
WhisperLiveKit – Open-Source AI Speech Recognition Tool with Speaker Identification
What is WhisperLiveKit?
WhisperLiveKit is an open-source real-time speech recognition tool that can transcribe speech into text in real time and supports speaker identification. The tool is built on advanced technologies such as SimulStreaming and WhisperStreaming, providing ultra-low latency transcription. All speech data is processed locally to ensure privacy and security. WhisperLiveKit supports multiple languages and can be quickly launched with simple commands, offering both a web interface and a Python API for developers and general users. It is ideal for meetings, subtitle generation, and accessibility assistance, making it a perfect choice for real-time speech recognition.
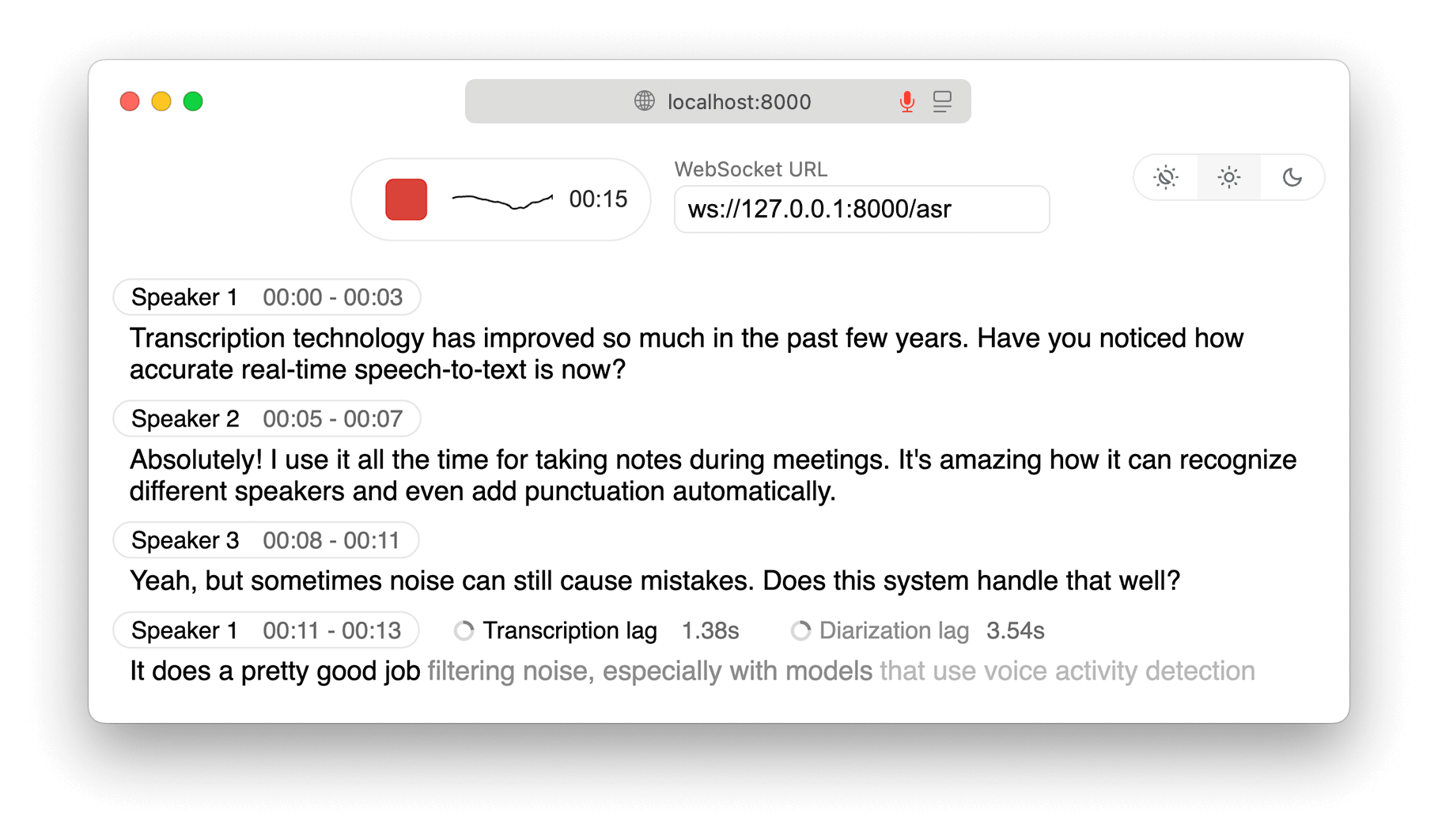
Main Features of WhisperLiveKit
-
Real-Time Speech-to-Text: Supports multiple languages and transcribes speech into text in real time, suitable for meetings, lectures, and other scenarios.
-
Speaker Identification: Automatically distinguishes different speakers, ideal for multi-person meetings to ensure accurate records.
-
Fully Local Processing: Processes all speech data locally to protect privacy, suitable for discussions involving sensitive information.
-
Low-Latency Streaming: Uses advanced algorithms to ensure low-latency real-time transcription for a smooth experience.
-
Multiple Usage Options: Provides a web interface and Python API for both users and developers, with Docker deployment support.
Technical Principles of WhisperLiveKit
-
SimulStreaming: An ultra-low latency transcription algorithm based on the AlignAtt strategy, capable of generating text in real time while speech is being input. It uses intelligent buffering and incremental processing to avoid context loss and inaccurate transcription caused by short speech segments in traditional methods.
-
WhisperStreaming: A low-latency transcription algorithm based on the LocalAgreement strategy, suitable for scenarios requiring fast responses. This provides higher transcription efficiency and better real-time performance, ideal for live subtitles and similar applications.
-
Speaker Diarization: Utilizes advanced speaker recognition technologies, such as Streaming Sortformer and Diart, to distinguish different speakers’ voices in real time. Combined with voice activity detection (VAD) and speaker embedding models, it ensures accurate and real-time speaker identification.
-
Voice Activity Detection (VAD): Uses enterprise-grade VAD technologies such as Silero VAD to accurately detect valid speech segments in audio signals, reducing unnecessary processing. Automatically pauses processing when no speech is detected to save computing resources.
Project Repository
Application Scenarios of WhisperLiveKit
-
Meeting Transcription: Transcribe meeting content in real time and accurately identify different speakers in corporate or academic meetings, enabling quick post-meeting summary creation and improving work efficiency.
-
Online Education: Generate real-time subtitles for online courses and remote teaching, helping students better understand and absorb knowledge.
-
Live Streaming Subtitles: Provide real-time subtitles during live broadcasts in multiple languages, enhancing the viewing experience.
-
Accessibility Assistance: Offer real-time subtitles for the hearing impaired in public spaces or media playback, helping users access spoken information and promoting equal information access.
-
Customer Service Centers: Transcribe conversations in real time during customer service calls, facilitating quality monitoring and data analysis, and improving service efficiency and quality.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...