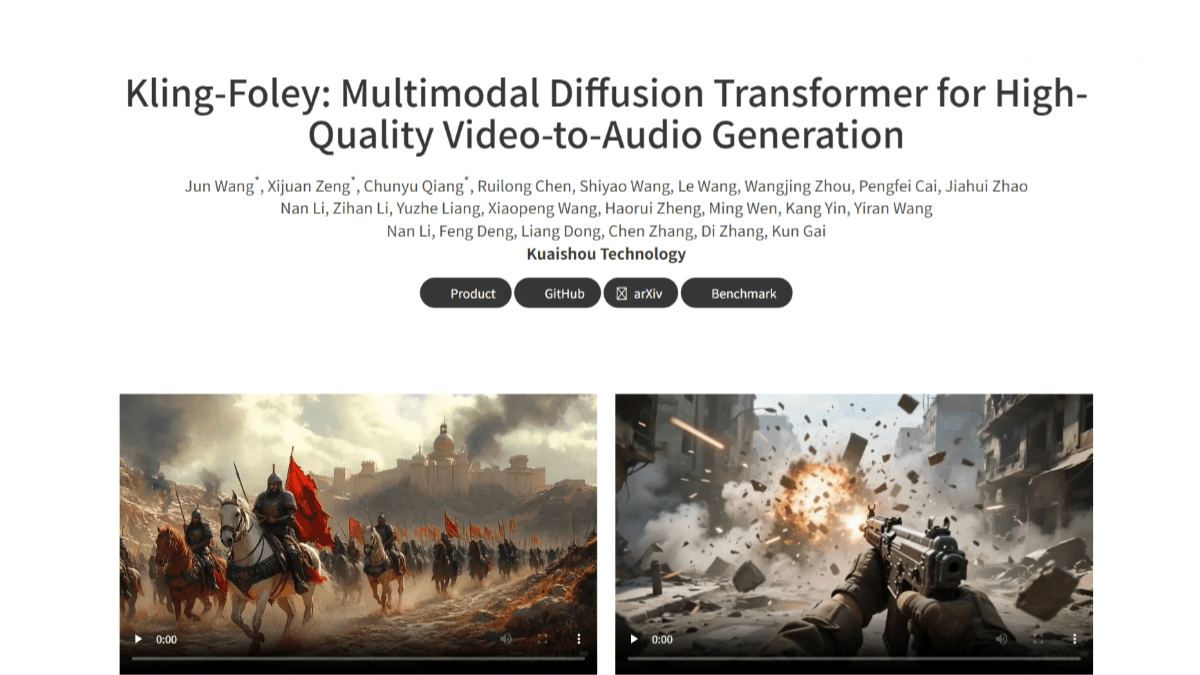
What is Kling-Foley?
Kling-Foley is a multimodal video-to-audio generation model developed by Kling AI. By taking video and optional text prompts as conditional inputs, the model can generate high-quality, temporally aligned stereo audio that semantically matches the video content—including sound effects, background music, and other audio types. It supports audio generation of arbitrary length. Built on a flow-matching architecture controlled by multimodal input, Kling-Foley uses feature fusion and specialized modules to achieve precise audio-video alignment. Trained on a large-scale, proprietary multimodal dataset, Kling-Foley delivers state-of-the-art audio generation performance and provides a highly efficient and high-quality solution for video content creation.
Key Features of Kling-Foley
-
High-Quality Audio Generation: Generates stereo audio that is semantically aligned and temporally synchronized with the video content, including various types of sound effects and background music, fulfilling diverse audio needs across scenarios.
-
Arbitrary-Length Audio Support: Capable of generating audio of any length, dynamically adapting to the duration of the input video.
-
Stereo Rendering: Supports spatially aware stereo sound rendering, modeling the directionality of audio sources for enhanced spatial realism and immersive experience.
Technical Architecture of Kling-Foley
-
Multimodal Controlled Flow Matching Model:
Kling-Foley adopts a flow-matching model with multimodal control. Video frames, text prompts, and timestamps are fed into a multimodal joint conditioning module for fusion, then processed by the MMDit module. This design enables the model to better understand and generate audio aligned with the video content. -
Modular Processing Pipeline:
After multimodal fusion, features are passed through the MMDit module to predict latent representations via a VAE (Variational Autoencoder). A pretrained Mel decoder reconstructs single-channel Mel spectrograms, which are then converted into stereo spectrograms using the Mono2Stereo module. Finally, a vocoder generates the output waveform. -
Visual-Semantic and Audio-Video Alignment Modules:
Includes modules for extracting visual semantic features and synchronizing audio with video at the frame level. These modules ensure strong temporal and semantic alignment between audio and video. -
Discrete Duration Embedding:
Introduces discrete duration embedding as part of the global conditioning mechanism, enabling the model to better handle inputs of varying lengths and generate audio that matches the video duration. -
Universal Latent Audio Codec:
Kling-Foley uses a universal latent audio codec to model diverse audio types such as sound effects, speech, singing, and music. The core is a Mel-VAE, which jointly trains the Mel encoder, decoder, and discriminator to learn a continuous and complete latent space, significantly improving audio representation quality.
Project Links
-
Project Website: https://klingfoley.github.io/Kling-Foley/
-
GitHub Repository: https://github.com/klingfoley/Kling-Foley
-
arXiv Paper: https://www.arxiv.org/pdf/2506.19774
Application Scenarios
-
Video Content Creation:
Provides precisely matched sound effects and background music for animation, short videos, advertisements, etc., enhancing content appeal and production efficiency. -
Game Development:
Generates realistic environmental and action-based sound effects—such as gunshots, character movements, and ambient sounds—boosting game immersion and player engagement. -
Education and Training:
Adds appropriate sound effects and background music to educational videos and virtual training simulations, increasing realism and learning effectiveness. -
Film and Television Production:
Produces high-quality audio effects and soundtracks for movies, dramas, and TV shows, enhancing the overall audio quality and emotional impact of the narrative. -
Social Media:
Enables users to quickly add matching audio and background music to their shared videos, improving content attractiveness and engagement.