The all-out war in the field of AI begins with AI crawlers destroying the Internet.
I recently came across a very interesting development. Cloudflare is luring web crawlers into an “AI maze,” which essentially means that instead of blocking web crawlers, Cloudflare is inviting them to wander aimlessly in a useless network of “AI-generated nonsense.”
For the first time, one of the world’s largest internet infrastructure companies, Cloudflare, is turning to the strategy of “fighting fire with fire” by using AI to combat AI-driven crawlers.
The significance of this move is so profound that it could very well be worthy of a place in the annals of AI history.
This marks the beginning of an all-out war in the realm of AI.
You might still have many questions at this point: What is Cloudflare? What are AI crawlers? What is an AI maze? And why is this whole thing so interesting?
To begin with all of this, I’d like to tell you a story first.
It’s a story that took place in January this year, in a Ukrainian company with only seven employees.
This company is called Triplegangers, and what it does is really simple: selling 3D digital models of people.

Triplegangers focuses on selling model materials of “digital twins of the human body”. These high-definition 3D model photos are derived from real human scans, with great value.
The founder, Tomchuk, has always been satisfied. Although the company is not large, it is his favorite thing to do.
On this website, there are a total of 65,000 product pages. Each product page has at least three high-definition photos. Each photo is carefully labeled with age, skin color, tattoos, and even scars.

However, on an ordinary Saturday morning, the peace was suddenly shattered by a storm.
Tomchuk received an urgent notice: the company’s website had crashed due to a massive DDoS attack.
He was completely baffled. Since he didn’t have any enemies in general, nor any competitors, and he just minded his own business, who on earth would launch an attack on him for no reason?
He panicked and began to investigate the cause. Soon, he discovered that it was OpenAI’s web crawler robot, GPTBot, that was attacking his website.
GPTBot frantically crawled every page. Hundreds of thousands of photos and descriptions were mercilessly downloaded in just a few hours. These web crawler robots used as many as 600 IP addresses, generating tens of thousands of server requests. The website had never witnessed such a situation before. Its server instantly went down, and the business came to a halt.

The Tomchuk team was completely stunned. Not only did they lose all their own data, which was scraped clean by OpenAI, but worse still, due to the soaring server pressure, the company will also face a huge AWS bill.
This seven-person team spent ten years of painstaking effort building this massive database, with clients spanning multiple industries such as game development and animation production.
And now, it’s all gone.
What’s even more frustrating is that they had clearly prohibited web crawlers from accessing website data without permission.
However, because they didn’t have a deep understanding of AI and weren’t quite familiar with the practices of major AI model companies, they didn’t strictly configure the robot.txt file or add the tag specifically instructing OpenAI’s GPTBot not to access the website. This essentially amounted to tacitly allowing OpenAI’s scraping behavior.
The key issue is that even configuring the GPTBot tag wasn’t enough. Because OpenAI also has ChatGPT-User and OAI-SearchBot, and tags for these two need to be configured as well. You might not even know what other tags are required.
“We originally thought that the prohibition clauses would be sufficient, but unexpectedly, we also had to specifically establish rules to reject robots.”
A few days later, Tomchuk finally configured the robot.txt file for Triplegangers and enabled the Cloudflare service to block more crawlers.
Cloudflare might not be familiar to everyone, but most people have probably come across it.
Just this thing, which requires you to verify whether you are human before accessing certain websites.
However, this thing isn’t free either. It’s quite costly, all about expenses. But in order to prevent another round of “rogue behavior” like that of OpenAI, they had no choice but to enable it.
The cost of these services is manageable, but what pains Tomchuk the most is that he has no idea how much material OpenAI has actually taken.
And Tomchuk said:
“We can’t even get in touch with OpenAI, nor can we ask them to delete the data they have scraped.”
The most absurd part is that if OpenAI weren’t so greedy and didn’t make too many requests at once, directly crashing Triplegangers, but instead crawled slowly, bit by bit…
Tomchuk may never even realize that all of his data has been completely lost.
OpenAI’s crawling logic is very simple: if there is no security guard standing at your door, it means you implicitly allow me to take anything from your house—it all belongs to me. Since you didn’t say I couldn’t take it and didn’t set up a security guard, I can just walk in and loot everything clean.
This is a war.
A war without gunpowder.A war concerning the inviolability of protecting one’s own property.
A war that concerns us and the AI crawlers of these AI companies.
The plight of Trilegangers is not an isolated case.
In the eyes of many companies and content creators, AI crawlers are like digital locusts in this era. Wherever they go, websites are overwhelmed, and their data is plundered clean.
Last summer, there was also a well-known example from iFixit, a very established repair tutorial website.
iFixit discovered that their website had also become a target for AI crawlers.
This time, however, the culprit with the bad manners wasn’t OpenAI, but another AI powerhouse—Anthropic’s crawler, ClaudeBot.
The CEO of iFixit was furious and took to social media to expose the issue:
In just 24 hours, ClaudeBot had made nearly one million requests to iFixit’s site, nearly crashing it and triggering all their alarm systems. This forced iFixit’s operations team to work overtime through the night to deal with the situation.
What’s even more outrageous is that iFixit had explicitly prohibited unauthorized scraping of their content for AI training. This rule was clearly stated in their website’s terms of use, with a specific note saying, *”Do not use the content of this website for machine learning or AI model training.”*
Despite this, Anthropic’s crawler clearly didn’t care about these warnings and continued to scrape data recklessly.
What’s even more frustrating is that after this incident blew up, some media reached out to Anthropic, and the response they got was almost identical to that of OpenAI:
They stated that ClaudeBot’s crawler complies with the robots.txt protocol. If a website does not want to be crawled, it should block Claude in the robots file.
In other words, they implied that iFixit itself didn’t explicitly prohibit it. Since you didn’t completely ban ClaudeBot in the robots.txt, of course, we have the right to keep crawling.
Left with no choice, iFixit hurriedly updated its robots.txt, adding delay and blocking rules specifically targeting ClaudeBot.
However, the shockwaves this incident left in the industry have yet to subside. To be frank, even a well-known website like iFixit, which is familiar with web technologies, initially underestimated how “unethical” AI crawlers could be—blatantly pushing through despite clear reluctance from the site owner.
If even veteran Internet practitioners can hardly guard against them, then how can those small websites and small authors without technical teams to defend them fend off these thieves?
What’s even more shameless is that AI search pioneer, Perplexity.
The well-known tech media outlet *Wired* has discovered that Perplexity’s web crawlers not only fail to comply with the robots.txt restrictions of some websites but even attempt to stealthily scrape areas that are explicitly declared off-limits to machines.
In other words, Perplexity is blatantly ignoring the robots protocol and secretly harvesting content it shouldn’t have access to.
You might be wondering at this point: what exactly is the robots protocol?
Let’s rewind to 1994, when the internet was also grappling with a “crawler chaos.” Back then, search engines were just emerging, and some automated crawler programs were running amok across the web, placing a significant burden on servers.
So, a Dutch engineer named Martijn Koster came up with a very clever idea:
Website administrators can place a text file named “robots.txt” in the root directory of the site to inform web robots in advance where they can crawl and what areas are off-limits.
This proposal was quickly widely accepted by the industry and became a very pure “gentlemen’s agreement” in the early days of the internet.
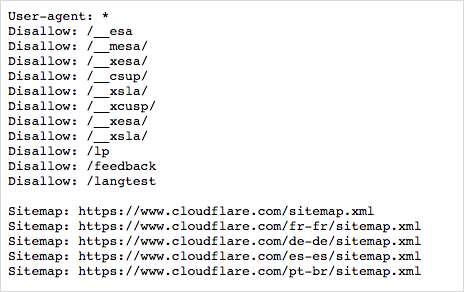
According to the robots protocol, if a website specifies certain content as off-limits in its robots.txt file, well-behaved crawlers should dutifully stop and refrain from accessing the blacklisted paths.
This mechanism essentially relies entirely on voluntary compliance. It has no legal enforcement power and depends on the conscience and goodwill of crawler developers to follow the rules.
Fortunately, over a considerable period of time, this sincerity has been largely maintained.
Search engines such as Google and Yahoo have respected the boundaries of robots.txt, and so has Microsoft’s Bing. Even later, a variety of well-intentioned web crawlers have taken it as part of their professional ethics not to harm websites and follow the webmasters’ wishes.
Thanks to the existence of robots.txt, web administrators are willing to open their doors and let search engines index their content. They believe that sensitive areas or parts they don’t want to make public can be politely avoided.
This trust has laid the foundation for the free circulation and fair use of online content. However, now this hard-won trust is being ruthlessly undermined.
When AI crawlers are out there scavenging everywhere to meet the data needs of their models, how many of them truly respect the boundaries set by robots.txt?
OpenAI and Anthropic may claim time and again that they abide by the robots protocol, but the reality is that if you don’t explicitly write a prohibition, they assume they can take it by default, without any regard for whether you’re willing or not.
As long as you don’t have a strong enough wall to keep me out, it’s your fault. It’s only reasonable for me to break in.
This kind of “blame-the-victim” logic not only arouses indignation but also reveals a touch of sadness.
Therefore, against this backdrop, Cloudflare has stepped forward as the guardian in front of most websites. They decided to fight fire with fire and combat AI with AI.
They built an entire AI maze for these AI crawlers.
The reason is that past defense mechanisms were quite simple: they relied on verification methods to directly block these AI crawlers at the door. However, this approach had a problem—it would alert the adversaries, prompting them to change their disguises and come back stronger.
For example, OpenAI has N AI crawlers.
So, in their latest update, they adopted a more subtle approach:
Let the opponent in, but lead it into a meticulously crafted maze of fake web pages.
In this maze, all the pages, links, and content are automatically generated by AI. They look quite authentic on the surface, yet they are nothing but meaningless feints, like the Trojan Horse stratagem.
Once those AI crawlers are lured in, they will wander around aimlessly in the fake content, wasting computing resources and bandwidth in vain.
The entrances to these mazes are invisible to normal users. Real visitors would never click on those trap links.
However, the AI crawlers tirelessly keep following the links, getting deeper and deeper until they lose their way in the quagmire of false information.
Finally, David has also obtained a weapon to fight against Goliath.
ClaudeBot wrote in their blog:
What’s next?
This is just our first iteration of using generative artificial intelligence to stop bots. Currently, although the content we generate looks very human-like, it doesn’t conform to the existing structure of every website. In the future, we will continue to work hard to make these links harder to detect and integrate them seamlessly into the existing structure of the websites where they are embedded. You can help us by opting in now.
To take the next step in the fight against bots, opt in to AI Maze today.
This is a war. On one side is an army of AI crawlers, ravenous and relentless in their hunt for data. On the other side are website owners and content creators, desperately defending their digital territories.
I do not deny that large models require vast amounts of data for training, and innovation often involves collisions with existing rules.
Similar conflicts are not new in the history of the internet: the music industry once clashed fiercely with digital piracy, and news publishers protested against search engines indexing their content.
Perhaps, in the eyes of many AI companies, publicly available content on the internet is a harmless resource, free to be taken and used without consequence. Why not harvest it?
But have you ever thought about the feelings of content creators?
If the source of knowledge and creativity is not respected or rewarded, what will ultimately wither away is innovation itself. No one is willing to toil and sweat, only to have their efforts stolen by machines without a second thought.
At least under the current ethical and economic systems, such behavior will dampen the enthusiasm of creators.
In the end, what remains on the internet will be nothing but AI-generated junk, overwhelming the entire web.
The war has already begun, and this battle in the field of AI starts with web crawlers.
All I hope is that when the smoke clears, we will still have an internet that we love—an open and trustworthy one.
Putting aside those grand technological narratives, for each of us as ordinary netizens,
this is what we should truly fight to protect.
Isn’t it?
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...