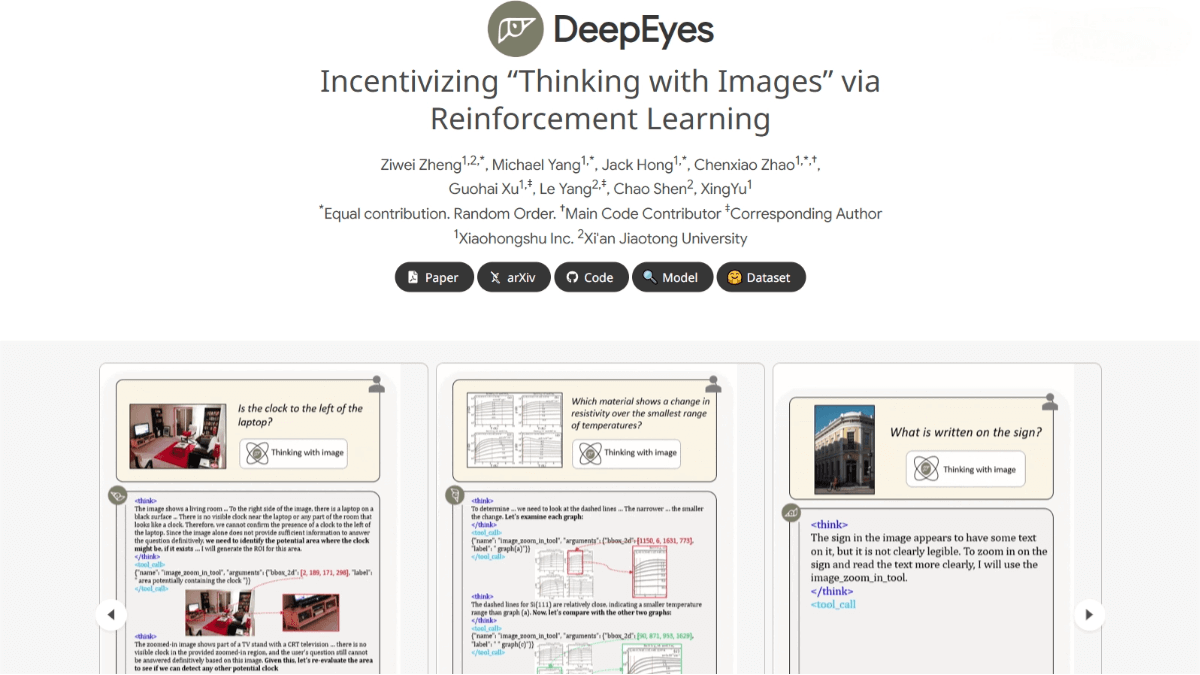
Thinking with Images: DeepEyes integrates images directly into the reasoning process. It doesn’t just “see” images—it “thinks” with them, dynamically invoking visual content to enhance understanding of fine-grained details.
-
Visual Search: Efficiently locates small or blurry objects in high-resolution images using intelligent cropping and zooming, greatly improving search accuracy.
-
Hallucination Mitigation: By focusing on visual details, DeepEyes reduces the risk of hallucinated outputs during answer generation, leading to more accurate and reliable responses.
-
Multimodal Reasoning: Seamlessly fuses visual and textual information for improved reasoning performance in complex tasks.
-
Dynamic Tool Invocation: The model autonomously decides when to use image tools such as cropping or zooming without external support, ensuring more efficient and accurate reasoning.
Technical Principles of DeepEyes
-
End-to-End Reinforcement Learning
DeepEyes is trained via end-to-end reinforcement learning, eliminating the need for supervised fine-tuning (SFT). It optimizes its behavior directly based on reward signals, learning to use visual information effectively during reasoning. Rewards include accuracy, format correctness, and conditional tool usage, ensuring optimal answer generation with efficient tool application. -
Interleaved Multimodal Chain-of-Thought (iMCoT)
DeepEyes introduces iMCoT, allowing the model to alternate between visual and textual information during inference. At each reasoning step, the model decides whether additional visual input is needed, crops relevant image regions based on generated bounding boxes, and re-feeds them as new evidence. -
Tool-Use-Oriented Data Selection
To promote effective tool usage, DeepEyes is trained on carefully curated datasets selected for their potential to activate tool behaviors. These include high-resolution images, charts, and reasoning tasks across various domains, enhancing generalization. -
Evolution of Tool Use Behavior
The model’s tool invocation behavior evolves through three stages: initial exploration, active usage, and efficient exploitation. It progresses from random attempts to human-like efficient and precise tool usage during reasoning. -
Multimodal Fusion
DeepEyes unifies visual and textual information in a deeply integrated reasoning framework. This fusion boosts visual task performance and enhances capabilities in complex multimodal scenarios.
Project Links
-
Official Website: https://visual-agent.github.io/
-
GitHub Repository: https://github.com/Visual-Agent/DeepEyes
-
Hugging Face Model: https://huggingface.co/ChenShawn/DeepEyes
-
arXiv Paper: https://arxiv.org/pdf/2505.14362
Application Scenarios
-
Education and Tutoring: Analyzes diagrams and geometry in test papers, providing students with detailed problem-solving steps to improve learning efficiency.
-
Medical Imaging: Assists doctors in diagnosing by analyzing medical images, enhancing accuracy and efficiency in clinical workflows.
-
Intelligent Transportation: Real-time analysis of traffic images supports autonomous driving systems in making safer and more accurate decisions.
-
Security Monitoring: Analyzes surveillance footage to detect abnormal behaviors, enhancing public safety and crime prevention.
-
Industrial Manufacturing: Performs quality inspection and equipment fault prediction on production lines, improving efficiency and reducing maintenance costs.