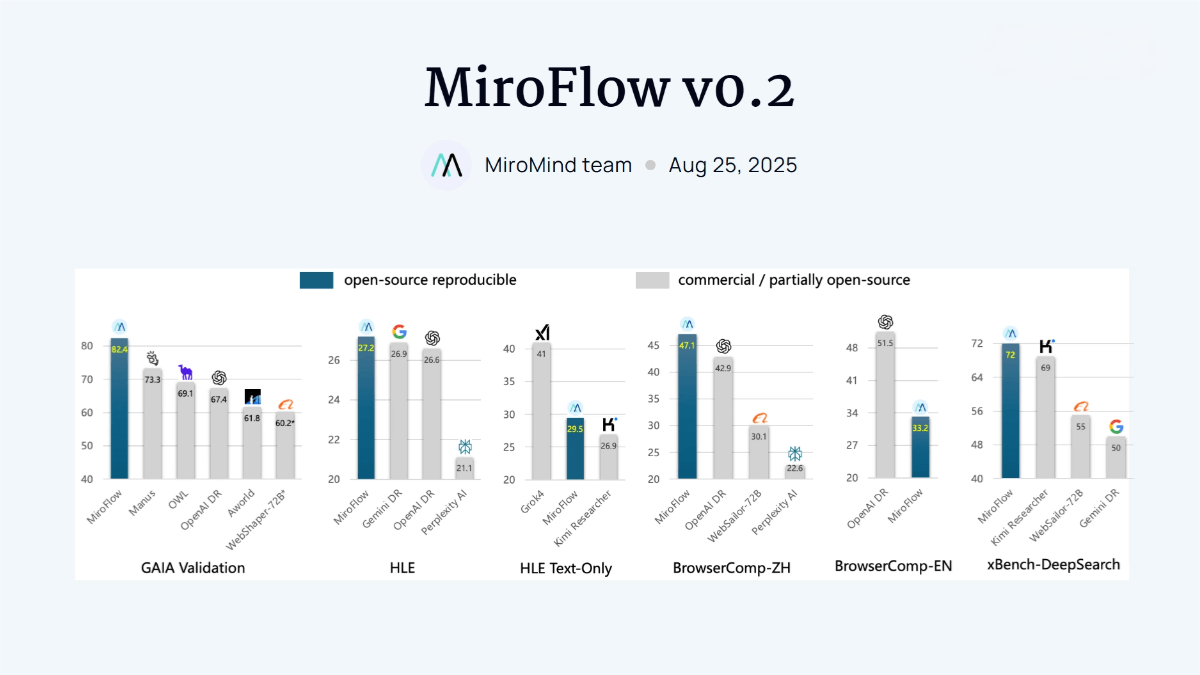
LatticeWorld – A multimodal 3D world generation framework launched by NetEase, Tsinghua University, and others
What is LatticeWorld?
LatticeWorld is a multimodal 3D world generation framework jointly developed by NetEase, City University of Hong Kong, Beihang University, and Tsinghua University. It combines large language models with the industrial-grade 3D rendering engine Unreal Engine 5 (UE5), enabling rapid creation of large-scale interactive 3D worlds with highly dynamic environments, realistic physics simulation, and real-time rendering based on text descriptions and visual instructions.
The framework consists of three core modules: scene layout generation, environment configuration generation, and a procedural rendering pipeline. Compared to traditional manual workflows, LatticeWorld improves creative efficiency by more than 90x while delivering high-quality results. It shows strong potential for applications in gaming, film production, and beyond.

Key Features of LatticeWorld
-
Rapid 3D World Generation: Quickly builds large-scale, interactive 3D worlds with dynamic environments, realistic physics, and real-time rendering based on text and visual inputs—achieving massive efficiency gains over manual creation.
-
Diverse Scene Generation: Supports the creation of varied environments such as suburbs, wilderness, and more to meet different user needs.
-
Dynamic Interactive Environments: Generates dynamic agent configurations (e.g., agent type, number, behavioral state, and spatial position), making the 3D worlds more interactive and lifelike.
-
Multimodal Input Support: Accepts both textual descriptions and visual conditions, allowing flexible input methods to generate worlds that better align with user requirements.
Technical Principles of LatticeWorld
-
Multimodal Input Processing: Converts text and visual inputs into symbolic scene layouts and environment configuration parameters, providing the foundation for 3D world generation.
-
Symbolic Sequence Scene Representation: Encodes complex spatial layouts into symbolic matrices (e.g., F for forest, W for water), serialized into strings that large language models can directly process, preserving spatial relationships.
-
Multimodal Visual Fusion: Uses a pretrained CLIP vision encoder to extract high-dimensional features, mapped into word embeddings through a custom CNN projection network. A three-stage training paradigm—CLIP fine-tuning, continual pretraining, and end-to-end fine-tuning—jointly optimizes the visual instruction integration and layout generation models.
-
Hierarchical Scene Attribute Framework: Defines attributes at two levels—coarse-grained (e.g., terrain type, season, weather) and fine-grained (e.g., material, density, orientation)—ensuring semantic consistency and reducing parameter conflicts.
-
Procedural Rendering Pipeline: Uses a scene layout decoder and environment configuration translator to transform symbolic layouts and JSON parameters into inputs for the rendering engine. This pipeline precisely controls object and agent types, states, and spatial distributions while ensuring natural transitions and realistic rendering.
Project Resources
-
Technical paper on arXiv: https://arxiv.org/pdf/2509.05263
Application Scenarios
-
Game Development: Rapidly prototype game worlds, including terrain, buildings, and vegetation, accelerating production.
-
Film Production: Build complex virtual sets—such as alien planets or historical cities—while reducing the cost of physical set construction.
-
Virtual Reality (VR) & Augmented Reality (AR): Create immersive environments for virtual tourism, education, and other experiences.
-
Urban Planning: Quickly generate virtual city models (streets, buildings, parks) for preliminary research and visualization.
-
Education & Training: Produce virtual labs and historical environments to deliver immersive learning experiences.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...