
RedOne – The social large model launched by Xiaohongshu (Little Red Book)
What is RedOne?
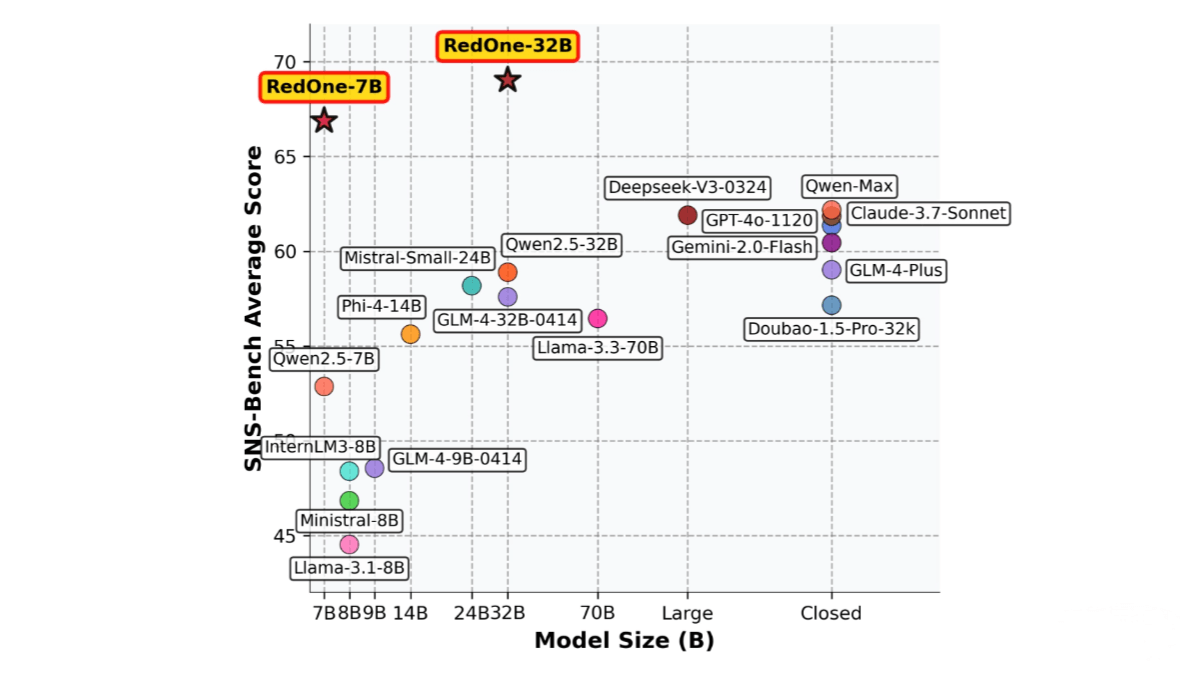
RedOne is the first customized large language model (LLM) launched by Xiaohongshu (Little Red Book) specifically for the Social Network Service (SNS) domain. The model uses a three-stage training strategy to inject social culture knowledge, strengthen multi-task capabilities, and align with platform policies and human preferences. Compared to base models, RedOne achieves an average performance improvement of 14.02% across eight major social tasks and a 7.56% increase on bilingual evaluation benchmarks. In harmful content detection, it reduces exposure by 11.23%, and in post-browse search, it improves page click-through rates by 14.95%. RedOne demonstrates outstanding performance in the social domain, providing strong support for SNS applications.
Main Functions of RedOne
-
Content Understanding: Classifies user-generated content, recognizes topics, and interprets intent.
-
Information Extraction: Extracts structured information from informal social posts, such as predicting tags, answering questions, and detecting key terms.
-
Semantic Matching: Judges the semantic relationship between user queries and social notes, providing relevance assessment.
-
User Behavior Modeling: Simulates user behavior, such as generating follow-up queries based on browsing history.
-
Dialogue and Role Simulation: Supports emotional companionship dialogues and role-playing in group chats.
-
Translation: Translates posts in multilingual environments while preserving the original tone and emotion.
-
Harmful Content Detection: Reduces exposure to harmful content, enhancing platform safety.
-
Post-Browse Search Optimization: Increases user click-through rates and improves content discovery.
Technical Principles of RedOne
-
Continue Pretraining (CPT): During this phase, RedOne is injected with foundational social domain knowledge. Researchers collected large-scale data from general high-quality corpora and social networking platforms, covering informal discussions, short comments, sarcasm, and various social communication modes. A carefully designed data filtering process removes low-quality data and optimizes data mixing. The model is further trained based on Qwen2.5.
-
Supervised Fine-Tuning (SFT): This phase bridges the gap between pretraining objectives and real SNS application needs through task definitions and data construction. Researchers curated large amounts of real user-generated content and defined six core capabilities, including content understanding, information extraction, and semantic matching, mapping each to specific tasks. Using a two-step training strategy, the first step mixes large-scale general data and SNS data, while the second step increases the SNS data proportion to optimize key task performance.
-
Preference Optimization (PO): This phase uses implicit preference signals to make model outputs more aligned with human preferences and platform policies. Different preference construction strategies are applied based on task type (subjective vs. objective). Experts annotate preferences and expand datasets. Using the Direct Preference Optimization (DPO) algorithm, the model output is optimized to better match human preferences.
-
Data Mixing and General Capability Retention: During training, general-domain and SNS-domain data are mixed to maintain the model’s general capabilities while improving adaptation and performance in the SNS domain, enhancing out-of-domain (OOD) task generalization.
Project Link for RedOne
- Technical paper on arXiv: https://www.arxiv.org/pdf/2507.10605
Application Scenarios of RedOne
-
Harmful Content Detection: Effectively identifies and filters harmful content such as hate speech, misinformation, and sexually violent content. By reducing harmful content exposure, it significantly improves platform safety and user experience.
-
Post-Browse Search Optimization: Generates more precise search suggestions and recommendations based on users’ browsing history and behavior, enhancing content discovery and user interaction with the platform.
-
Content Understanding and Classification: Automatically classifies and understands user-generated content, assisting the platform in better content management and recommendation.
-
Information Extraction: Extracts key information from informal social posts, such as tags, key terms, and critical facts, useful for content recommendation, information aggregation, and knowledge graph construction.
-
Semantic Matching: Assesses the semantic relevance between user queries and social notes, providing more accurate search results and recommendations.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...