Just now, OpenAI has released GPT – 4.1! It supports up to one million tokens in context across the entire series, comprehensively outperforming GPT – 4o and with a lower price.
The new series model GPT – 4.1 of OpenAI has arrived as scheduled.
This series includes three models, namely GPT – 4.1, GPT – 4.1 mini and GPT – 4.1 nano. They can only be called via API and have been opened to all developers.
As this series of models provides similar or stronger performance in many key features while having lower cost and latency, OpenAI will start to deprecate GPT – 4.5 preview in the API. The deprecation will occur three months later (July 14, 2025) to give developers time to transition.
OpenAI stated that the performance of these three models comprehensively surpasses that of GPT – 4o and GPT – 4o mini, and there are significant improvements in programming and instruction following. They also have a larger context window – supporting up to 1 million context tokens, and can make better use of these contexts through improved long – context understanding. The knowledge cutoff date has been updated to June 2024.
In general, GPT-4.1 performs excellently on the following industry-standard metrics:
- Programming: GPT-4.1 achieves a score of 54.6% in the SWE-bench Verified test, representing a 21.4% improvement over GPT-4o and a 26.6% improvement over GPT-4.5, making it the leading programming model.
- Instruction Following: In Scale’s MultiChallenge benchmark (a metric for measuring instruction-following ability), GPT-4.1 scores 38.3%, a 10.5% improvement over GPT-4o.
- Long Context: In the multimodal long-context understanding benchmark Video-MME, GPT-4.1 sets a new record high — achieving a score of 72.0% in the long unannotated video test, a 6.7% improvement over GPT-4o.
Although the benchmark test results are very impressive, OpenAI focused on practical utility when training these models. Through close collaboration and partnerships with the developer community, OpenAI optimized these models for the tasks most relevant to developers’ applications.
To this end, the GPT-4.1 model series delivers excellent performance at a lower cost. These models achieve performance improvements at every point on the latency curve.
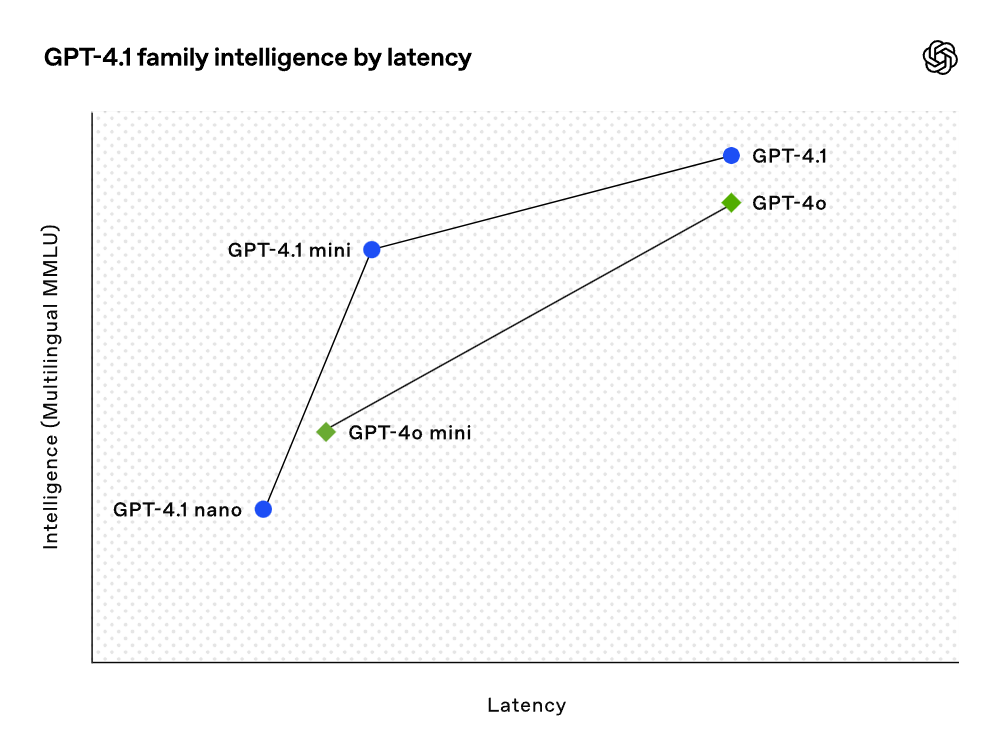
GPT-4.1 mini has achieved a significant leap in performance among small models, even surpassing GPT-4o in multiple benchmark tests. This model matches or even exceeds GPT-4o in intelligence evaluation while reducing latency by nearly half and cutting costs by 83%.
For tasks requiring low latency, GPT-4.1 nano is currently the fastest and most cost-effective model offered by OpenAI. This model features a 1-million-token context window and delivers exceptional performance on a smaller scale. It achieves a score of 80.1% on the MMLU test, 50.3% on the GPQA test, and 9.8% on the Aider multilingual coding test, outperforming even GPT-4o mini. This model is an ideal choice for tasks such as classification or autocomplete.
Improvements in instruction-following reliability and long-context understanding have also made the GPT-4.1 model more efficient in driving agents (i.e., systems capable of independently completing tasks on behalf of users). Combined with primitives such as the Responses API, developers can now build agents that are more useful and reliable in practical software engineering, extracting insights from large documents, resolving customer requests with minimal manual intervention, and performing other complex tasks.
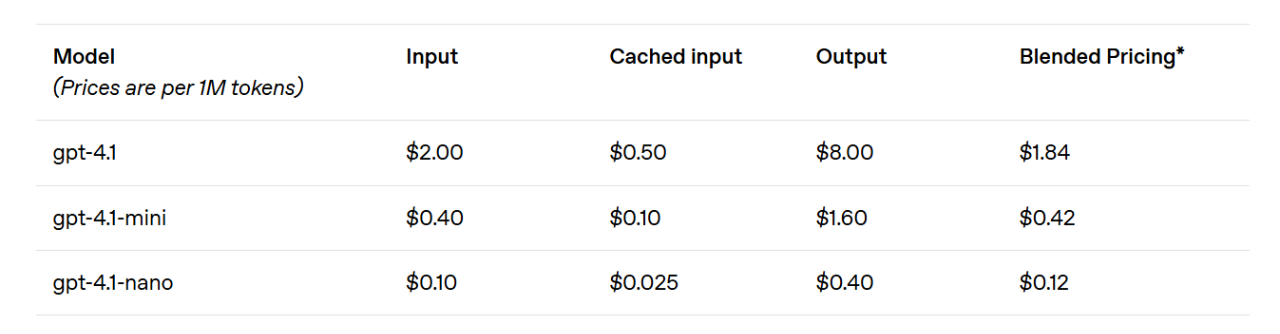
At the same time, by improving the efficiency of the reasoning system, OpenAI has been able to reduce the price of the GPT-4.1 series. The cost of medium-scale queries for GPT-4.1 is 26% lower than that of GPT-4o, while GPT-4.1 nano is the cheapest and fastest model OpenAI has introduced so far.
For queries that repeatedly convey the same context, OpenAI has increased the instant caching discount for its new series of models from the previous 50% to 75%. Additionally, apart from the standard cost per token, OpenAI also offers long-context requests at no extra charge.
OpenAI CEO Sam Altman stated that GPT-4.1 not only achieves excellent results in benchmark tests but also focuses on real-world practicality, which is expected to delight developers.
It seems that OpenAI has achieved a situation where the capabilities of its own model satisfy “4.10 > 4.5”.
Programming
GPT-4.1 significantly outperforms GPT-4o in various coding tasks, including agent-based coding problem-solving, front-end programming, reducing irrelevant edits, reliably following the diff format, and ensuring consistency in tool usage.
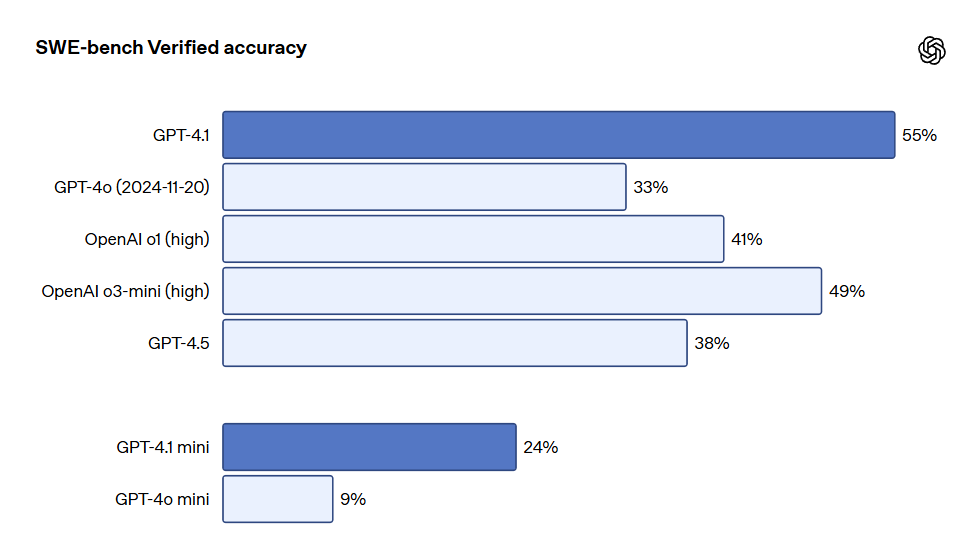
In the SWE-bench Verified test, which measures real-world software engineering skills, GPT-4.1 completed 54.6% of the tasks, while GPT-4o (2024-11-20) achieved 33.2%. This reflects the model’s improved ability to explore codebases, complete tasks, and generate runnable and test-passing code.
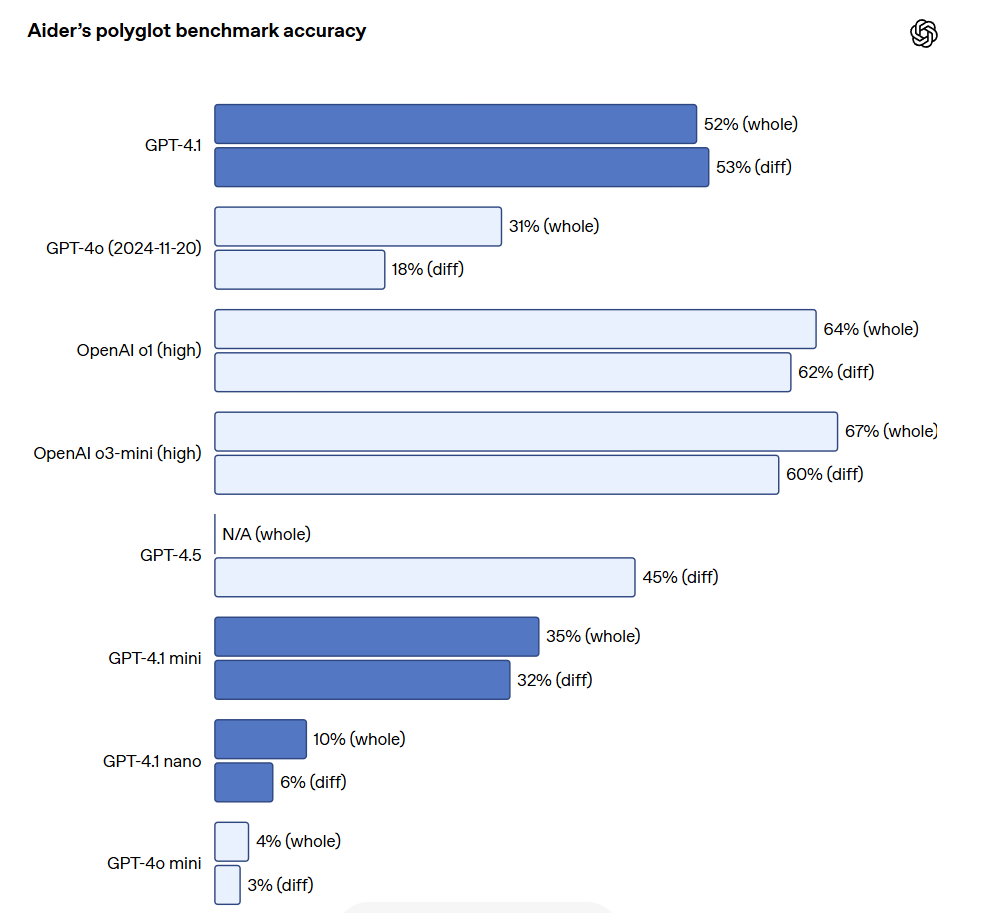
For API developers who need to edit large files, GPT-4.1 is more reliable in handling code diffs in various formats. In Aider’s multilingual diff benchmark test, GPT-4.1 scored more than twice as high as GPT-4o and even outperformed GPT-4.5 by 8%. This evaluation measures both the coding ability across multiple programming languages and the model’s ability to generate changes in overall and diff formats.
OpenAI has specifically trained GPT – 4.1 to more reliably follow the diff format. This enables developers to only output the changed lines instead of rewriting the entire file, saving costs and reducing latency. Meanwhile, for developers who prefer to rewrite the entire file, OpenAI has increased the output token limit of GPT – 4.1 to 32,768 tokens (higher than the 16,384 tokens of GPT – 4o). OpenAI also recommends using predictive output to reduce the latency of full – file rewrites.
GPT-4.1 has also shown significant improvements in front-end programming compared to GPT-4o, capable of creating more powerful and visually appealing web applications. In head-to-head comparisons, 80% of the ratings from paid human evaluators indicate that websites generated by GPT-4.1 are more popular than those created by GPT-4o.
Besides the aforementioned benchmark tests, GPT-4.1 performs better in following formats, demonstrates higher reliability, and reduces the frequency of irrelevant edits. In OpenAI’s internal evaluations, the rate of irrelevant edits in code decreased from 9% with GPT-4o to 2% with GPT-4.1.
Instruction following
GPT-4.1 can follow instructions more reliably and has achieved significant improvements in various instruction-following evaluations. OpenAI has developed an internal instruction-following evaluation system to track the model’s performance across multiple dimensions and several key instruction execution categories, including:
- Format the following text according to the specified format. For example, XML, YAML, Markdown, etc.
- Negative instructions. Specify the behaviors that the model should avoid, such as: “Do not ask the user to contact support staff”.
- Ordered instructions. Provide a set of instructions that the model must follow in the given order, such as: “First, ask for the user’s name, and then ask for their email address”.
- Content requirements. The output must contain specific information, such as: “When writing a nutrition plan, be sure to include the protein content”.
- Sorting. Sort the output in a specific way, such as: “Sort the responses by population size”.
- Overconfidence. Instruct the model to answer with something like “I don’t know” when the requested information is unavailable or the request does not belong to the given category, such as: “If you don’t know the answer, provide the support contact email address”.
“These categories are derived from developer feedback, indicating which types of instructions are most relevant and important to them. Within each category, OpenAI classifies prompts into simple, medium, and difficult levels. GPT-4.1 performs particularly better than GPT-4o in handling difficult prompts.”
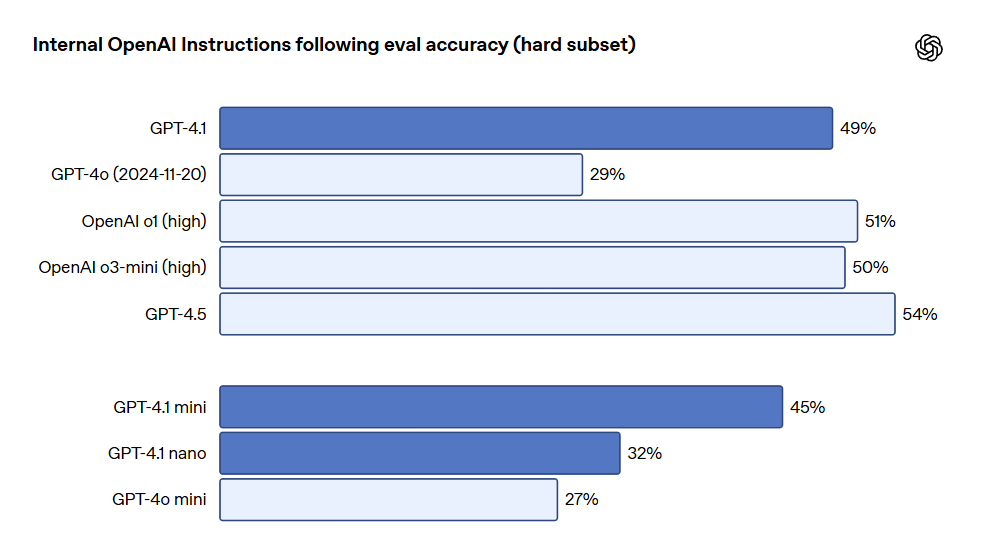
Multi-turn instruction following is crucial for many developers. For models, it is essential to maintain coherence during conversations and keep track of what users have input previously. GPT-4.1 can better identify information from past messages in the conversation, thus achieving more natural dialogues. The Scale’s MultiChallenge benchmark is an effective metric for measuring this ability. GPT-4.1 performs 10.5% better than GPT-4o in this regard.
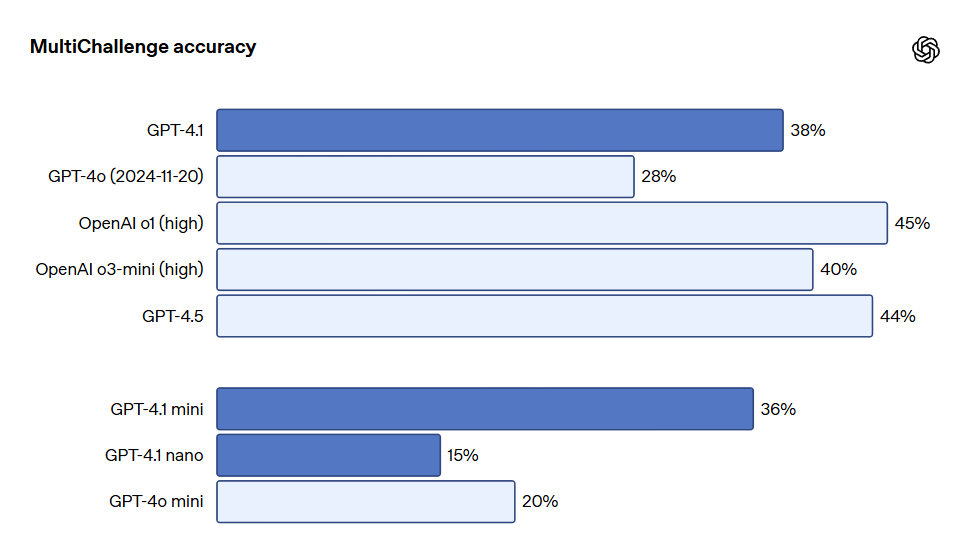
GPT-4.1 also achieved 87.4% on IFEval, while GPT-4o scored 81.0%. IFEval uses prompts with verifiable instructions, such as specifying content length or avoiding certain terms or formats.
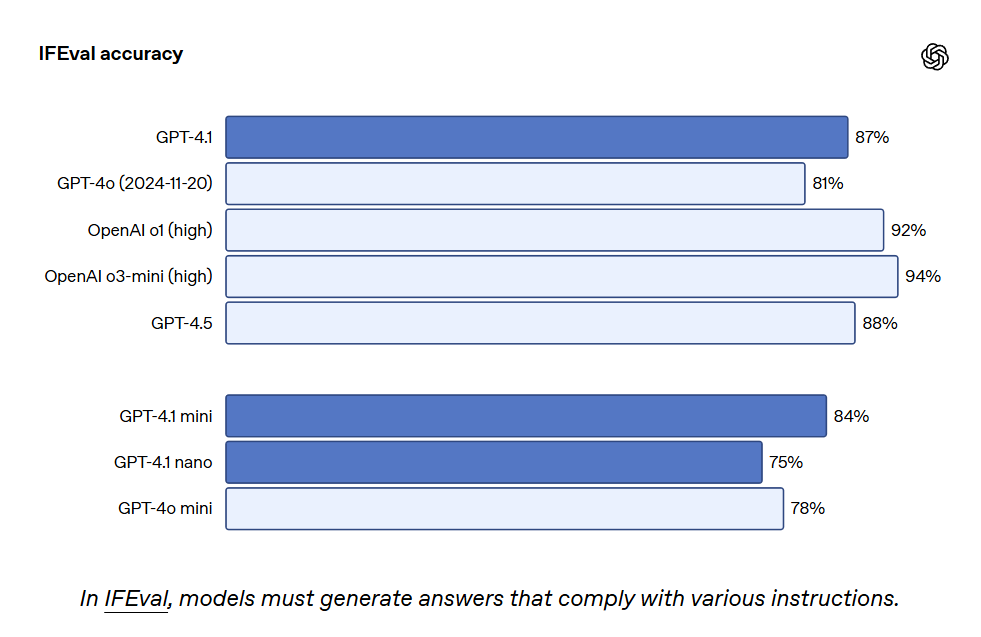
Better instruction-following capabilities make existing applications more reliable and support new applications that were previously limited by low reliability. Early testers noted that GPT – 4.1 can be more intuitive, so OpenAI recommends being more explicit and specific in prompts.
Long
GPT-4.1, GPT-4.1 mini, and GPT-4.1 nano can process up to 1 million context tokens, while the previous GPT-4o model could handle up to 128,000 tokens. One million tokens are equivalent to 8 complete React codebases, making long context particularly suitable for working with large codebases or extensive documents.
GPT-4.1 can reliably handle information with a context length of up to 1 million tokens and is more reliable than GPT-4o in focusing on relevant text and ignoring interference from long-context elements. Long-context understanding is a critical capability for applications in law, programming, customer support, and many other fields.
OpenAI has demonstrated the ability of GPT-4.1 to retrieve hidden “needle” information at various points within the context window. GPT-4.1 can consistently and accurately retrieve the needle across all positions and for all context lengths, with a maximum retrieval capacity of up to 1 million tokens. Regardless of the position of these tokens in the input, GPT-4.1 can effectively extract details relevant to the current task.
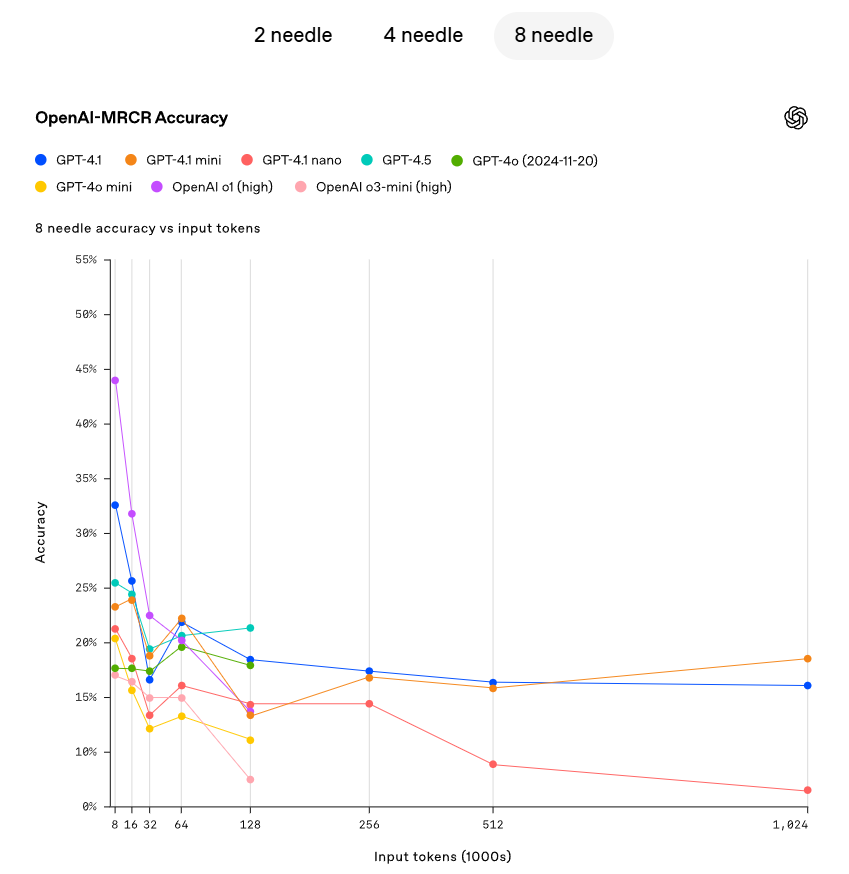
However, in the real world, few tasks are as simple as retrieving an obvious “needle” answer. OpenAI has found that users often need the model to retrieve and understand multiple pieces of information and comprehend the interrelationships among them. To demonstrate this capability, OpenAI has open-sourced a new evaluation: OpenAI-MRCR (Multi-Round Co-Reference).
The OpenAI-MRCR test model evaluates the ability to identify and eliminate multiple hidden “needles” in the context. The evaluation includes multi-turn synthetic conversations between users and assistants. The user asks the assistant to write an article on a certain topic, such as “Write a poem about tapirs” or “Write a blog post about rocks.” Then, two, four, or eight identical requests are inserted throughout the context. Finally, the model must retrieve the response corresponding to a specific instance (e.g., “Give me the third poem about tapirs”).
The challenge lies in the similarity between these requests and the rest of the context. The model can easily be misled by subtle differences, such as a short story about tapirs instead of a poem, or a poem about frogs instead of tapirs. OpenAI has found that GPT – 4.1 performs better than GPT – 4o when the context length is up to 128K tokens, and it can also maintain strong performance even when the length reaches up to 1 million tokens.
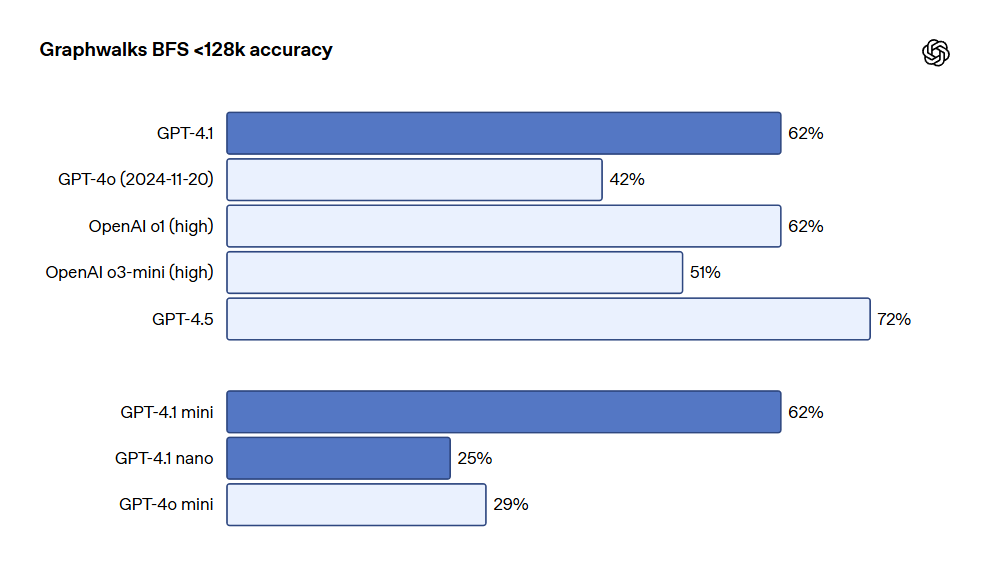
OpenAI has also released Graphwalks, a dataset for evaluating multi-hop long-context reasoning. Many developers need to make multiple logical jumps within the context in long-context use cases. For example, they may need to jump between multiple files when writing code or cross-reference documents when answering complex legal questions.
Theoretically, models (or even humans) can solve the OpenAI-MRCR problem by repeatedly reading the prompt. However, the design of Graphwalks requires reasoning at multiple positions in the context and cannot be solved sequentially.
Graphwalks fills the context window with a directed graph composed of hexadecimal hash values, then instructs the model to perform a breadth-first search (BFS) starting from a random node in the graph. It further requires the model to return all nodes up to a certain depth. The results show that GPT-4.1 achieved an accuracy rate of 61.7% on this benchmark test, which is comparable to the performance of o1 and easily surpasses GPT-4o.
visuals
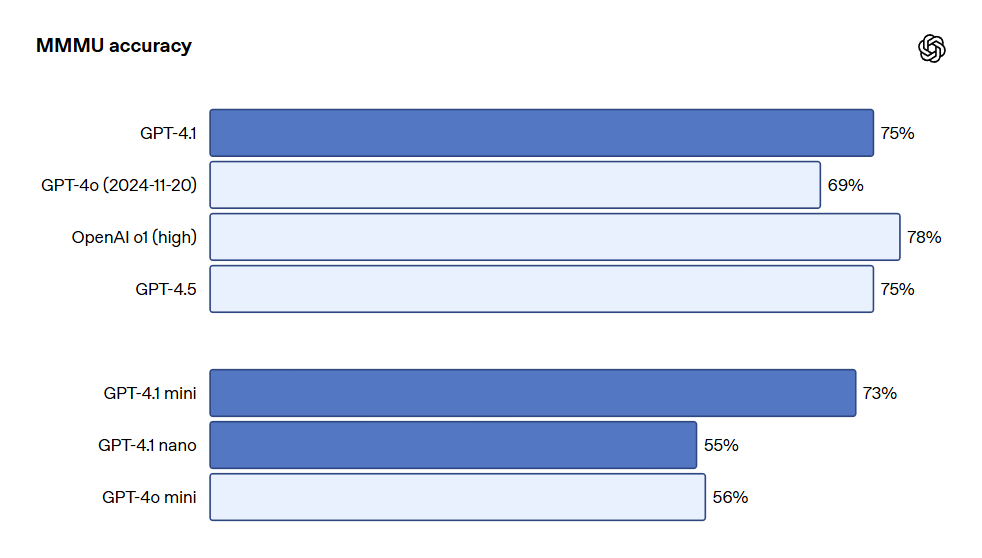
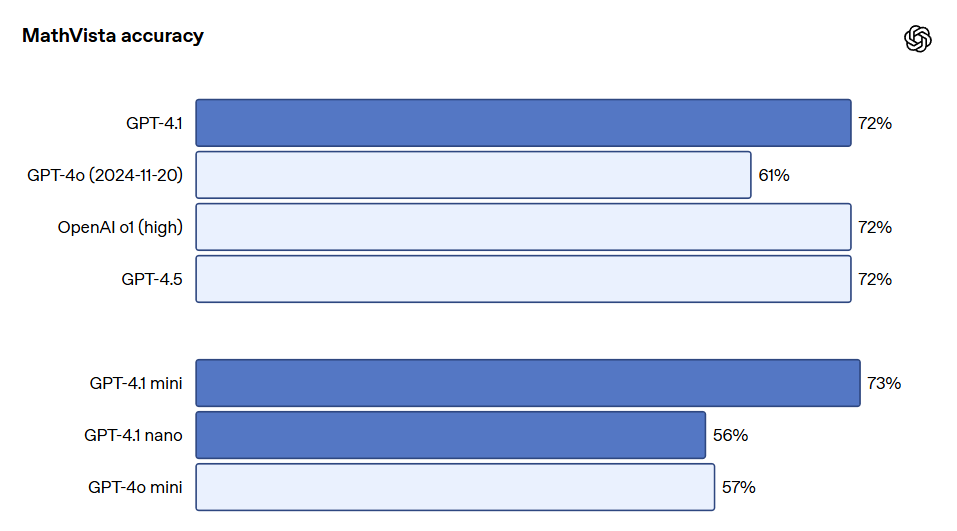
The GPT-4.1 series models are also very powerful in image understanding. In particular, GPT-4.1 mini has achieved a significant leap, often outperforming GPT-4o in image benchmark tests.
The following is a performance comparison on benchmarks such as MMMU (questions involving charts, diagrams, maps, etc.), MathVista (solving visual math problems), and CharXiv-Reasoning (answering questions about charts in scientific papers).
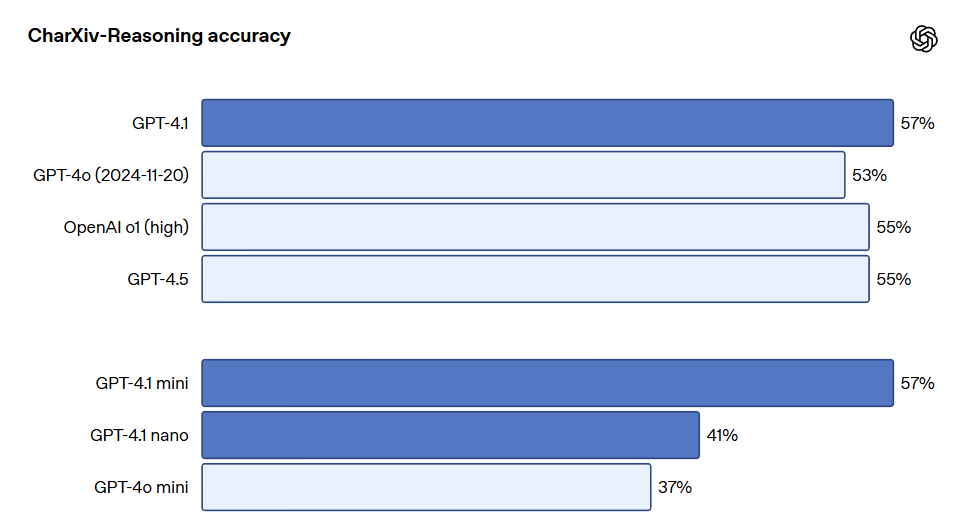
Long-context performance is also crucial for multimodal use cases, such as processing long videos. In Video-MME (long video without subtitles), the model answers multiple-choice questions based on unsupervised videos lasting 30 to 60 minutes. GPT-4.1 achieves the best performance, with a score of 72.0%, higher than that of GPT-4o at 65.3%.

For more testing metrics, please refer to the original OpenAI blog.
Blog URL: https://openai.com/index/gpt-4-1/
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...