SAIL-VL2 – A Visual-Language Model Open-Sourced by ByteDance, TikTok, and the National University of Singapore
What is SAIL-VL2?
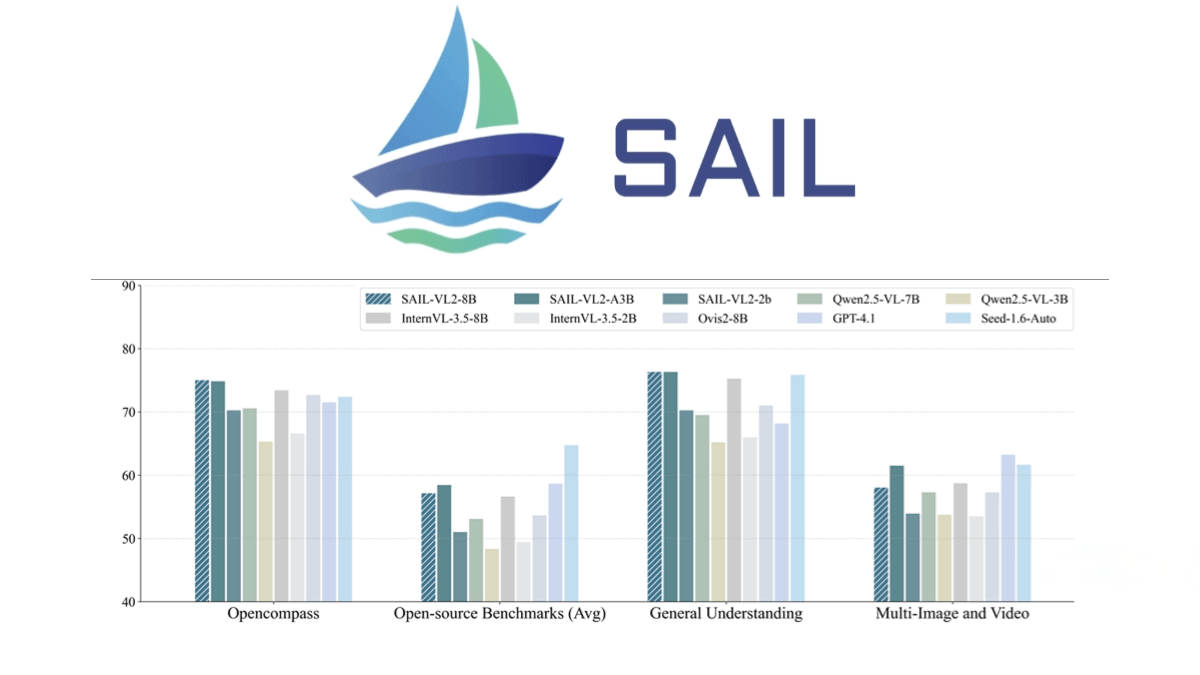
SAIL-VL2 is an open-source foundational visual-language model jointly developed by the TikTok team and the National University of Singapore, focusing on multimodal understanding and reasoning. It consists of the visual encoder SAIL-ViT, a vision-language adapter, and a large language model (LLM). Using a progressive training framework—from visual pretraining to multimodal fusion, and finally optimized with an SFT-RL hybrid paradigm—SAIL-VL2 achieves strong performance. The model also incorporates a Mixture-of-Experts (MoE) architecture, breaking the limits of traditional dense models and significantly improving efficiency and performance.
SAIL-VL2 – Key Features
-
Multimodal Understanding: Capable of handling tasks combining images and text, such as image captioning and visual question answering (VQA), accurately interpreting visual content and generating corresponding language outputs.
-
Visual Reasoning: Offers strong logical reasoning capabilities to analyze complex scenes in images, such as determining object relationships or event logic.
-
Cross-Modal Generation: Supports generating images from text or generating text from images, enabling effective conversion between vision and language.
-
Large-Scale Data Processing: Optimized data pipelines efficiently handle massive multimodal datasets, improving training efficiency and model performance.
-
Efficient Training Architecture: Uses a progressive training framework and Mixture-of-Experts (MoE) architecture, overcoming traditional model limitations and significantly boosting training efficiency and scalability.
-
Multi-Task Learning: Supports diverse multimodal tasks such as captioning, OCR recognition, and video understanding, providing wide applicability.
-
Open-Source and Extensible: As an open-source model, SAIL-VL2 offers flexibility for researchers and developers to extend and customize it, advancing multimodal technology development.
SAIL-VL2 – Technical Principles
-
Visual Encoder SAIL-ViT: Based on the Vision Transformer architecture, it efficiently encodes images, extracting key features and semantic information to provide a strong visual foundation for downstream multimodal tasks.
-
Vision-Language Adapter: A lightweight two-layer neural network converts visual features from the encoder into a format understandable by the language model, enabling effective alignment between vision and language.
-
Large Language Model: Supports both traditional dense models and advanced Mixture-of-Experts (MoE) architectures, capable of complex language generation and reasoning while improving computational efficiency and scalability.
-
Progressive Training Framework: Begins with visual encoder pretraining, gradually transitions to multimodal pretraining, and finally applies supervised fine-tuning (SFT) and reinforcement learning (RL) hybrid optimization to systematically enhance performance.
-
Large-Scale Data Processing Pipeline: Uses scoring and filtering strategies to optimize data quality and distribution across various multimodal types, including captioning, OCR, Q&A, and video data, ensuring robust performance across diverse tasks.
-
Mixture-of-Experts (MoE) Architecture: Breaks the limits of traditional dense LLMs by activating only a subset of parameters while maintaining high performance, greatly improving computational efficiency and scalability.
-
Multimodal Task Adaptation: Flexible adapters and training strategies enable SAIL-VL2 to handle a variety of tasks such as image captioning, visual question answering, and video understanding, demonstrating strong generality and adaptability.
SAIL-VL2 – Project Links
-
GitHub Repository: https://github.com/BytedanceDouyinContent/SAIL-VL2
-
Hugging Face Model Hub: https://huggingface.co/BytedanceDouyinContent
-
arXiv Paper: https://arxiv.org/pdf/2509.14033
SAIL-VL2 – Application Scenarios
-
Image Captioning: Automatically generates accurate and natural descriptions from input images, suitable for image annotation, content recommendation, and similar applications.
-
Visual Question Answering (VQA): Understands image content and answers questions related to the image, widely applicable in intelligent customer service, educational assistance, etc.
-
Multimodal Content Creation: Supports generating images from text or text from images, helping creators rapidly produce creative content such as advertisements or storytelling.
-
Video Understanding and Analysis: Processes video data, extracts key frames, and generates summaries or descriptions, useful for video recommendation, monitoring, and analysis.
-
Intelligent Search: Combines image and text information to provide more accurate search results, enhancing user experience in e-commerce and content retrieval.
-
Educational Assistance: Integrates images and text to help students better understand complex concepts and scenarios, applicable in online education and multimedia teaching.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...