Seedance 1.0 – A video generation model launched by ByteDance
What is Seedance 1.0?
Seedance 1.0 is a foundational video generation model developed by ByteDance’s Seed team. It supports both text and image inputs to generate high-quality 1080p videos with seamless multi-shot transitions. The model is natively capable of multi-shot storytelling, including transitions between long, medium, and close-up shots. It ensures stable subject motion and natural visuals. Seedance 1.0 supports various creative styles such as photorealism, anime, and cinematic aesthetics. It also offers fast generation speeds at low cost.
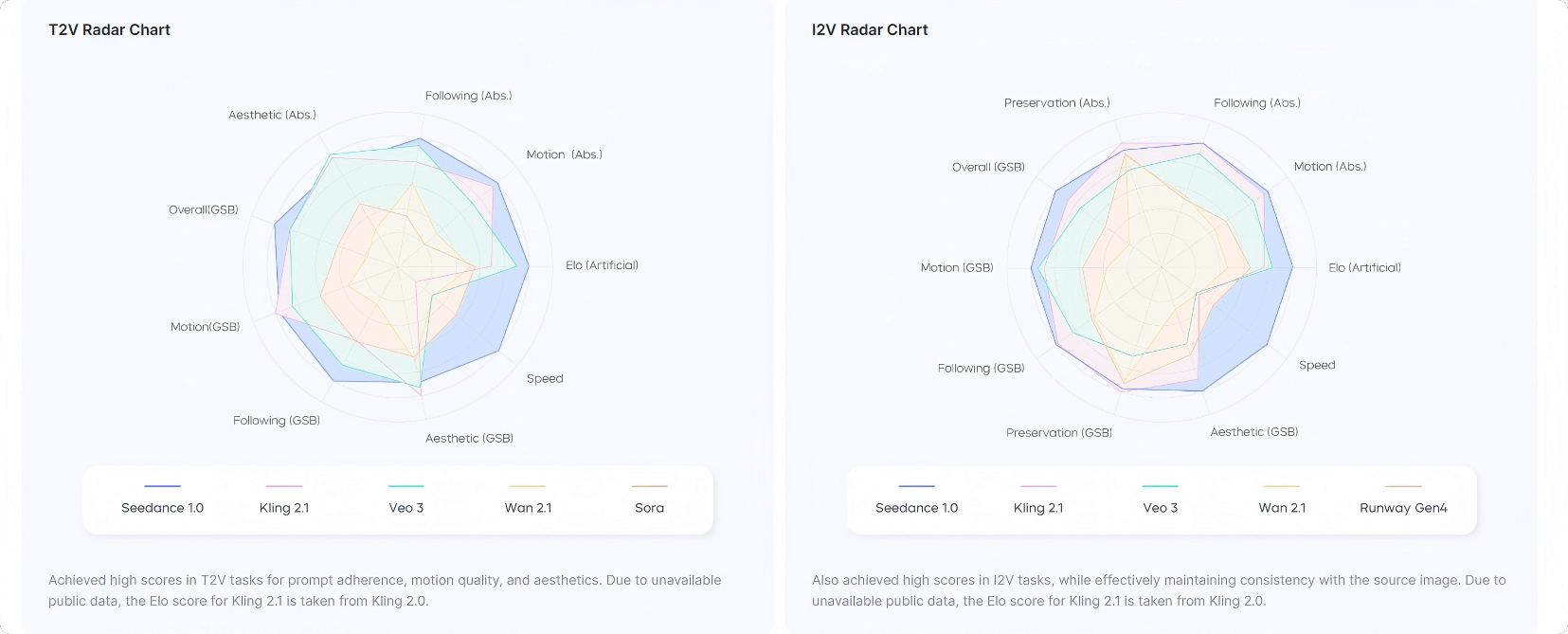
On the third-party benchmark platform Artificial Analysis, Seedance 1.0 ranks first in both text-to-video (T2V) and image-to-video (I2V) tasks, demonstrating its strong performance and advantages in video generation.
Key Features of Seedance 1.0
-
Multi-Shot Narrative Capability: Enables the generation of videos with multiple coherent shots, allowing smooth transitions between wide, medium, and close-up views. It ensures consistency in core subjects, visual style, and overall atmosphere.
-
Smooth and Stable Motion Rendering: The model can generate videos with significant motion, from subtle facial expressions to dynamic scenes, maintaining high stability and physical realism.
-
Multi-Style Video Creation: Supports a range of styles, including photorealistic, anime, cinematic, and commercial.
-
Precise Semantic Understanding and Instruction Following: Capable of accurately parsing complex natural language prompts and controlling multiple subjects and action compositions. It also supports diverse camera movement options.
-
High-Speed Inference and Low Cost: Thanks to model structure optimizations and inference acceleration, Seedance 1.0 enables fast video creation. For example, generating a 5-second 1080p video takes only 41.4 seconds on an NVIDIA L20—significantly faster than similar models.
Technical Principles of Seedance 1.0
-
Multi-Source Data Curation & Precise Description Model: A large-scale, diverse video dataset was built through multi-stage filtering and balancing. It covers various themes, scenes, styles, and camera movements. A dense captioning model that fuses static and dynamic features was trained to generate precise video captions for training. This model focuses on actions, camera motion, and key scene elements.
-
Efficient Pretraining Framework: Uses a decoupled spatial-temporal diffusion Transformer. The spatial layer aggregates attention within single frames, while the temporal layer handles cross-frame attention, improving both training and inference efficiency. It supports interleaved visual and text tokens and is trained on multi-shot videos to enhance multi-modal understanding and multi-shot generation. A binary mask guides which frames follow generation controls, unifying text-to-image, text-to-video, and image-to-video tasks.
-
Post-Training Optimization with a Composite Reward System: During fine-tuning, the model is trained on high-quality video-text pairs. A composite reward system includes base reward, motion reward, and aesthetics reward models. These help improve alignment, motion quality, and visual appeal. A multi-reward maximization approach, combined with Reinforcement Learning from Human Feedback (RLHF), enhances performance in both T2V and I2V tasks.
-
Extreme Inference Acceleration: Through segmental trajectory consistency, score matching, and human preference-guided adversarial distillation, Seedance achieves optimal speed-quality balance at low inference steps. A lightweight VAE decoder, refined with a channel structure, enables high-quality video generation at double speed. System-level optimizations—such as fused operator enhancement, heterogeneous quantization sparsity, adaptive mixed parallelism, asynchronous offloading, and VAE parallel decomposition—allow efficient inference for long-sequence video generation, improving throughput and memory usage.
Performance of Seedance 1.0
On the Artificial Analysis platform, Seedance 1.0 ranks first in both Text-to-Video (T2V) and Image-to-Video (I2V) tasks.
In internal benchmark comparisons, Seedance 1.0 performs exceptionally across multiple dimensions such as instruction following, motion quality, and aesthetics—especially in T2V tasks.
Official Examples of Seedance 1.0
-
Native Multi-Shot Storytelling
Prompt: A girl plays the piano, with cinematic-quality multi-shot transitions (I2V).

-
Enhanced Motion Generation
Prompt: A skier is skiing. As he turns, a large spray of snow rises. He accelerates down the slope while the camera smoothly tracks him.

-
High-Aesthetic Multi-Style Creation
Showcases the model’s ability to generate visually pleasing videos in various styles.

Project Links
-
Official Website: https://seed.bytedance.com/zh/seedance
-
Technical Paper: https://lf3-static.bytednsdoc.com/obj/eden-cn/bdeh7uhpsuht/Seedance
Application Scenarios
-
Film and TV Production: Generates narrative videos with multiple shot transitions, supporting complex storytelling structures and enhancing visual storytelling.
-
Advertising and Marketing: Quickly produces high-quality promotional videos in various styles and scenes, catering to different branding and product needs.
-
Game Development: Creates cinematic cutscenes and dynamic in-game environments, enriching storytelling and immersion.
-
Education and Training: Generates educational and instructional videos that help learners and employees better grasp knowledge.
-
News and Media: Produces dynamic content for news reporting and documentaries, boosting their visual impact.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...