TRUEBench – Samsung’s Open-Source AI Performance Benchmarking Tool
What is TRUEBench?
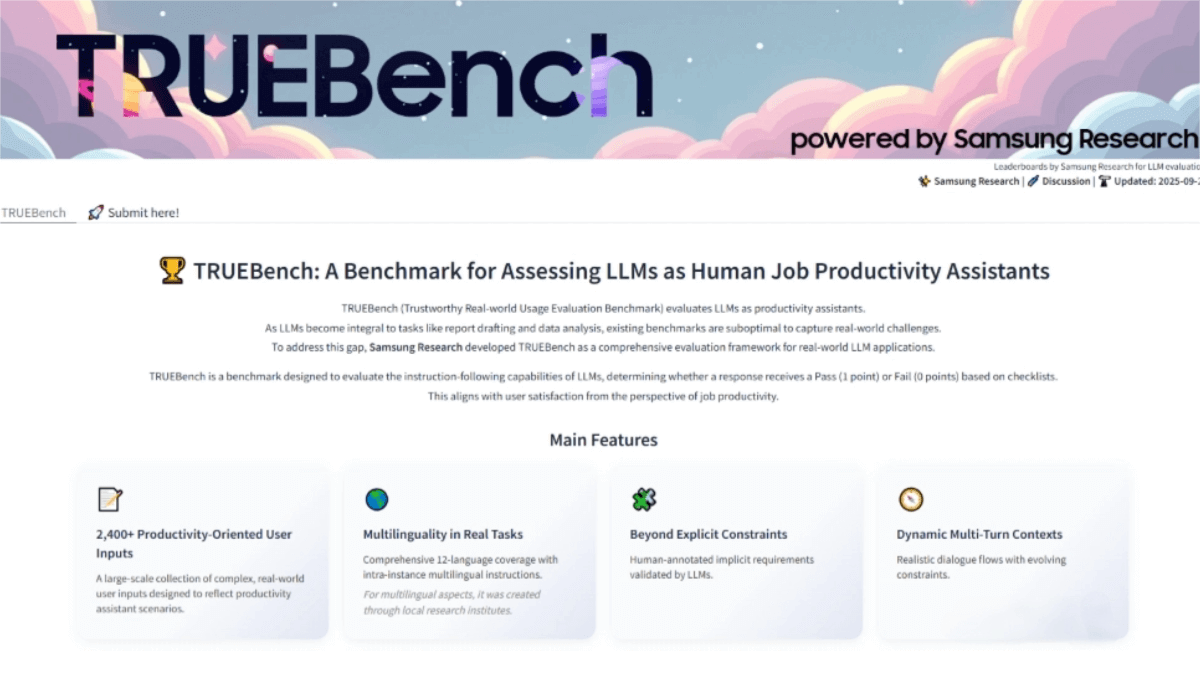
TRUEBench (Trustworthy Real-world Usage Evaluation Benchmark) is an AI benchmarking tool developed by Samsung Electronics to evaluate the productivity of artificial intelligence in real-world work scenarios. It addresses the limitations of existing AI benchmarks, such as their English-centric focus and single-turn question-answer structures. TRUEBench includes 2,485 test sets across 10 categories and 12 languages, supporting cross-lingual evaluation. By combining human–AI collaboration in designing and refining evaluation criteria, TRUEBench ensures accuracy and consistency. The dataset and leaderboard are available on Hugging Face, where users can compare up to five AI models in terms of performance and efficiency.
Key Features of TRUEBench
-
Comprehensive AI Productivity Evaluation:
TRUEBench assesses commonly used enterprise tasks across 10 categories and 46 subcategories, including content generation, data analysis, text summarization, and translation. -
Multilingual Support:
Supports 12 languages, including Korean, English, Japanese, and others. -
Diverse Testing Scenarios:
Includes 2,485 test sets, ranging from 8 characters to over 20,000 characters, covering tasks from simple queries to long-document summarization. -
Reliable Scoring System:
Built on a human–AI co-designed evaluation framework, ensuring high accuracy and consistency. -
Open Data and Leaderboard:
TRUEBench’s datasets and leaderboard are publicly available on Hugging Face, allowing users to test and compare up to five AI models.
Technical Principles of TRUEBench
-
Human–AI Collaborative Evaluation Design:
Human annotators first create evaluation criteria, which are then reviewed by AI systems to detect errors, contradictions, or unnecessary constraints. Human experts refine the criteria iteratively, producing increasingly precise evaluation standards. -
Automated AI Evaluation:
Based on these cross-validated standards, TRUEBench conducts automatic AI assessments, minimizing subjective bias and ensuring consistent evaluation results. -
Multilingual and Cross-lingual Testing:
TRUEBench is designed with multilingual and cross-lingual test sets, enabling a comprehensive evaluation of AI model performance across diverse language environments.
Project Links
-
Official Website: https://news.samsung.com/global/samsung-introduces-truebench-a-benchmark-for-real-world-ai-productivity
-
Hugging Face Demo: https://huggingface.co/spaces/SamsungResearch/TRUEBench
Application Scenarios of TRUEBench
-
Content Generation:
Evaluates AI performance in report writing, email drafting, and copywriting, helping enterprises and developers assess AI’s creative and productivity capabilities. -
Data Analysis:
Tests AI’s ability to process and interpret data, such as generating charts or explaining analytical results, measuring its practical utility in data-driven tasks. -
Text Summarization:
Measures AI efficiency in extracting key information and producing concise summaries, suitable for use cases requiring quick information extraction. -
Translation:
Evaluates AI accuracy and fluency in cross-lingual translation tasks, supporting multilingual and global business applications. -
Multilingual Evaluation:
By supporting multiple languages, TRUEBench enables global applicability in evaluating AI systems across diverse linguistic environments, meeting multilingual performance needs.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts



No comments yet...