What is OmniAudio?
OmniAudio is a technology developed by Alibaba’s Tongyi Lab speech team that generates spatial audio (First-Order Ambisonics, or FOA) from 360° video, delivering a more realistic audio experience for virtual reality (VR) and immersive entertainment. To support model training, the team created Sphere360, a large-scale dataset containing over 103,000 video clips, covering 288 types of audio events, with a total duration of 288 hours. OmniAudio’s training process includes two stages: self-supervised coarse-to-fine flow-matching pretraining using large-scale non-spatial audio datasets, and supervised fine-tuning with dual-branch video representations to enhance sound source directionality.
Key Features of OmniAudio
-
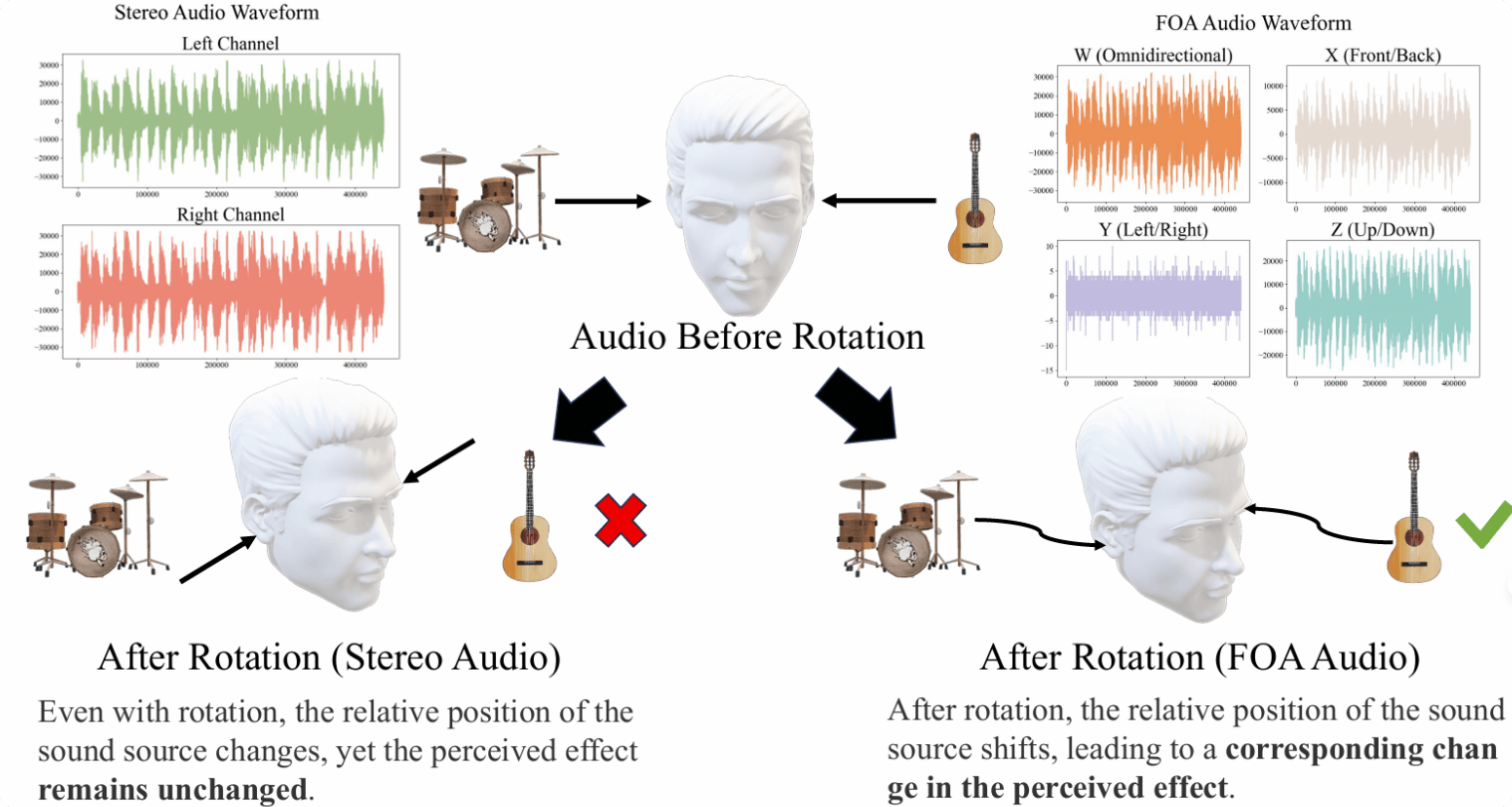
Spatial Audio Generation: Converts 360° video directly into FOA spatial audio, a 3D audio format that captures sound directionality for realistic 3D playback. It uses four channels—W, X, Y, and Z—where W captures overall sound pressure, and X, Y, Z represent front-back, left-right, and up-down directional cues. This ensures accurate sound localization even when the listener’s head moves.
-
Enhanced Immersive Experience: Solves the limitations of traditional video-to-audio methods that only generate non-spatial audio, making it ideal for applications requiring true 3D sound positioning in immersive environments.
Technical Overview of OmniAudio
Self-Supervised Coarse-to-Fine Flow Matching Pretraining
-
Data Preparation: Due to the scarcity of real FOA audio, the team leverages large-scale non-spatial datasets (e.g., FreeSound, AudioSet, VGGSound) to synthesize “pseudo-FOA” audio. Here, the W channel is the sum of stereo channels, the X channel is their difference, and Y/Z channels are set to zero.
-
Model Training: The pseudo-FOA is fed into a four-channel VAE encoder to obtain latent representations. A time-window masking strategy is applied with a certain probability, and the masked and unmasked sequences are input to a flow-matching model. By minimizing the difference in velocity fields before and after masking, the model learns general audio structures and time dynamics, laying the groundwork for precise spatial audio generation.
Supervised Fine-Tuning with Dual-Branch Video Representation
-
Data Usage: Real FOA audio data is used exclusively at this stage, with a similar masked flow-matching setup—but now focused entirely on learning spatial characteristics from the four channels.
-
Model Enhancement: Heavier masking on real FOA latent sequences strengthens the model’s ability to represent directional cues and inter-channel relationships, boosting spatial detail reconstruction.
-
Dual-Branch Integration: After pretraining, the model is combined with a dual-branch video encoder. For 360° video input, global features are extracted using a frozen MetaCLIP-Huge image encoder. Field-of-view (FOV) local views are also processed to capture detailed visual features. Global features are used as Transformer conditions, while local features, after temporal upsampling, are added element-wise to the audio latent sequence for step-wise guidance.
-
Fine-Tuning and Output: The model is fine-tuned efficiently while preserving the pretrained parameter structure. During inference, the trained velocity field is sampled, and the VAE decoder reconstructs waveforms to produce four-channel spatial audio that is precisely aligned with the 360° video input.
Project Links
-
Official Website: https://omniaudio-360v2sa.github.io/
-
GitHub Repository: https://github.com/liuhuadai/OmniAudio
-
arXiv Paper: https://arxiv.org/pdf/2504.14906
Use Cases for OmniAudio
-
Virtual Reality (VR) & Immersive Experiences: Generates spatial audio that aligns perfectly with visual content, greatly enhancing immersion.
-
360° Video Soundtracks: Automatically produces immersive audio for panoramic videos, delivering a more lifelike listening experience.
-
Smart Voice Assistants: Can be integrated into smart home devices such as smart speakers and appliances for accurate voice command processing and interaction.
-
Robotics & Autonomous Driving: Enhances sound localization and environmental awareness for robots and autonomous vehicles.