What is OmniFlow?
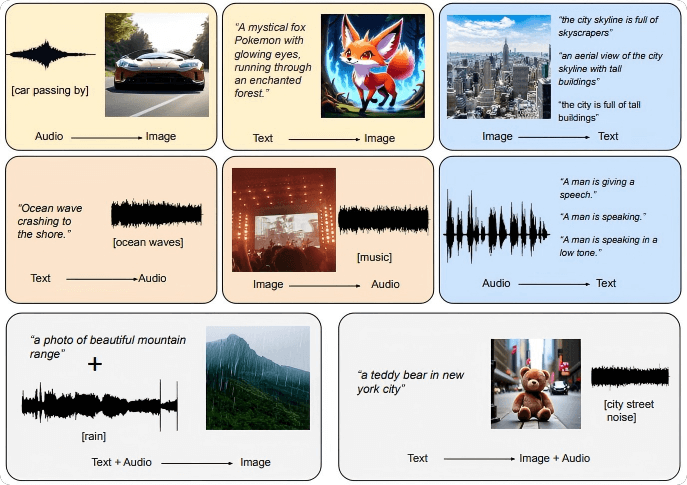
OmniFlow is a multimodal AI model developed through a collaboration between Panasonic and the University of California, Los Angeles (UCLA). The model supports Any-to-Any generation tasks across text, images, and audio—for example, generating images or audio from text, or generating images from audio. OmniFlow extends the existing image-generation rectified flow framework by learning complex data relationships through the connection and processing of three different data modalities. This approach avoids the limitations of simply averaging across modalities. Featuring a modular design, OmniFlow allows for independent pretraining and fine-tuning of each component, significantly improving training efficiency and model scalability. It demonstrates strong performance and flexibility in multimodal generation tasks.
Key Features of OmniFlow
-
Any-to-Any Generation: Enables bidirectional generation across text, image, and audio modalities.
-
Text-to-Image: Generates images based on textual descriptions.
-
Text-to-Audio: Converts text into speech or music.
-
Audio-to-Image: Produces images based on audio content.
-
Multimodal Input to Unimodal Output: Supports combinations of inputs (e.g., text + audio) to generate a single output modality like images.
-
Multimodal Data Processing: Simultaneously processes text, image, and audio data, enabling complex multimodal generation tasks.
-
Flexible Generation Control: Allows users to guide the generation process by adjusting alignment and interactions between modalities, such as emphasizing specific elements in an image or tuning the tone of audio output.
-
Efficient Training & Scalability: Modular architecture enables independent pretraining for each modality. Components can be merged and fine-tuned together for specific tasks, improving training efficiency and adaptability.
Technical Principles of OmniFlow
-
Multi-Modal Rectified Flows: OmniFlow extends the Rectified Flow framework to learn joint distributions across text, image, and audio. By integrating the features of all three modalities, it captures complex relationships and avoids the pitfalls of simple feature averaging. The flow framework enables gradual noise reduction during generation, producing high-quality outputs.
-
Modular Design: Each modality—text, image, and audio—is handled by independently designed modules. After pretraining, these modules can be flexibly combined and fine-tuned for specific multimodal generation tasks.
-
Multimodal Guidance Mechanism: OmniFlow introduces a guidance mechanism that enables user-defined control over modality alignment and interactions during generation.
-
Joint Attention Mechanism: OmniFlow incorporates a joint attention mechanism that facilitates direct interaction between features of different modalities. This allows the model to dynamically attend to relevant cross-modal features, improving coherence and generation quality.
OmniFlow Project Links
-
Official Website: https://news.panasonic.com/global/press/en250604-4
-
arXiv Paper: https://arxiv.org/pdf/2412.01169
Application Scenarios for OmniFlow
-
Creative Design: Generate images or design elements from text descriptions to inspire designers, such as producing posters or digital artwork.
-
Video Production: Combine text and audio to create video content, or generate visual effects from audio for short films, animations, and more.
-
Writing Assistance: Create textual descriptions from images or audio to help authors write articles, scripts, or stories.
-
Game Development: Generate game environments, character designs, or sound effects based on story scripts, speeding up the development process.
-
Music Composition: Generate music from text descriptions or images to compose soundtracks for films, games, or advertisements.