Piece it Together – An Image Generation Framework Launched by Bria AI and Other Organizations
What is “Piece it Together”?
Piece it Together (PiT) is an innovative image generation framework introduced by institutions such as Bria AI, specifically designed to generate complete conceptual images from partial visual components. Leveraging domain-specific prior knowledge, it seamlessly integrates fragmented visual elements provided by users into a coherent whole, intelligently supplementing missing parts to produce complete and creative conceptual images. Piece it Together is based on the IP+ space of IP-Adapter+, where it trains a lightweight flow-matching model, IP-Prior, to achieve high-quality reconstruction and semantic manipulation. Utilizing a LoRA fine-tuning strategy, Piece it Together significantly enhances text adherence, better adapting to various scenarios and providing robust support for creative design and conceptual exploration.
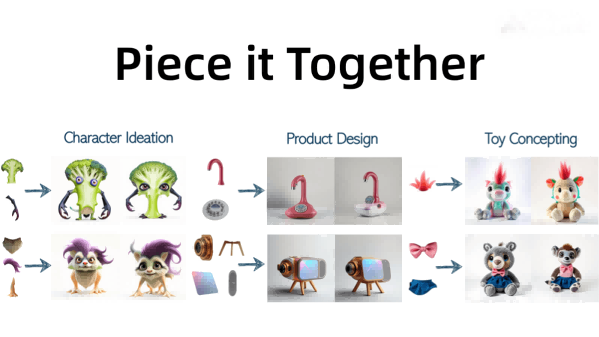
The main functions of Piece it Together
- Fragmented Visual Element Integration: Seamlessly integrate user-provided visual components (such as a unique wing, a specific hairstyle, etc.) into a coherent overall composition to generate a complete conceptual image.
- Missing Part Supplement: While integrating existing visual elements, automatically supplement and generate the missing parts.
- Diverse Concept Generation: Generate multiple different conceptual variations for the same set of input elements.
- Semantic Operation and Editing: Support semantic operations within the IP+ space, allowing users to further edit and adjust the generated concepts.
- Text Prompt Restoration: Support the restoration of text prompt adherence, placing the generated concepts in specific scenes or backgrounds to enhance the diversity and applicability of the generated images.
The Technical Principle of “Piece it Together”
- IP+ Space: The internal representation space (IP+ Space) based on IP-Adapter+ outperforms the traditional CLIP space in preserving complex concepts and details. It supports semantic operations, providing a foundation for high-quality image reconstruction and concept editing.
- IP-Prior Model: Train a lightweight flow-matching model, IP-Prior, which leverages domain-specific prior knowledge to generate complete conceptual images from partially provided visual components. By learning the distribution of the target domain, the model dynamically adapts to user inputs and completes the missing parts.
- Data Generation and Training: Generate training data using pre-trained text-to-image models such as FLUX-Schnell, enhancing data diversity by adding random adjectives and categories. Extract semantic parts of the target images using segmentation methods to form input pairs, and train the IP-Prior model to address the target task.
- LoRA Fine-Tuning Strategy: Adopt a LoRA-based fine-tuning strategy to address the limitations of IP-Adapter+ in text adherence. Fine-tune a LoRA adapter with a small number of samples to restore text control capabilities, ensuring that the generated concepts better follow the text prompts while maintaining visual fidelity.
Project address of Piece it Together
- Project official website: https://eladrich.github.io/PiT/
- GitHub repository: https://github.com/eladrich/PiT
- arXiv technical paper: https://arxiv.org/pdf/2503.10365
Application scenarios of Piece it Together
- Role Design: Quickly generate complete character designs for fantasy creatures, sci-fi characters, etc., and explore different creative directions.
- Product Design: Provide product components, generate complete concept art, validate design ideas, and explore diverse designs.
- Toy Design: Input some toy elements to inspire creativity and generate multiple toy concepts for market testing.
- Art Creation: Provide artistic elements to generate complete works, explore different styles, and inspire creative inspiration.
- Education and Training: Used in design and art teaching to quickly generate creative concepts, cultivate innovative thinking, and improve design skills.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...