
What is gpt-oss?
gpt-oss is an open-source inference model series launched by OpenAI, consisting of two versions: gpt-oss-120b and gpt-oss-20b. The gpt-oss-120b has 117 billion parameters with approximately 5.1 billion active parameters and can run on a single 80GB GPU; gpt-oss-20b has 21 billion parameters with about 3.6 billion active parameters and can run on consumer-grade devices with 16GB memory, such as laptops or smartphones. Both models are based on the Mixture of Experts (MoE) architecture, support a context length of 128k tokens, and deliver performance close to the closed-source o4-mini and o3-mini models. They excel in tool usage, few-shot function calling, chain-of-thought reasoning, and health-related Q&A. The models are open-sourced under the Apache 2.0 license, supporting free commercial use and providing developers with powerful local inference capabilities.

Main Features of gpt-oss
-
Tool Usage: Supports calling external tools (such as web search, Python code interpreters) to solve complex problems and enhance problem-solving ability.
-
Chain-of-Thought: Breaks down complex problems step by step for gradual resolution, suitable for multi-step reasoning tasks.
-
Low Resource Requirements: gpt-oss-20b runs on devices with 16GB memory, ideal for consumer-grade devices; gpt-oss-120b runs on 80GB GPUs, suitable for high-performance needs.
-
Fast Inference: Inference speed reaches 40–50 tokens per second, suitable for scenarios requiring quick responses.
-
Open-Source Weights: Provides complete model weights and code, supports local fine-tuning and customization to meet specific task requirements.
-
Adjustable Inference Intensity: Supports low, medium, and high inference intensity levels to balance latency and performance according to needs.
Technical Principles of gpt-oss
-
Model Architecture: Based on Transformer architecture using Mixture of Experts (MoE) to reduce the number of active parameters needed for processing input, improving inference efficiency. It uses alternating dense and local band sparse attention patterns, similar to GPT-3, for better memory and compute efficiency. Grouped multi-query attention with group size 8 further enhances inference speed. RoPE positional encoding is applied, supporting up to 128k tokens context length.
-
Pretraining and Posttraining: Pretrained on high-quality pure text datasets focusing on STEM, programming, and general knowledge domains. Posttraining follows a similar process to o4-mini, including supervised fine-tuning and high-compute reinforcement learning phases. The training objective is to align the model with OpenAI’s model standards and enable chain-of-thought reasoning and tool usage capabilities.
-
Quantization and Optimization: Uses MXFP4 quantization format; the model is trained to adapt to low-precision environments, ensuring reduced size while maintaining high performance. After quantization, gpt-oss-20b is about 12.8GB, runnable on 16GB memory devices. gpt-oss-120b can run on 80GB memory after quantization. Collaborations with hardware vendors like NVIDIA and AMD ensure performance optimization across various systems.
-
Safety Mechanisms: Filters harmful data related to chemical, biological, radiological, and nuclear (CBRN) topics during pretraining. Uses cautious alignment and instruction priority evaluation to train the model to reject unsafe prompts and resist prompt injection attacks. Conducts adversarial fine-tuning in specific domains such as biology and cybersecurity to evaluate and improve model safety.
Performance of gpt-oss
Benchmark Performance:
-
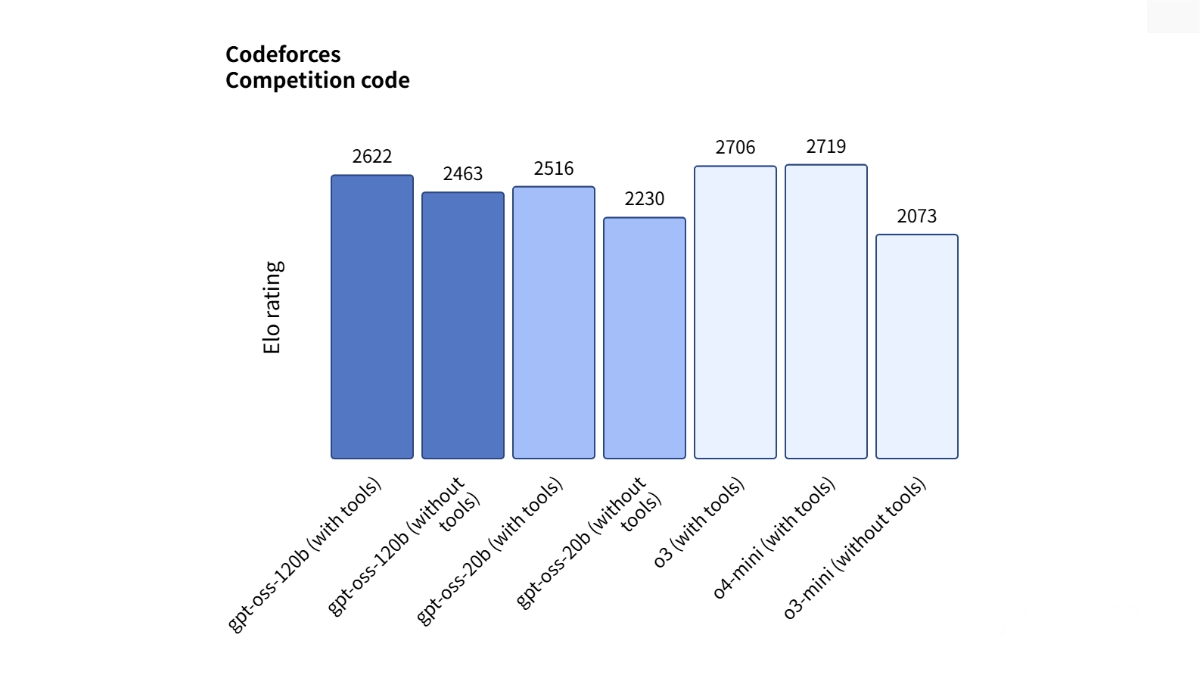
Competitive Programming: In Codeforces competitive programming tests, gpt-oss-120b scored 2622 points and gpt-oss-20b scored 2516 points, outperforming some open-source models but slightly behind the closed-source o3 and o4-mini.
-
General Problem Solving: In MMLU and HLE tests, gpt-oss-120b outperformed OpenAI’s o3-mini and approached the performance level of o4-mini.
-
Tool Usage: In the TauBench agent evaluation suite, both gpt-oss-120b and gpt-oss-20b outperformed OpenAI’s o3-mini, reaching or exceeding o4-mini’s level.
-
Health Q&A: In HealthBench tests, gpt-oss-120b exceeded o4-mini performance, and gpt-oss-20b reached a level comparable to o3-mini.
Project Links for gpt-oss
-
Official Website: https://openai.com/index/introducing-gpt-oss/
-
GitHub Repository: https://github.com/openai/gpt-oss
-
HuggingFace Model Hub: https://huggingface.co/collections/openai/gpt-oss-68911959590a1634ba11c7a4
-
Online Demo: https://gpt-oss.com/
Application Scenarios of gpt-oss
-
Local Inference & Privacy Protection: Runs locally in privacy-sensitive fields (such as healthcare and finance), ensuring data security while providing powerful inference.
-
Programming Assistance & Code Generation: Developers use gpt-oss with tool-calling to generate and verify code snippets, significantly improving programming efficiency and reducing debugging time.
-
Intelligent Customer Service & Support: Enterprises deploy gpt-oss as intelligent customer service agents for fast, accurate responses, lowering labor costs.
-
Education & Learning Assistance: Students leverage gpt-oss for help with questions and writing suggestions, enhancing learning efficiency and comprehension.
-
Creative Content Generation: Writers, screenwriters, and game developers use gpt-oss to generate creative content, spark inspiration, and boost productivity.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...