What is Qwen3-LiveTranslate?
Qwen3-LiveTranslate is a multilingual real-time audio-video simultaneous translation model developed by Alibaba Tongyi, based on large language model technology. The model supports translation in 18 languages and multiple dialects, and features vision-enhanced capabilities that leverage lip movements, gestures, and other multimodal information to improve translation accuracy. With low latency (as low as 3 seconds) and lossless simultaneous translation technology, it ensures translation quality close to offline translation, accompanied by natural-sounding voices. The model performs exceptionally well in complex acoustic environments, bridging language barriers and making communication smoother and more natural.
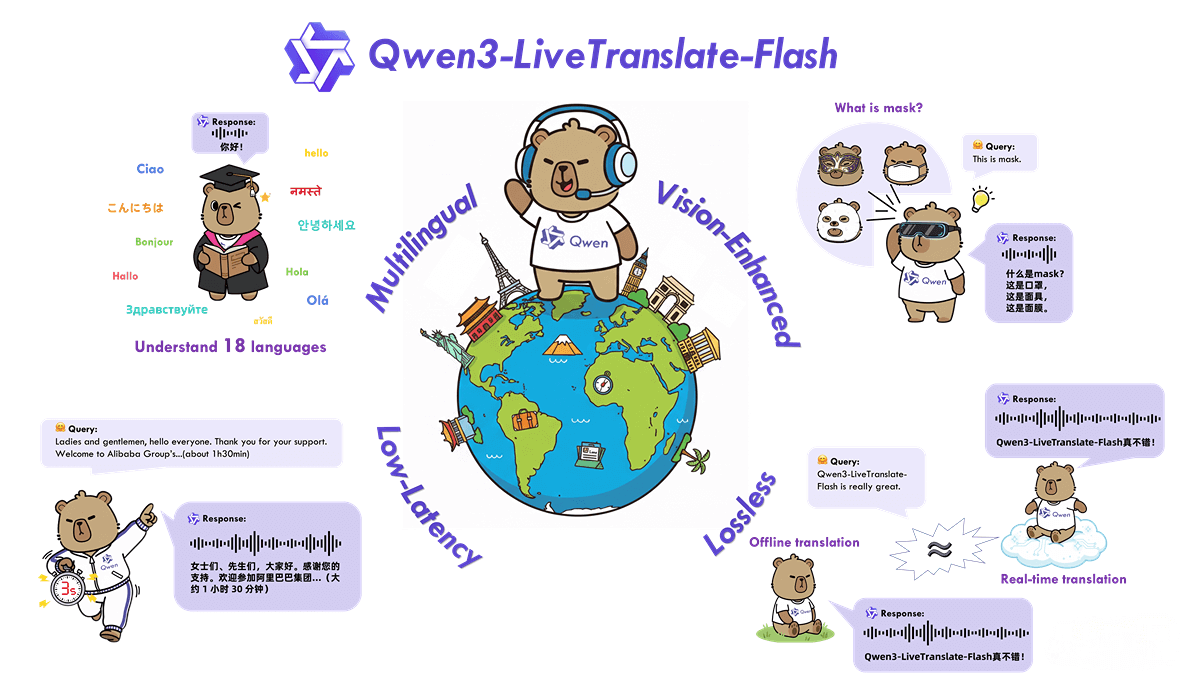
Key Features of Qwen3-LiveTranslate
-
Multilingual Real-Time Translation: Supports 18 languages (e.g., Chinese, English, French, German, Japanese, Korean, etc.) and multiple dialects (e.g., Mandarin, Cantonese, Sichuanese) for both offline and real-time audio-video translation.
-
Vision-Enhanced Translation: Integrates visual context such as lip movements, gestures, and text to improve translation accuracy in noisy environments or when words have multiple meanings.
-
Low-Latency Simultaneous Translation: Achieves a simultaneous translation experience with a minimum of 3 seconds latency using a lightweight mixture-of-experts architecture and dynamic sampling strategy.
-
Lossless Translation Quality: Semantic unit prediction technology mitigates cross-language word order issues, ensuring translation quality comparable to offline translation.
-
Natural Voice Output: Adapts tone and expressiveness based on the original speech content to generate human-like audio.
Technical Principles of Qwen3-LiveTranslate
-
Multimodal Data Fusion: Combines speech, visual, and other multimodal data to enhance the model’s understanding of context.
-
Semantic Unit Prediction: Analyzes the semantic structure of language to predict word order issues in cross-language translation, ensuring accuracy and fluency.
-
Lightweight Mixture-of-Experts Architecture: Uses a lightweight mixture-of-experts system with dynamic sampling strategies to optimize computational resource allocation and reduce latency.
-
Training on Large-Scale Audio-Video Data: Trained on massive multilingual audio-video datasets to improve adaptation to various languages and dialects.
-
Vision Enhancement Technology: Employs computer vision to recognize lip movements, gestures, and other visual cues to assist speech translation, improving accuracy and robustness.
Project Links for Qwen3-LiveTranslate
-
Official Website: https://qwen.ai/blog?id=b2de6ae8555599bf3b87eec55a285cdf496b78e4&from=research.latest-advancements-list
-
Online Demo: https://huggingface.co/spaces/Qwen/Qwen3-Livetranslate-Demo
Application Scenarios of Qwen3-LiveTranslate
-
International Conferences: Provides real-time multilingual translation for international conferences, ensuring participants from different language backgrounds can instantly understand content, enhancing communication efficiency.
-
Remote Education: Translates teachers’ lectures in real-time into students’ native languages, breaking language barriers and enabling seamless global learning.
-
Cross-Border Business Communication: Supports low-latency real-time translation for multinational companies during negotiations, phone calls, and meetings, ensuring smooth communication and preventing misunderstandings.
-
Travel and Tourism: Enables tourists to communicate effortlessly with locals in foreign countries through real-time voice translation, solving language challenges.
-
Media Broadcasting: In international news, sports events, and live streaming scenarios, translates the broadcaster’s voice into multiple languages in real-time, allowing a global audience to watch simultaneously and enhancing international influence.