VibeVoice — an open-source text-to-speech (TTS) model released by Microsoft
What is VibeVoice
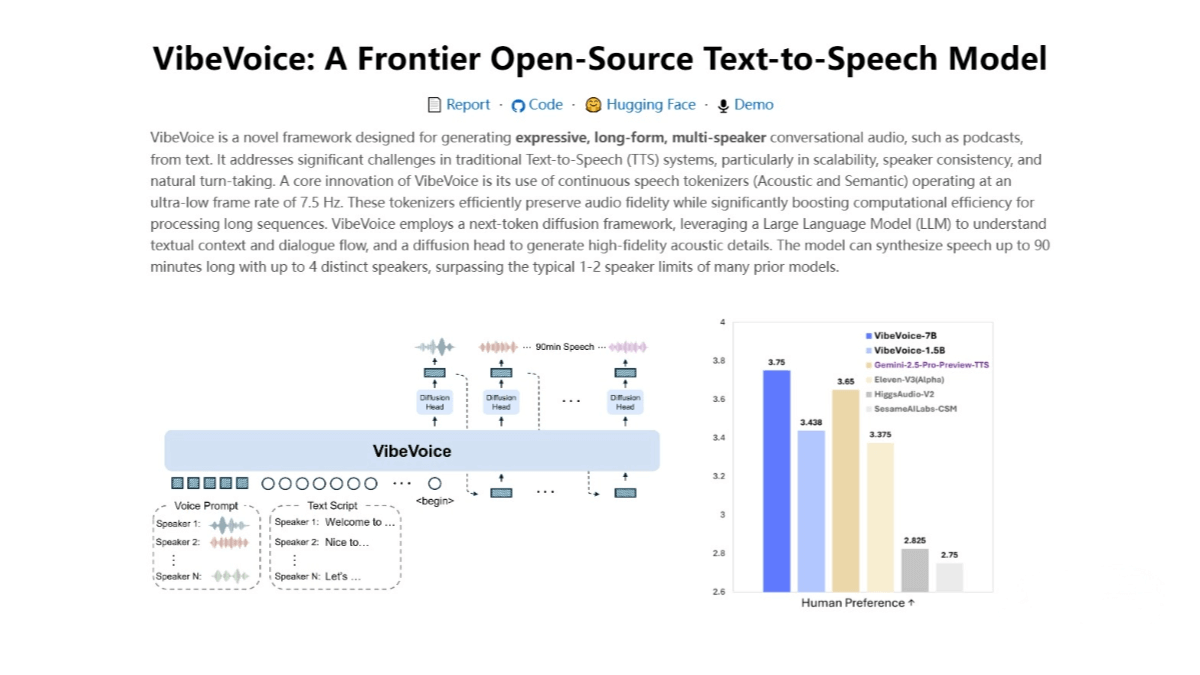
VibeVoice is a new text-to-speech (TTS) model released by Microsoft, designed to generate expressive, long-form, multi-speaker conversational audio—such as podcasts. Leveraging an innovative continuous speech tokenization method and a next-generation token diffusion framework, combined with large language models (LLMs), it enables efficient processing of long-sequence audio while maintaining high fidelity. VibeVoice can synthesize speech up to 90 minutes long, supporting up to four different speakers, breaking through the traditional limitations of TTS systems and opening new possibilities for natural dialogue and emotional expression.
Key Features of VibeVoice
-
Multi-speaker support: Generates conversational audio for up to 4 different speakers, suitable for podcasts, audiobooks, and other scenarios.
-
Long-form dialogue: Can produce continuous speech of up to 90 minutes, overcoming length limitations in traditional TTS systems.
-
Expressive speech: Adds emotion and intonation to speech based on textual context, making dialogue sound more natural and engaging.
-
Cross-language support: Supports speech synthesis in multiple languages, handling multilingual dialogue scenarios.
-
High-fidelity audio: Produces natural, human-like voices for improved user experience.
-
Real-time interaction: Capable of generating speech in real time, enabling dynamic conversations and interactive applications.
Technical Principles of VibeVoice
-
Continuous Speech Tokenization: Audio signals are decomposed into semantic and acoustic tokens. These tokens operate at a very low frame rate (e.g., 7.5 Hz), improving computational efficiency while preserving high fidelity. A semantic tokenizer extracts meaning from text, while an acoustic tokenizer generates detailed audio features.
-
Next-generation Token Diffusion Framework: Based on diffusion models, combined with LLMs to understand textual context and dialogue flow. The diffusion process refines generated audio tokens step by step into high-quality speech.
-
Multi-speaker consistency: Through speaker embeddings, VibeVoice preserves speaker-specific characteristics throughout long-form dialogue, ensuring natural speaker transitions and consistency across multiple voices.
-
High-fidelity audio generation: An advanced vocoder converts generated tokens into natural speech, optimized to closely match human-like sound quality.
Project Links
-
Official site: https://microsoft.github.io/VibeVoice/
-
GitHub repository: https://github.com/microsoft/VibeVoice
-
Hugging Face model collection: https://huggingface.co/collections/microsoft/vibevoice-68a2ef24a875c44be47b034f
-
Technical paper: https://github.com/microsoft/VibeVoice/blob/main/report/TechnicalReport.pdf
Application Scenarios
-
Podcast production: Generate multi-speaker conversational audio (up to 4 voices) lasting up to 90 minutes—ideal for multi-host podcasts with rich, varied content.
-
Audiobooks: Create emotionally expressive narration, making audiobooks more vivid and engaging for listeners.
-
Virtual assistants: Produce natural, fluid speech suitable for interactive voice assistants, enhancing user experience with more human-like interactions.
-
Education & training: Simulate classroom discussions and interactive learning materials, making teaching more engaging through expressive voice output.
-
Entertainment & gaming: Provide expressive voices for virtual characters, enhancing immersion and realism in games and interactive entertainment.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts



No comments yet...