Vid2World – A framework for converting video models into world models, jointly launched by Tsinghua University and Chongqing University
What is Vid2World?
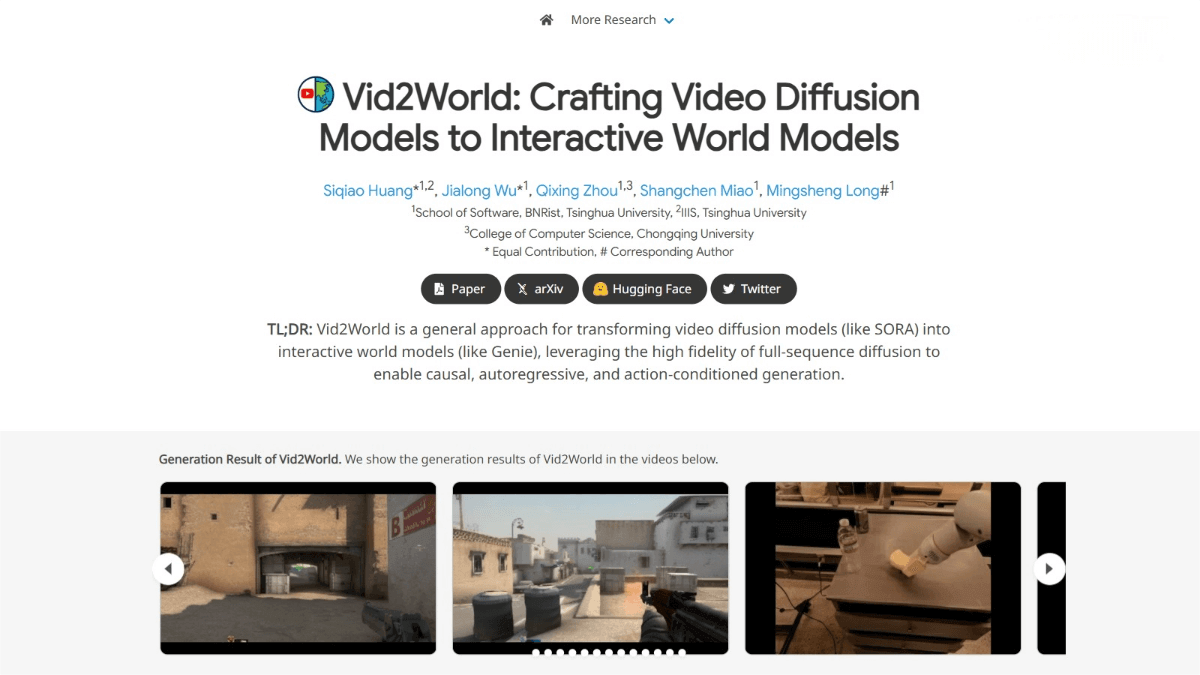
Vid2World is an innovative framework developed by Tsinghua University in collaboration with Chongqing University. It transforms fully sequential, non-causal passive Video Diffusion Models (VDMs) into autoregressive, interactive, and action-conditioned world models. By introducing two core techniques—video diffusion causalization and causal action guidance—Vid2World addresses the limitations of traditional VDMs in causal generation and action conditioning. It demonstrates strong performance in complex environments such as robotic manipulation and game simulation, generating high-fidelity, dynamically consistent video sequences that respond to input actions. Vid2World opens up new possibilities for enhancing the practicality and predictive accuracy of world models.
Key Features of Vid2World
-
High-Fidelity Video Generation:
Produces video predictions that closely match real footage in both visual fidelity and temporal consistency. -
Action Conditioning:
Generates video frames based on a sequence of input actions, supporting fine-grained control over motion. -
Autoregressive Generation:
Videos are generated frame by frame in an autoregressive manner, where each step depends only on past frames and actions. -
Causal Inference:
The model performs causal reasoning, ensuring that predictions are based solely on past information without leakage from the future. -
Support for Downstream Tasks:
Enables applications such as robotic task planning and game simulation, where interactive, action-based predictions are required.
How Vid2World Works: Technical Foundations
-
Video Diffusion Causalization:
Traditional VDMs denoise an entire video sequence simultaneously, which conflicts with causal reasoning since future frames influence past ones. Vid2World modifies pre-trained VDMs to support causal generation:-
Causal Masking in Temporal Attention: Restricts attention mechanisms to access only past frames.
-
Hybrid Weight Transfer in Temporal Convolution: Adapts pre-trained weights for causal convolution while preserving learned knowledge.
-
Diffusion Forcing: Applies independent noise levels per frame during training, allowing the model to learn how to autoregressively generate frames with varying noise levels.
-
-
Causal Action Guidance:
To ensure the model responds accurately to fine-grained actions, Vid2World incorporates a causal action guidance mechanism:-
Each action is encoded via a lightweight MLP and added to the corresponding frame.
-
During training, each action is independently dropped with a fixed probability, forcing the model to learn both conditional and unconditional score functions.
-
At inference, a linear combination of conditional and unconditional scores adjusts the model’s sensitivity to action inputs.
-
This training strategy enables the model to understand how actions affect generation, improving responsiveness during autoregressive prediction.
-
Project Links for Vid2World
-
Official Website: https://knightnemo.github.io/vid2world/
-
HuggingFace Model Hub: https://huggingface.co/papers/2505.14357
-
arXiv Technical Paper: https://arxiv.org/pdf/2505.14357
Application Scenarios for Vid2World
-
Robotic Manipulation:
Generates precise video predictions to assist with robotic planning and execution. -
Game Simulation:
Reconstructs video sequences that mirror real gameplay, facilitating neural game engine development. -
Strategy Evaluation:
Simulates the outcomes of different strategies to support optimization and decision-making. -
Video Prediction:
Predicts future frames from current sequences and actions, useful for video completion and forecasting tasks. -
Virtual Environment Construction:
Creates interactive virtual scenes that respond to action inputs, enhancing realism in VR and simulation environments.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...