Qwen3-VL Cookbooks is a collection of practical development guides released by Alibaba for the Qwen3-VL multimodal model, designed to help users quickly master and apply the model’s diverse capabilities. The collection includes a wide range of examples demonstrating abilities such as object recognition, document parsing, video understanding, spatial reasoning, and multimodal coding. Each cookbook provides detailed code samples and step-by-step instructions, enabling users to learn how to apply the Qwen3-VL model effectively in real-world scenarios and fully leverage its powerful vision-language capabilities.
Main Functions of Qwen3-VL Cookbooks
Comprehensive Operation Guides: Helps users quickly learn how to use the Qwen3-VL model for various multimodal tasks.
Demonstrates Multimodal Task Implementation: Offers practical examples on combining image, video, and text data for task completion.
Optimized Workflow Design: Provides efficient workflows and code examples to improve development and deployment efficiency.
Supports Diverse Application Scenarios: Covers a wide range of use cases—from object recognition to document parsing and video understanding—to meet various needs.
Performance Optimization Tips: Offers guidance for optimizing model performance according to task requirements, improving inference speed and efficiency.
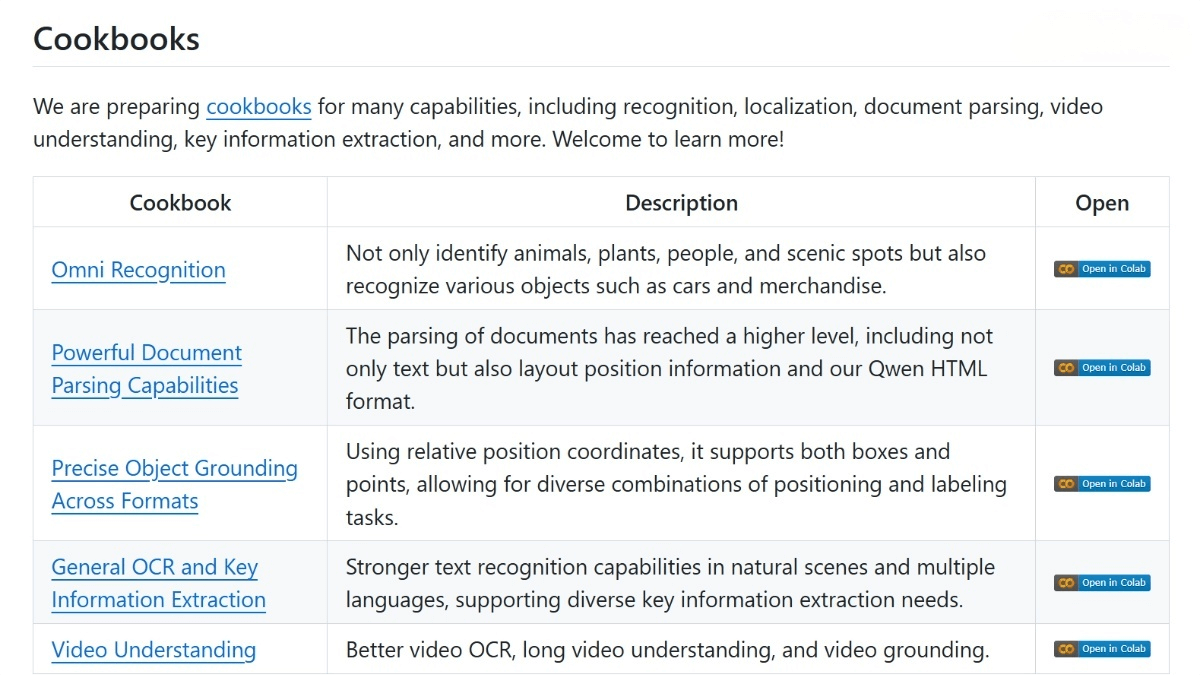
Contents of Qwen3-VL Cookbooks
Omni Recognition: Identifies various objects such as animals, plants, people, landmarks, and consumer goods.
Powerful Document Parsing Capabilities: Extracts text and layout information from documents, supporting the Qwen HTML format.
Precise Object Grounding Across Formats: Locates targets in images using relative coordinates, supporting both bounding boxes and point annotations.
General OCR and Key Information Extraction: Supports OCR in 32 languages, capable of reading text under low light, blurred, or tilted conditions.
Video Understanding: Performs video OCR and long-form video comprehension, enabling detailed video content analysis.
Mobile Agent: Uses visual reasoning and positioning to control smartphone operations.
Computer-Use Agent: Employs visual reasoning to control computer and web-based interactions.
3D Grounding: Provides accurate 3D bounding boxes for indoor and outdoor objects.
Thinking with Images: Enhances image reasoning through zooming and image search tools.
MultiModal Coding: Generates HTML, CSS, and JS code from image or video inputs.
Long Document Understanding: Enables semantic comprehension of ultra-long documents.
Spatial Understanding: Observes, interprets, and reasons about spatial relationships in images and scenes.
Object Recognition: Enhances smart security systems by quickly identifying suspicious individuals or objects in surveillance footage.
Document Parsing: In the financial industry, automatically extracts key clauses and data from contracts, improving audit efficiency.
Precise Object Grounding: In autonomous driving, accurately detects and localizes road signs and obstacles to ensure driving safety.
Multilingual OCR and Key Information Extraction: In intelligent customer service, reads and extracts key information from multilingual user documents to enhance service efficiency.
Video Understanding: In the education sector, automatically generates subtitles for online course videos, facilitating student learning.