What is LLaSO?
LLaSO (Large Language and Speech Model) is the world’s first fully open-source speech model, released by Beijing Deep Logic Intelligence Technology Co., Ltd. It addresses long-standing challenges in the field of Large Speech-Language Models (LSLM), such as fragmented architectures, privatized datasets, limited task coverage, and single-modality interactions.
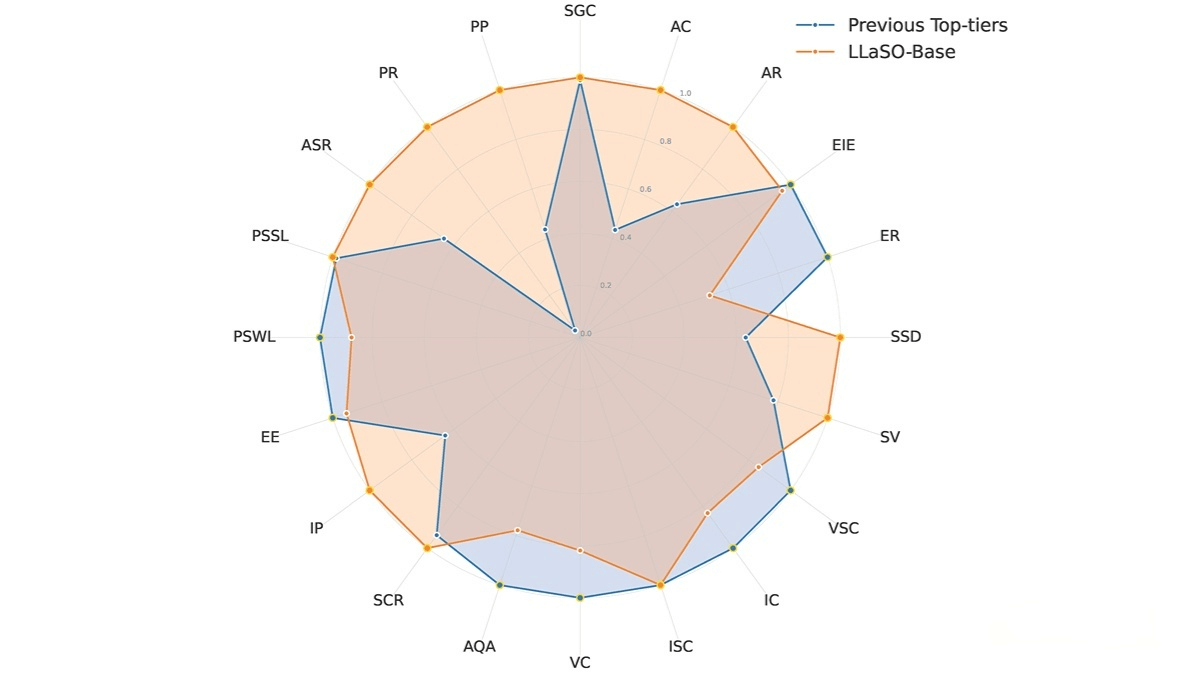
LLaSO consists of three core components: LLaSO-Align (a large-scale speech-text alignment dataset), LLaSO-Instruct (a multi-task instruction-tuning dataset), and LLaSO-Eval (a standardized evaluation benchmark). Together, they provide unified, transparent, and reproducible infrastructure for LSLM research, shifting the field from fragmented efforts to collaborative innovation.
Main Functions of LLaSO
-
Dataset Provision: LLaSO-Align offers large-scale speech-text alignment data, while LLaSO-Instruct provides multi-task instruction-tuning data, supplying rich resources for model training.
-
Model Training & Validation: The LLaSO-Base model, trained on LLaSO datasets, serves as a performance baseline to help researchers compare and validate different models.
-
Standardized Evaluation: LLaSO-Eval delivers standardized benchmarks, ensuring fairness and reproducibility in model evaluation.
-
Multimodal Support: Supports multiple modalities, including “text instruction + audio input,” “audio instruction + text input,” and pure audio interaction, expanding the model’s application scenarios.
Technical Principles of LLaSO
-
Speech-Text Alignment: Using Automatic Speech Recognition (ASR), speech data is precisely aligned with text data to establish mappings between speech representations and textual semantic space.
-
Multi-task Instruction Tuning: The model is fine-tuned with diverse task data covering linguistic, semantic, and paralinguistic tasks, enhancing its comprehensive understanding and generative abilities.
-
Modality Projection: Techniques such as Multi-Layer Perceptrons (MLP) are used to map between speech and text features, enabling the model to handle multimodal inputs.
-
Two-Stage Training Strategy: Training proceeds in two stages: speech-text alignment followed by multi-task instruction tuning, progressively improving model performance and generalization.
-
Standardized Evaluation Benchmark: Benchmarks covering a wide range of tasks ensure comprehensive, systematic, and comparable evaluations of model performance.
Project Resources
-
GitHub Repository: https://github.com/EIT-NLP/LLaSO
-
HuggingFace Model Hub: https://huggingface.co/papers/2508.15418
-
arXiv Paper: https://arxiv.org/pdf/2508.15418v1
Application Scenarios of LLaSO
-
Intelligent Voice Assistants: For smart home control, customer service, in-car assistants, and more. Voice commands enable device control and information retrieval, enhancing user experience.
-
Voice Content Creation: Generates speech-based content such as audiobooks, podcasts, and voice advertisements, producing natural and fluent speech from text to improve content creation efficiency.
-
Education & Learning: Provides personalized learning experiences, including pronunciation practice and oral assessments via voice commands, helping learners improve outcomes.
-
Healthcare: Assists doctors with voice recording and diagnostics, supports patients in speech rehabilitation training, and improves both efficiency and recovery outcomes.
-
Smart Customer Service: Offers customer support through voice interaction, understanding user issues and generating accurate responses, thereby improving service efficiency and satisfaction.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...