
What Is SAM 3?
SAM 3 (Segment Anything Model 3) is Meta AI’s latest advanced computer vision model capable of detecting, segmenting, and tracking objects in images and videos using text, examples, and visual prompts. The model supports open-vocabulary phrase inputs and offers powerful cross-modal interaction, enabling real-time refinement of segmentation results. SAM 3 delivers exceptional performance on image and video segmentation tasks—twice that of existing systems—and supports zero-shot learning. It also expands into the field of 3D reconstruction, powering applications such as home-setup previews, creative video editing, and scientific research, providing strong momentum for the future of computer vision.
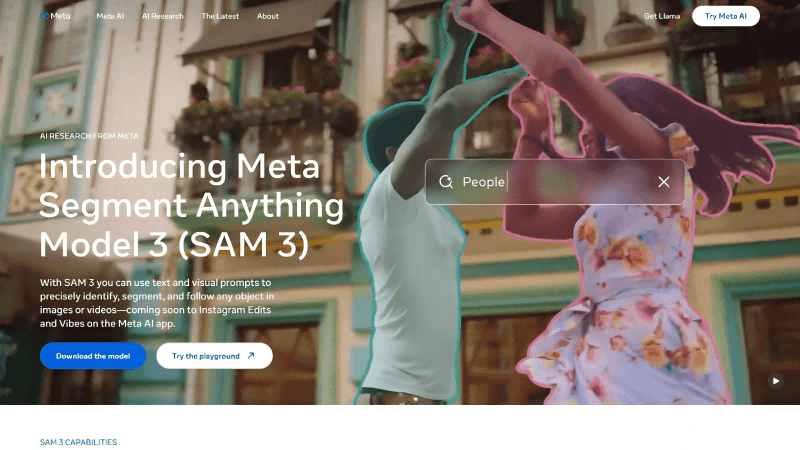
Key Features of SAM 3
1. Multimodal Prompting
SAM 3 can detect and segment objects in images and videos using text, example images, and visual prompts such as clicks or bounding boxes, adapting to various user needs.
2. Image and Video Segmentation
It can detect and segment all matching objects in images and track objects across video frames, with support for real-time interactive refinement.
3. Zero-Shot Learning
SAM 3 handles unseen concepts via open-vocabulary text prompts, enabling segmentation of new object categories without additional training.
4. Real-Time Interactivity
Users can refine results by adding extra prompts (such as clicks or boxes), correcting model errors and improving the segmentation quality.
5. Cross-Domain Applications
SAM 3 is widely used in creative media tools (e.g., Instagram Edits), home-decoration previews (e.g., Facebook Marketplace), and scientific fields such as wildlife monitoring.
How SAM 3 Works
Unified Model Architecture
SAM 3 is built on a unified architecture that supports both image and video segmentation. It combines a powerful visual encoder (such as the Meta Perception Encoder) with a text encoder to process open-vocabulary prompts.
The model includes:
-
an image-level detector
-
a memory-based video tracker
Both share the same visual encoder.
Multimodal Input Processing
-
Text Encoder: Converts text prompts into feature vectors that guide segmentation.
-
Visual Encoder: Encodes images or video frames into visual features for object detection and segmentation.
-
Fusion Encoder: Merges text and visual features to produce conditioned image features for segmentation tasks.
Presence Head
To improve classification performance, SAM 3 introduces a Presence Head that predicts whether the target concept exists in the image or video. This helps decouple recognition and localization, enhancing accuracy and efficiency.
Large-Scale Data Engine
Meta built a high-efficiency data engine that combines human annotations with AI-assisted labeling, producing high-quality annotations for over 4 million unique concepts. This diverse data coverage ensures strong generalization across visual domains and tasks.
Zero-Shot Learning
Leveraging pre-trained visual and language encoders, SAM 3 can identify and segment new object categories from open-vocabulary text prompts without additional training.
Real-Time Interactivity
Users can refine segmentation results by adding prompts like clicks or box selections. This interactive loop helps the model better align with user intent.
Video Tracking and Segmentation
For video tasks, SAM 3 uses a memory-based tracker to maintain spatiotemporal consistency. The tracker uses detection outputs and historical memory to generate high-quality masks and propagate them across frames.
Project Links
-
Official Website: https://ai.meta.com/sam3/
-
GitHub Repository: https://github.com/facebookresearch/sam3/
-
Online Demo: https://www.aidemos.meta.com/segment-anything
Application Scenarios
1. Creative Media Tools
Creators can quickly apply visual effects to people or objects in videos, improving production efficiency.
2. Home Decoration Preview
On Facebook Marketplace, SAM 3 powers “Room Preview,” allowing users to visualize how furniture or décor would look in their own spaces.
3. Scientific Applications
SAM 3 supports wildlife monitoring and ocean research, helping scientists analyze animal behaviors through video.
4. 3D Reconstruction
SAM 3D can reconstruct 3D objects or humans from a single image, setting a new standard for real-world 3D reconstruction and assisting VR/AR applications.
5. Video Creation
SAM 3 enables AI-powered visual creation tools, supporting remixing and editing of AI-generated videos to enhance creative flexibility.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...