
VoiceCanvas – An open-source AI speech synthesis platform that supports multiple languages, various timbres, and voice cloning services
What is VoiceCanvas?
VoiceCanvas is an open-source multilingual speech synthesis platform powered by AI technologies. It offers high-quality text-to-speech (TTS) services in over 50 languages and integrates multiple voice engines, including OpenAI TTS, AWS Polly, and MiniMax. VoiceCanvas also features personal voice cloning, allowing users to create a customized voice by uploading just a few seconds of audio. Ideal for content creators, educators, and businesses, VoiceCanvas significantly boosts the efficiency of voice content production.
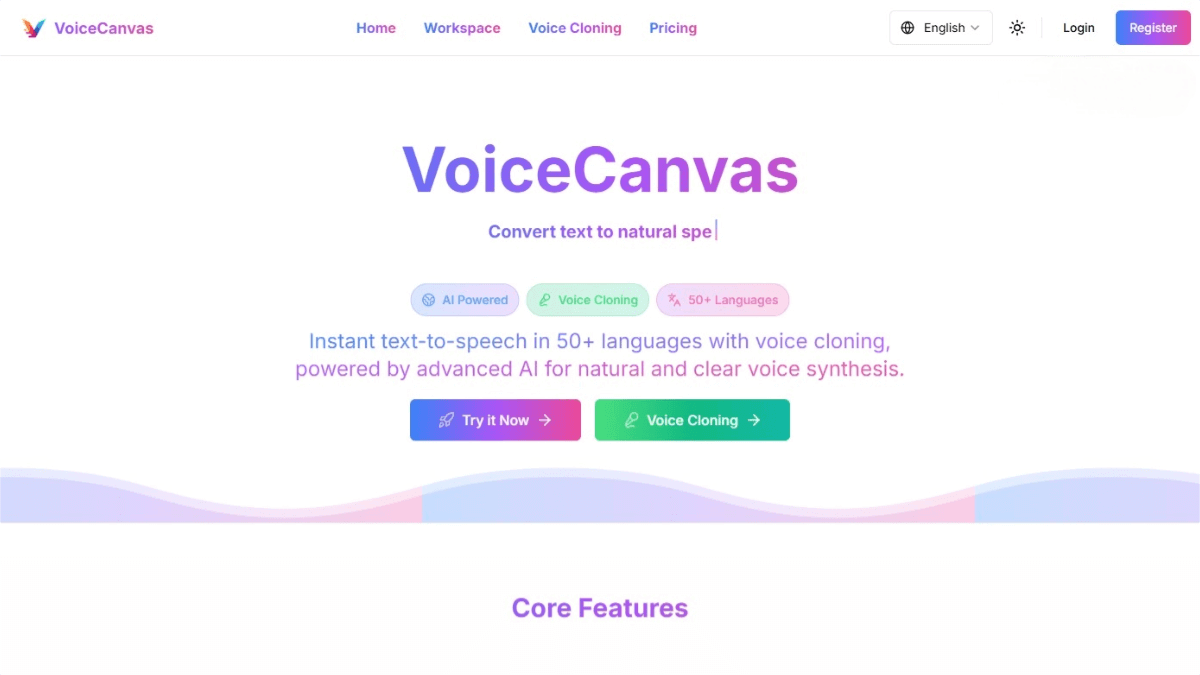
Key Features of VoiceCanvas
-
Multilingual Support: Provides speech synthesis in over 50 languages to meet diverse linguistic needs.
-
Speech Synthesis: Integrates OpenAI TTS, AWS Polly, and MiniMax to deliver high-quality voice output.
-
Voice Cloning: Users can upload a short audio sample to generate a personalized synthetic voice.
-
File Handling: Supports text file uploads and audio file downloads, capable of processing long texts.
-
User System: Offers user registration, login, and third-party authentication (Google, GitHub), with multi-language UI and theme customization.
Technical Principles Behind VoiceCanvas
-
Speech Synthesis Technology:
-
AI-Based Natural Speech Generation: VoiceCanvas uses deep learning models to convert text into natural-sounding speech. These models are trained on large datasets to learn prosody, intonation, and pronunciation rules, producing human-like speech.
-
Integrated Voice Engines: To ensure voice quality and service stability, VoiceCanvas integrates several TTS engines:
-
OpenAI TTS delivers high-fidelity, natural-sounding speech with multiple voice styles.
-
AWS Polly offers broad multilingual support with a wide variety of voices.
-
MiniMax is optimized for Chinese speech synthesis and supports voice cloning capabilities.
-
-
-
Voice Cloning Technology:
-
Voice Feature Extraction: After uploading a few seconds of audio, VoiceCanvas extracts key voice features (such as timbre, pitch, and rhythm) using deep learning algorithms. These features are encoded into model parameters.
-
Personalized Voice Generation: The system generates speech that closely mimics the user’s voice based on the extracted features. This requires substantial data and complex model training to ensure the cloned voice is both natural and consistent.
-
Project Links for VoiceCanvas
-
Official Website: https://voicecanvas.org/
-
GitHub Repository: https://github.com/ItusiAI/Open-VoiceCanvas
Application Scenarios of VoiceCanvas
-
Content Creation: Ideal for dubbing and narration in videos, podcasts, and audiobooks, with support for multilingual versions.
-
Education: Generates voice for online courses, supports language learning, and enhances educational outcomes.
-
Business and Enterprise: Used for customer service voice systems, multilingual content creation, and brand marketing, supporting international operations.
-
Entertainment and Gaming: Provides voiceovers for game characters and interactive voice feedback in entertainment scenarios.
-
Personal Use: Creates voice diaries or voice messages, and helps visually impaired users access audio information.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...