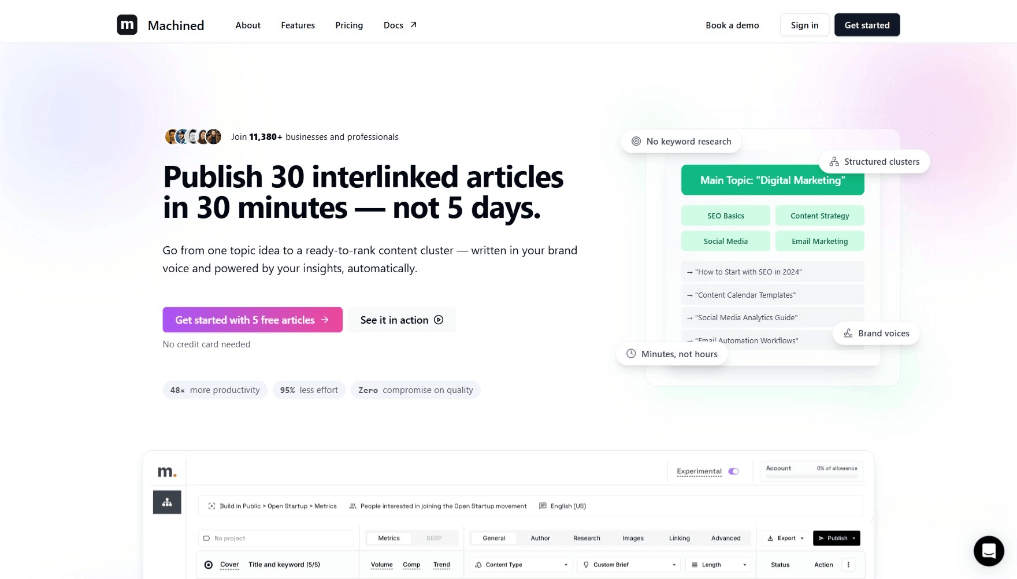
EchoMimicV3 — a multimodal digital human video generation framework released by Ant Group
What is EchoMimicV3?
EchoMimicV3 is an efficient multimodal, multi-task digital human video generation framework developed by Ant Group. With 1.3 billion parameters, it adopts a task-mixing and modality-mixing paradigm, combined with novel training and inference strategies, to achieve fast, high-quality, and highly generalizable digital human animation. Through multi-task masked input, counter-intuitive task assignment strategies, a coupled–decoupled multimodal cross-attention module, and a timestep phase-aware multimodal allocation mechanism, EchoMimicV3 delivers strong performance across diverse tasks and modalities—despite its relatively compact size—marking a breakthrough in digital human video generation.

Key Features of EchoMimicV3
-
Multimodal input support: Processes various input modalities (audio, text, images, etc.) for richer and more natural human animation.
-
Unified multi-task framework: Integrates multiple tasks into a single model, including audio-driven facial animation, text-to-motion generation, and image-driven pose prediction.
-
Efficient training & inference: Achieves high performance with optimized strategies, enabling efficient training and fast animation generation.
-
High-quality animation: Produces natural, detailed, and coherent digital human animations suitable for diverse applications.
-
Strong generalization: Adapts well to different input conditions and task requirements.
Technical Principles of EchoMimicV3
-
Task-Mixing Paradigm (Soup-of-Tasks): Uses multi-task masked input and counter-intuitive task assignment, allowing the model to jointly learn multiple tasks without requiring multiple models.
-
Modality-Mixing Paradigm (Soup-of-Modals): Introduces a coupled–decoupled multimodal cross-attention module to inject multimodal conditions, along with a phase-aware multimodal allocation mechanism for dynamic modality mixing.
-
Negative Direct Preference Optimization & Phase-Aware Negative Classifier-Free Guidance: These techniques ensure training and inference stability by improving preference learning and guiding mechanisms, helping the model handle complex inputs while avoiding instability and performance degradation.
-
Transformer architecture: Built on the Transformer framework, leveraging its strong sequential modeling ability to capture long-range dependencies in time-series data, generating more natural and coherent animations.
-
Large-scale pretraining & fine-tuning: Pretrained on massive datasets for general feature representation, then fine-tuned for specific tasks. This strategy leverages both large-scale unsupervised data and targeted supervised learning, enhancing generalization and performance.
Project Links
-
Official site: https://antgroup.github.io/ai/echomimic_v3/
-
GitHub repository: https://github.com/antgroup/echomimic_v3
-
Hugging Face model hub: https://huggingface.co/BadToBest/EchoMimicV3
-
arXiv technical paper: https://arxiv.org/pdf/2507.03905
Application Scenarios
-
Virtual character animation: Generate facial expressions and body movements from audio, text, or images for games, animated films, and VR, creating lifelike characters and enhancing immersion.
-
VFX production: Produce high-quality facial dynamics and body motions quickly for film and TV effects, reducing manual modeling costs and improving production efficiency.
-
Virtual brand ambassadors: In advertising and marketing, create digital spokespeople whose animated content aligns with brand identity, suitable for campaigns and social media promotion.
-
Virtual teachers: In online education, generate animated instructors whose expressions and gestures match teaching content and narration, making learning more engaging.
-
Virtual social interaction: On social platforms, enable users to animate digital avatars with real-time expressions and gestures based on voice or text input, enhancing interactivity and fun.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...