StableAvatar – An audio-driven video generation model developed by Fudan University
What is StableAvatar?
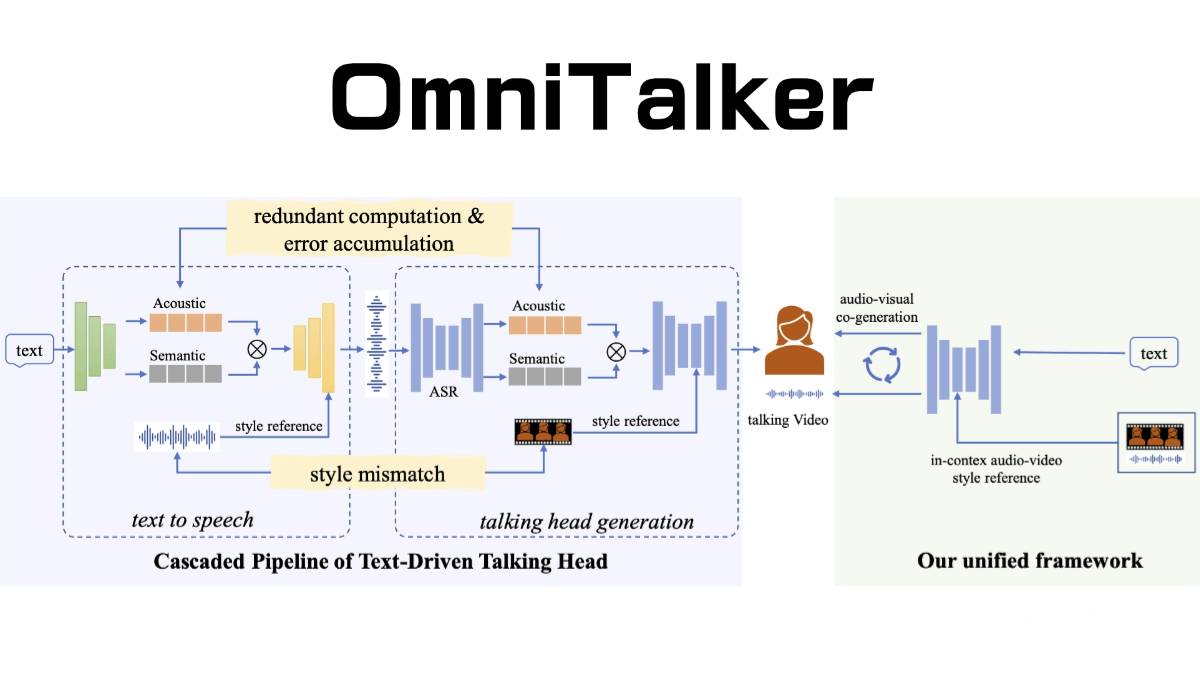
StableAvatar is an innovative audio-driven virtual avatar video generation model developed by Fudan University, Microsoft Research Asia, and others. The model leverages an end-to-end video diffusion transformer combined with a timestep-aware audio adapter, an audio-native guidance mechanism, and a dynamic weighted sliding window strategy to generate high-quality virtual avatar videos of unlimited length. It addresses the challenges of identity consistency, audio synchronization, and video smoothness in long-form video generation, significantly enhancing naturalness and coherence. StableAvatar is well-suited for scenarios such as virtual reality and digital human creation.
![]()
Key Features of StableAvatar
-
High-quality long video generation: Capable of producing high-quality virtual avatar videos exceeding 3 minutes, while maintaining identity consistency and audio synchronization.
-
No post-processing required: Directly generates videos without relying on any post-processing tools (e.g., face-swapping or facial restoration models).
-
Versatile applications: Supports animation of full-body, half-body, multi-person, and cartoon avatars, applicable to virtual reality, digital human creation, virtual assistants, and more.
Technical Principles of StableAvatar
-
Timestep-aware audio adapter: Uses timestep-aware modulation and cross-attention to align audio embeddings with latent representations and timestep embeddings, reducing error accumulation in latent distributions. This allows the diffusion model to more effectively capture the joint distribution of audio and latent features.
-
Audio-native guidance mechanism: Replaces traditional classifier-free guidance (CFG) by directly steering the diffusion sampling distribution toward the joint audio-latent space. The model leverages its evolving joint audio-latent predictions during denoising as dynamic guidance signals, improving audio synchronization and the naturalness of facial expressions.
-
Dynamic weighted sliding window strategy: During long video generation, latent representations are fused via a dynamic weighted sliding window with logarithmic interpolation, which reduces discontinuities between video segments and improves smoothness.
Project Resources
-
Official Website: https://francis-rings.github.io/StableAvatar/
-
GitHub Repository: https://github.com/Francis-Rings/StableAvatar
-
HuggingFace Model Hub: https://huggingface.co/FrancisRing/StableAvatar
-
arXiv Paper: https://arxiv.org/pdf/2508.08248
Application Scenarios of StableAvatar
-
Virtual Reality (VR) and Augmented Reality (AR): Generates high-quality virtual avatar videos to deliver more realistic and natural VR/AR experiences, enhancing immersion.
-
Virtual Assistants and Customer Service: Provides avatars with natural facial expressions and body movements that respond to speech input in real time, improving user interaction.
-
Digital Human Creation: Rapidly produces digital human videos with high identity consistency and natural actions, supporting full-body, multi-person, and cartoon avatars to meet diverse needs.
-
Film and Media Production: Enables efficient generation of high-quality virtual character animations, reducing time and cost of visual effects production while improving quality.
-
Online Education and Training: Creates virtual teachers or trainers that animate naturally according to speech content, enhancing interactivity and engagement in learning experiences.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...