
Stand-In – A video generation framework launched by Tencent WeChat
What is Stand-In?
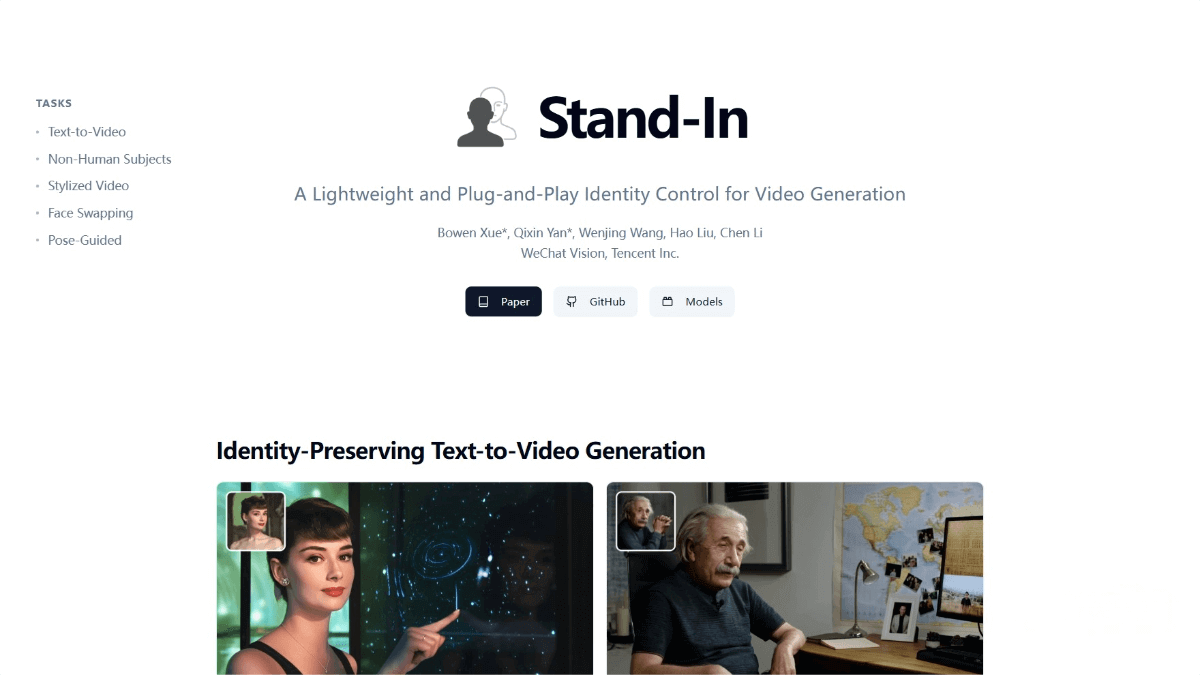
Stand-In is a lightweight video generation framework launched by the Tencent WeChat Vision Team, focusing on identity-preserving video generation. By training only 1% of the base model parameters, the framework can produce high-fidelity, identity-consistent videos. With its plug-and-play design, Stand-In can be easily integrated into existing text-to-video (T2V) models.
Stand-In supports a wide range of applications, including identity-preserving text-to-video generation, non-human subject video generation, stylized video generation, face swapping, and pose-guided video generation. It is efficient, flexible, and highly scalable.
Main Features of Stand-In
-
Identity-preserving text-to-video generation: Generates videos consistent with the identity in the reference image based on textual descriptions, ensuring that personal features remain stable.
-
Non-human subject video generation: Produces videos featuring non-human subjects, such as cartoon characters or objects, while maintaining subject coherence.
-
Identity-preserving stylized video generation: Applies artistic styles (e.g., oil painting or anime) to videos while retaining personal identity features.
-
Face swapping: Replaces the face in a video with that of a reference image, achieving high-fidelity substitution while keeping the video natural and coherent.
-
Pose-guided video generation: Generates videos of characters following input pose sequences, enabling precise motion control.
Technical Principles of Stand-In
-
Conditional image branch: Introduces a conditional image branch into the pretrained video generation model. A pretrained VAE (Variational Autoencoder) encodes the reference image into the same latent space as the video, extracting rich facial features.
-
Restricted self-attention mechanism: Implements identity control via restricted self-attention, allowing video features to effectively reference identity information from the reference image while maintaining independence. Conditional Position Mapping is used to distinguish image and video features, ensuring accurate and efficient information exchange.
-
Low-Rank Adaptation (LoRA): Enhances the model’s ability to leverage identity information while keeping it lightweight. LoRA fine-tunes only the QKV projections of the conditional image branch, minimizing additional training parameters.
-
KV caching: The reference image is fixed at time step zero, and its Key and Value matrices remain constant during the diffusion denoising process. Caching these matrices during inference accelerates computation.
-
Lightweight design: Stand-In trains approximately 1% additional parameters, significantly reducing training costs and computational overhead. This enables easy integration into existing T2V models with strong scalability and compatibility.
Project Links for Stand-In
-
Official Website: https://www.stand-in.tech/
-
GitHub Repository: https://github.com/WeChatCV/Stand-In
-
Hugging Face Model Hub: https://huggingface.co/BowenXue/Stand-In
-
arXiv Paper: https://arxiv.org/pdf/2508.07901
Application Scenarios of Stand-In
-
Virtual character generation: Creates consistent virtual characters for films, TV series, and animations.
-
Special effects synthesis: Rapidly generates identity-consistent virtual characters for VFX, reducing the complexity of post-production.
-
Personalized advertising: Produces personalized ad videos based on user-provided reference images, enhancing engagement and appeal.
-
Virtual brand ambassadors: Builds virtual spokespersons for brand promotion and product marketing, ensuring consistency and coherence of brand image.
-
Character customization: Allows players to generate in-game characters based on their own likeness, enhancing immersion and personalization.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts




No comments yet...