
What is Seed-Coder
Seed-Coder is an open-source 8B-parameter code model series developed by ByteDance, aimed at enhancing code generation and understanding capabilities. It includes three versions—Base, Instruct, and Reasoning—designed respectively for code completion, instruction following, and complex reasoning tasks. The model adopts a “model-centric” data processing approach, using self-generated and curated high-quality data to reduce manual preprocessing workload. With a context length of up to 32K tokens, it leads in performance among open-source models of similar scale. Seed-Coder is released under a permissive MIT license, and the code is available on Hugging Face, making it accessible for developers and researchers.
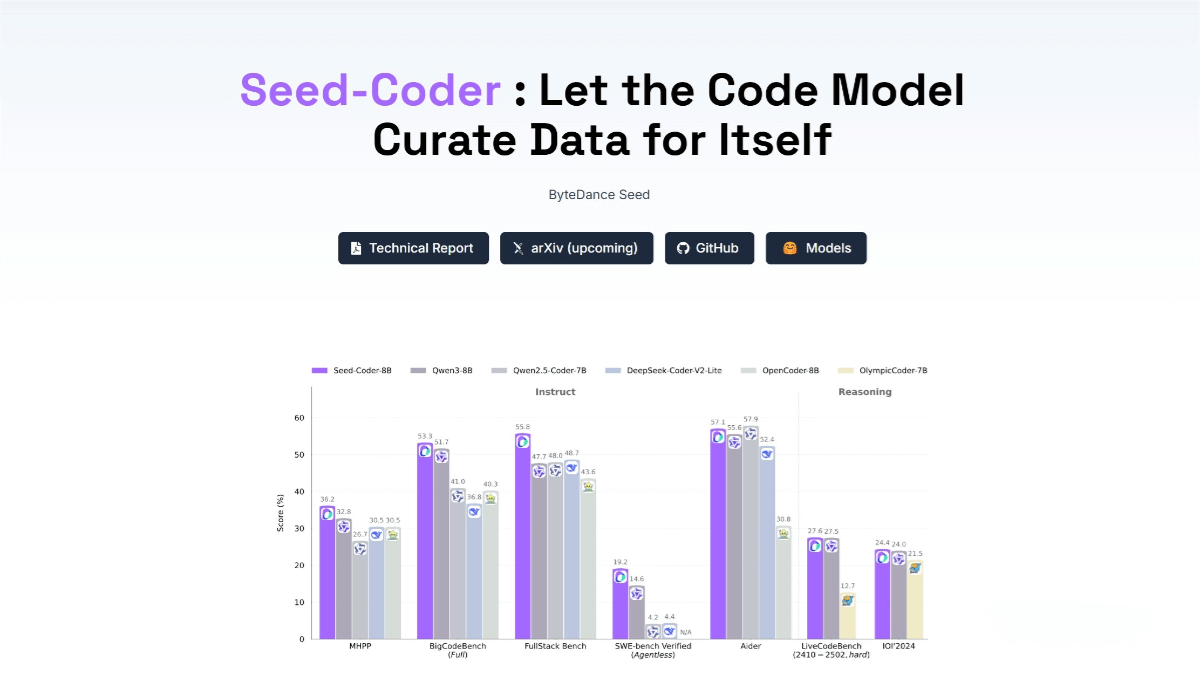
Key Features of Seed-Coder
-
Code Completion: The Base version of Seed-Coder can predict subsequent code based on partial inputs. For instance, when writing a function, it can automatically complete the parameters and the function body framework after receiving the function name and some parameters.
-
Code Infilling: For code snippets with missing parts (e.g., templates with placeholders), the model can generate suitable code to fill the gaps. For example, in a web development template, it can generate HTML rendering or backend logic based on context.
-
Code Comment Generation: Seed-Coder understands code functionality and generates meaningful comments, which improves readability and maintainability. It can describe key steps, inputs, and outputs of a complex algorithm.
-
Code Similarity Detection: It can assess whether two code snippets are logically similar, useful for detecting plagiarism or redundant code in software development.
-
Multi-Step Reasoning in Programming: The Reasoning version can handle complex programming problems like algorithm challenges or multi-step logic tasks, by generating intermediate reasoning steps and complete solutions.
-
Code Optimization Suggestions: With deep code comprehension, Seed-Coder can suggest optimizations for existing code, such as improving algorithm efficiency or optimizing data structure usage.
Technical Foundations of Seed-Coder
-
Llama 3-Based Architecture: Built on the Llama 3 structure with 8.2B parameters, Seed-Coder features 6 layers, a hidden size of 4096, and uses Grouped Query Attention (GQA).
-
Long Context Support: With support for 32K token input, it handles large-scale projects via repository-level code stitching.
-
Model-Centric Data Processing: A novel approach where the model itself curates and filters data.
Data Sources and Categories
-
File-Level Code: High-quality single-file code from GitHub.
-
Repository-Level Code: Maintains project structure to help the model learn inter-file relationships.
-
Commit Data: Includes commit messages, repo metadata, file diffs from 140K high-quality repositories, totaling 74 million commits.
-
Web-Sourced Code Data: Extracted from archived web pages containing code blocks or highly related documentation.
Preprocessing
-
Deduplication at file and repository levels using SHA256 hash and MinHash for fuzzy deduplication.
-
Syntax validation with parsers like Tree-sitter to filter out invalid code.
Quality Filtering
-
A scoring model trained on over 220K code documents (based on DeepSeek-V2-Chat) evaluates code readability, modularity, clarity, and reusability to filter low-quality data.
Training Methods
-
Standard Pretraining: Trained on file-level and web-sourced code to build foundational capabilities.
-
Continual Pretraining: Uses all four data types plus additional high-quality and long-context datasets for performance enhancement and alignment.
-
Fill-in-the-Middle (FIM) Training: Trains the model to complete missing code parts by splitting code into prefix, middle, and suffix.
-
Reasoning Ability Training: Uses Long Chain-of-Thought (LongCoT) reinforcement learning to guide the model in writing reasoning steps before generating final code.
Instruct and Reasoning Models
-
Instruct (-Instruct): Enhances instruction-following via Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO).
-
Reasoning (-Reasoning): Improves multi-step reasoning in complex coding tasks.
Project Links
-
Official Website: https://bytedance-seed-coder.github.io/
-
GitHub Repository: https://github.com/ByteDance-Seed/Seed-Coder
-
Hugging Face Model Library: https://huggingface.co/collections/ByteDance-Seed/seed-coder
Application Scenarios for Seed-Coder
-
Software Development: Assists in code generation and auto-completion to improve productivity.
-
Programming Education: Serves as a powerful assistant for students, offering feedback and helping explain programming concepts.
-
Bug Detection and Fixing: Detects errors in code and suggests fixes, reducing debugging time.
-
Development Efficiency in Enterprises: Enables faster code generation and optimization, accelerating development cycles and reducing project timelines.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts




No comments yet...