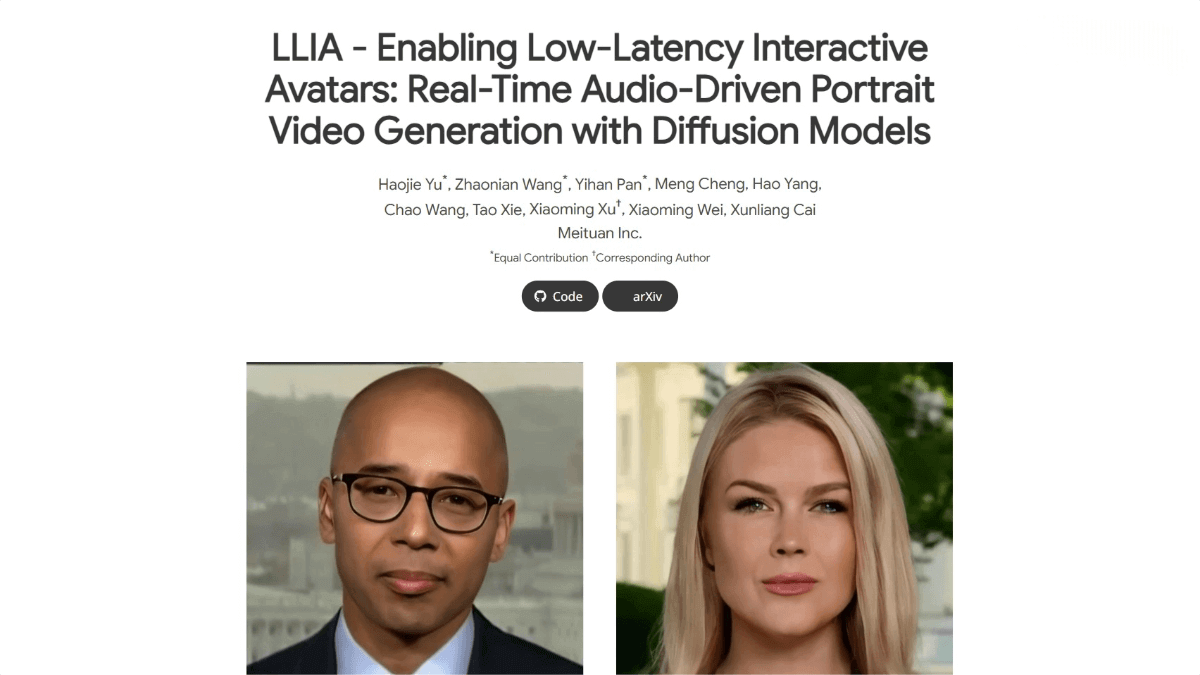
LLIA – An Audio-Driven Portrait Video Generation Framework Proposed by Meituan
What is LLIA?
LLIA (Low-Latency Interactive Avatars) is a real-time audio-driven portrait video generation framework developed by Meituan, based on diffusion models. The framework generates virtual avatars driven by audio input, supporting low-latency and high-fidelity real-time interaction. LLIA employs variable-length video generation technology to reduce initial video generation delay, combined with consistency model training strategies and model quantization techniques to significantly improve inference speed. LLIA supports controlling the avatar’s states (such as speaking, listening, idle) and fine-grained facial expression control through category labels, providing users with a smooth and natural interactive experience.
Main Features of LLIA
-
Real-time audio-driven portrait video generation: Generates corresponding portrait videos in real time based on audio input, synchronizing speech with expressions and movements.
-
Low-latency interaction: Achieves high frame rates (e.g., 78 FPS at 384×384 resolution) and low latency (e.g., 140 ms) on high-performance GPUs, suitable for real-time interactive scenarios.
-
Multi-state switching: Supports avatar state control via category labels, such as speaking, listening, and idle states, enabling natural avatar reactions to different contexts.
-
Facial expression control: Uses portrait animation techniques to modify the reference image’s expressions, enabling fine control of facial expressions in the generated video and enhancing avatar expressiveness.
Technical Principles of LLIA
-
Diffusion model framework: LLIA is built on diffusion models, leveraging their strong generation capability and high-fidelity output. Diffusion models generate images and videos by gradually removing noise step-by-step.
-
Variable-length video generation: Introduces a dynamic training strategy allowing the model to generate video clips of varying lengths during inference, reducing latency while maintaining video quality.
-
Consistency models: Incorporates consistency models and discriminators to achieve high-quality video generation with fewer sampling steps, significantly accelerating inference speed.
-
Model quantization and parallelization: Uses model quantization (e.g., INT8 quantization) and pipeline parallelism to further optimize inference performance and reduce computational resource requirements.
-
Conditional input and control: Based on category labels and portrait animation techniques, LLIA dynamically adjusts the avatar’s state and facial expressions according to audio features, achieving natural interactive effects.
-
High-quality datasets: Trained on over 100 hours of high-quality datasets, including open-source, web-collected, and synthetic data, enhancing model performance across diverse scenarios.
Project Links
-
Official website: https://meigen-ai.github.io/llia/
-
GitHub repository: https://github.com/MeiGen-AI/llia
-
arXiv technical paper: https://arxiv.org/pdf/2506.05806
Application Scenarios of LLIA
-
Virtual interviews: Generate virtual interviewers or candidates, providing real-time facial and gesture feedback to enhance realism and interactivity.
-
Mobile chatbots: Provide chatbots with vivid virtual avatars that generate expressions and movements in real time based on voice input, improving user interaction.
-
Virtual customer service: Create virtual customer service agents that respond to customer speech with natural expressions and gestures, enhancing customer satisfaction.
-
Online education: Generate virtual teachers or assistants that adjust expressions and movements according to teaching content and student feedback, boosting teaching interaction.
-
Virtual socializing: Generate virtual avatars for users that control expressions and movements based on voice, enabling more realistic and natural social experiences.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...